Your domain authority is solid. Your keyword rankings hold. But none of that tells you whether Perplexity is recommending your competitor instead of you.
That’s the gap most SEO teams discover too late. A brand can rank first on Google for “best customer data platform” and still be completely absent from the synthesized answer ChatGPT delivers for the same query. These are two different systems operating on two different logics. And closing the second gap requires a different kind of tool: a GEO Agent.
GEO Isn’t SEO. The Rules Changed When AI Did.
Traditional search engines are librarians. They point users toward resources. Generative AI platforms are something else entirely: they’re synthesizers. They read across hundreds of sources and write a single answer. No list of blue links. No referral click.
This architecture, known as Retrieval-Augmented Generation (RAG), changes the core objective for brands. In SEO, you signal relevance to a crawler so you rank high. In GEO, you increase the probability that an AI model extracts and cites your brand in its response. If your content isn’t structured for LLM extraction, or if your brand entity isn’t clearly defined across the web, the model skips you. It cites whoever is easier to parse.
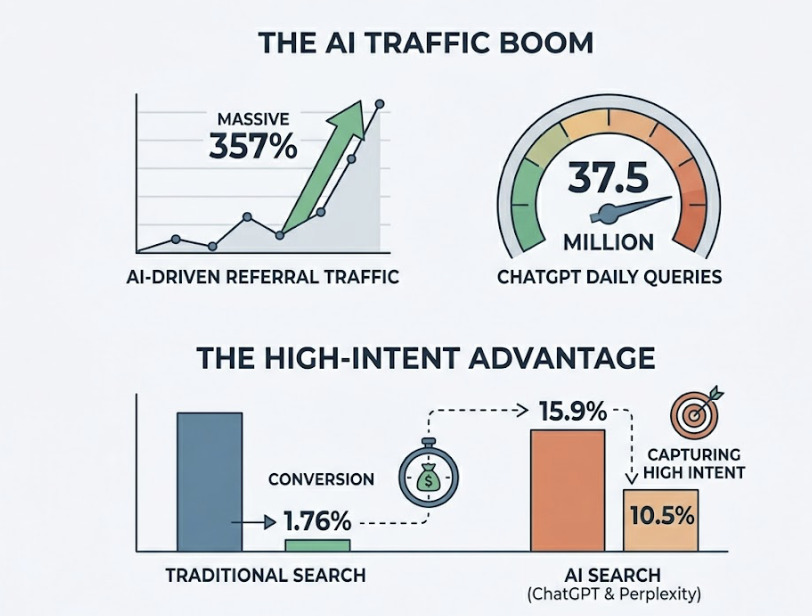
The traffic data makes the stakes clear. ChatGPT alone handles roughly 37.5 million queries per day, and AI-driven referral traffic has grown at approximately 357% year-over-year. More telling: traditional search carries a conversion rate of about 1.76%, while ChatGPT-referred traffic converts at 15.9% and Perplexity at 10.5%. AI search isn’t capturing the most volume. It’s capturing the highest-intent traffic.
That is the market GEO Agent is built for.
What’s a GEO Agent, Exactly?
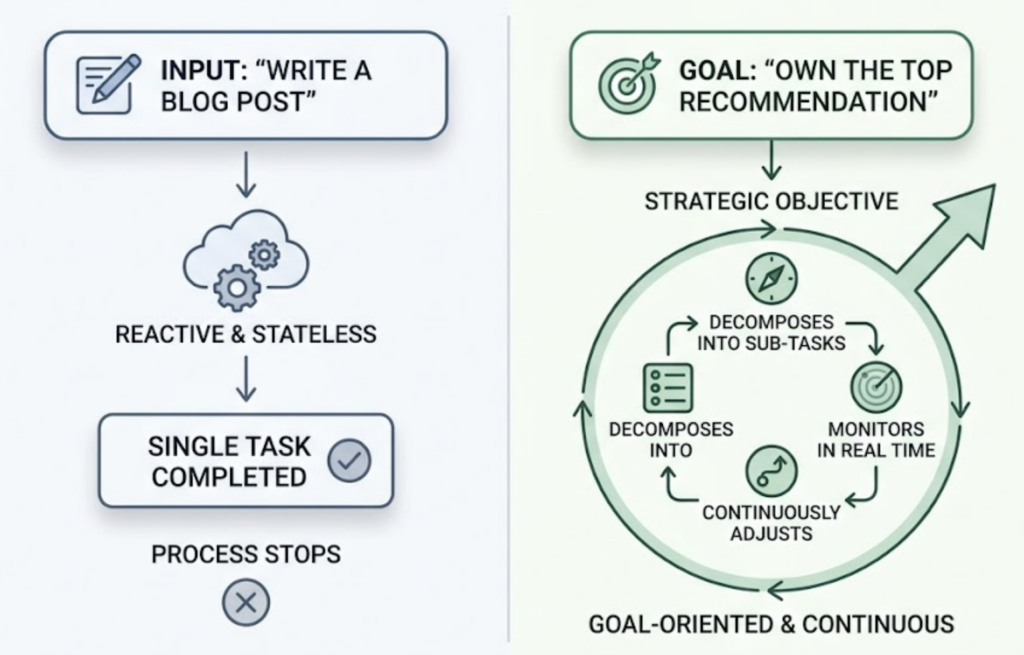
A GEO Agent is a system built on Agentic AI principles: it doesn’t wait for a human to issue a command. It pursues a goal.
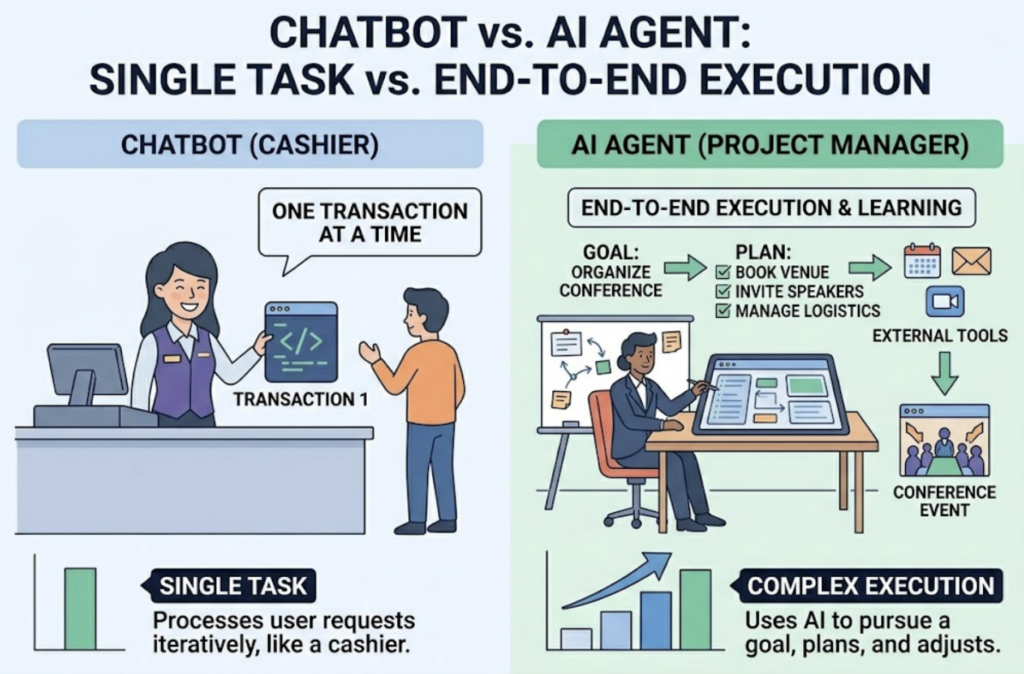
Give a standard GEO tool a task and it returns a report. You still have to read the data, diagnose the problem, write the fix, and deploy it. That’s three or four manual steps between insight and outcome. A GEO Agent collapses all of them. Tell it “achieve 50% visibility for ‘premium coffee beans’ across US AI platforms,” and it figures out what needs to change and handles it.
The distinction is more than operational. It’s architectural. A regular AI tool is reactive — it responds to prompts. Agentic AI is goal-oriented and proactive. It can break a high-level objective into sub-tasks, coordinate actions across different systems, and close the loop without waiting on a human to stitch the pieces together. Think of the difference between a GPS and an autonomous vehicle. Both know where you need to go. Only one drives.
The 3 Things a GEO Agent Actually Does
The operational logic of a GEO Agent runs in a continuous loop: Monitor → Reason → Act.
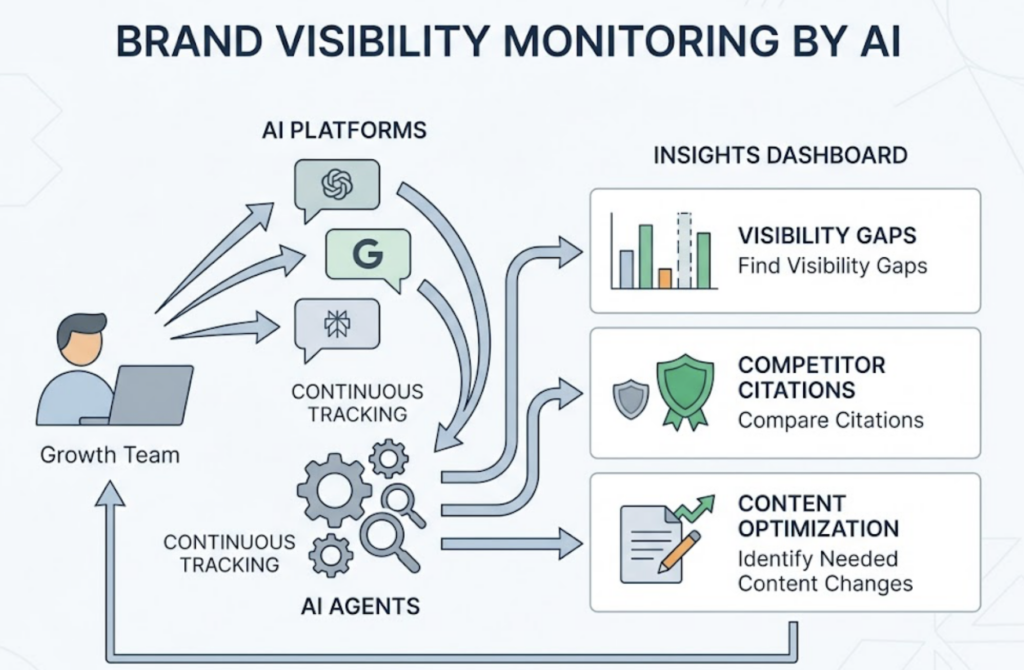
Monitor is deeper than tracking a single ranking. Because generative AI responses are probabilistic — the same prompt can produce different answers across different sessions — the agent runs hundreds of prompt variations across platforms like ChatGPT, Gemini, and Perplexity to build a statistically valid Visibility Score. It also tracks Sentiment (is the AI describing your brand as a leader or adding caveats?), competitor Share of Voice, and which third-party domains are feeding the AI’s citations for your category.
Reason is where the agent earns its name. Once it has the data, it uses an LLM-based reasoning layer to identify why your brand was excluded from a specific response. Three common failure modes surface repeatedly: your brand entity isn’t stable across platforms (Entity Fragility), your content is locked in formats that RAG systems can’t parse (Structural Opaqueness), or your brand is absent from the trust sources AI relies on — Reddit, specialized forums, authoritative directories (Third-Party Absence).
Act is the closed loop. Instead of delivering a list of recommendations, the agent prepares and deploys the fix: drafting FAQ sections optimized for LLM extraction, updating metadata with entity-clear language, creating comparison tables in AI-legible formats, and publishing directly to your CMS. This is the workflow that turns GEO from a monitoring exercise into a growth channel.
AEO vs GEO Agent: They Sound Similar. They’re Not.
Answer Engine Optimization (AEO) came first, built around Google’s Featured Snippets and voice assistants. Its core play: format your content into FAQs, lists, and schema markup so it gets selected as the direct answer to a specific question. Tactical. Page-level. Reactive.
The GEO Agent operates at a different scale. It incorporates AEO tactics but manages something much broader: the entire perception of your brand across the AI ecosystem. Where AEO asks “how do I get this page to answer this question,” GEO asks “how do I make AI consistently choose my brand as the trusted authority across hundreds of queries, multiple platforms, and shifting model updates.”
Put plainly: AEO optimizes a page. A GEO Agent optimizes a brand entity.
AEO is a tactical layer. The GEO Agent is the orchestration layer running above it.
You Can’t Manage AI Visibility With a Spreadsheet
A typical SaaS brand tracking 200 high-intent prompts across five AI platforms, updating weekly to account for model retraining — that’s not a workload one person handles manually. It’s not a workload a small team handles manually, either.
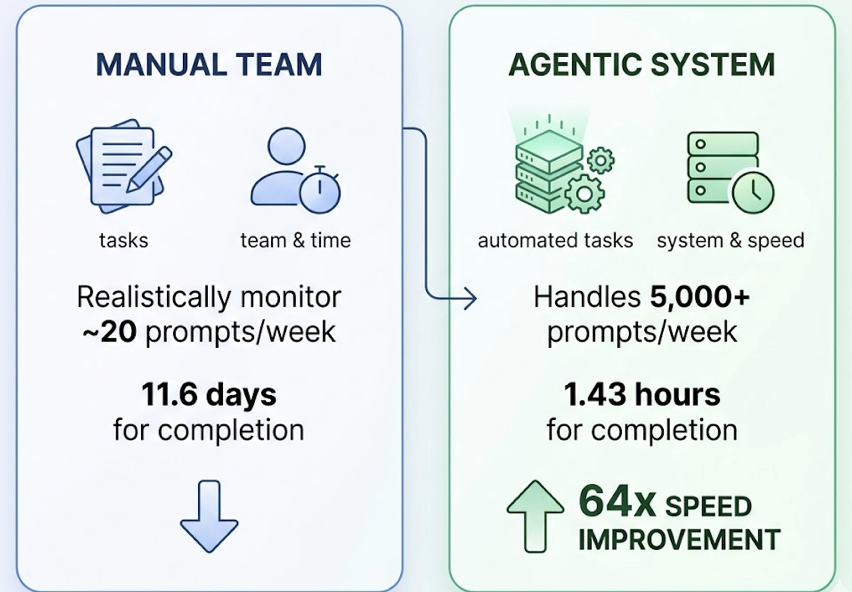
The performance gap between manual and automated GEO is documented. A manual team can realistically monitor around 20 prompts per week. An agentic system handles 5,000+ prompts per week with consistent execution. The speed difference is equally stark: a task that takes a human team 11.6 days can be completed by an automated agent in 1.43 hours. That’s a 64x speed improvement before you even account for error rates.
The ROI figures reflect this. Traditional GEO management reports around 195% ROI. Agentic GEO management comes in at approximately 544%.
This is the Scalability Wall. AI search moves faster than human workflows. Brands that try to keep up manually will fall further behind, not because their strategy is wrong, but because the execution velocity can’t match the pace of model updates and competitive shifts.
How Topify’s GEO Agent Works in Practice
Topify is built around this agentic model. Its platform connects the monitoring, reasoning, and execution layers into a single workflow, designed so a marketing team can manage AI visibility without needing a data science background or an engineering team.
The monitoring layer covers ChatGPT, Gemini, Perplexity, Google AI Overviews, DeepSeek, Doubao, and Qwen — every platform where your audience is already searching. It tracks seven core metrics: Visibility (what percentage of AI responses mention your brand), Sentiment (a 0-100 score for how favorably AI describes you), Position (your relative rank in AI recommendation lists), AI Volume (estimated monthly search demand for a topic), Mentions, Intent stage, and CVR (conversion visibility rate). Together, these metrics give you a picture that no single-metric dashboard can match.
The execution layer is where Topify’s One-Click Agent closes the loop. You state your goal in plain English. Topify generates the content strategy and shows you a preview. You approve it, click once, and the update deploys. No manual CMS work. No separate writing workflow. The system also includes Source Analysis — revealing exactly which domains AI platforms are citing in your category — so you can identify the content gaps creating your visibility deficit.
Early adopters in e-commerce have reported conversion rate uplifts of 10–25% and support ticket reductions of 30–50% after deploying structured GEO responses. That’s not a branding outcome. That’s a revenue outcome.
Plans start at $99/month for up to 100 prompts and 4 AI platforms, with Pro and Enterprise tiers available for teams managing larger prompt sets. See Topify pricing here.
GEO Agent vs. Basic AI Monitoring Tool: What’s Actually Different
The market for AI visibility tools splits into two categories. Knowing which you’re evaluating matters.
| Feature | Basic AI Monitoring Tool | GEO Agent (e.g., Topify) |
|---|---|---|
| Primary Output | Dashboard / Alert | Deployed content update |
| Data Scope | Brand mentions + basic sentiment | Full analytics + citation intelligence |
| Optimization Logic | None (you decide) | AI-generated strategic roadmap |
| CMS Integration | Limited or none | Direct (Shopify, WordPress, etc.) |
| Human Labor Required | High: analysis + implementation | Low: review + approval |
| Outcome Focus | Knowing you’re invisible | Fixing the invisibility |
The fundamental gap is what you might call the Actionable Difference. A basic monitoring tool tells you that your brand isn’t appearing in a specific AI response. A GEO Agent tells you why it isn’t appearing and delivers the updated FAQ and schema to fix it, in the same session. That’s the workflow shift that separates tracking from growth.
Conclusion
The brand that ranked first on Google in 2023 and the brand that gets cited by ChatGPT in 2026 are not automatically the same brand. AI search runs on different signals, rewards different content structures, and updates faster than any human team can manually track.
A GEO Agent doesn’t replace your marketing team. It handles the part of AI visibility that has outgrown human-scale execution: continuous multi-platform monitoring, LLM-based gap analysis, and closed-loop content deployment. That frees your team to focus on strategy and storytelling rather than prompt tracking and CMS updates.
If you’re already investing in SEO and haven’t started managing AI visibility yet, the gap is already growing. Get started with Topify to see where your brand currently stands across the major AI platforms.
FAQ
Q: What is the difference between GEO and AEO?
A: AEO (Answer Engine Optimization) is a tactical discipline focused on formatting specific pages to answer specific questions, mainly through FAQ schemas and structured lists. GEO (Generative Engine Optimization) is a broader strategic framework designed to shape how AI systems perceive and cite your brand across multiple queries and platforms over time. AEO is a subset of GEO, not a replacement for it.
Q: What does an AI agent do in the context of GEO?
A: A GEO Agent autonomously monitors a brand’s visibility across AI platforms, identifies the specific reasons it’s being excluded from relevant responses, and executes the content or distribution changes needed to fix that — with minimal human intervention required beyond review and approval.
Q: Can a non-technical marketer use a GEO agent?
A: Yes. Platforms like Topify are built with natural language interfaces and one-click execution, so you don’t need to understand LLM architecture or write any code. You define the goal; the system handles the execution.
Q: How is Agentic AI different from a standard AI tool like ChatGPT?
A: Standard AI tools are reactive — they respond to a single prompt and produce a single output. Agentic AI is goal-oriented and proactive: it breaks a complex objective into steps, coordinates actions across multiple systems, and operates in a continuous loop until the goal is reached.