Search “best AI answer tracking tool” and you’ll find a dozen platforms each claiming to measure brand visibility across AI search. Most of them only cover ChatGPT. A few cover two platforms. Almost none tell you whether your brand is being recommended positively, where it appears in the response, or whether those citations are converting to revenue.
The gap between what these tools promise and what they deliver is where most teams lose time, budget, and competitive ground.
Most AI Answer Tracking Tools Only Show You Half the Picture
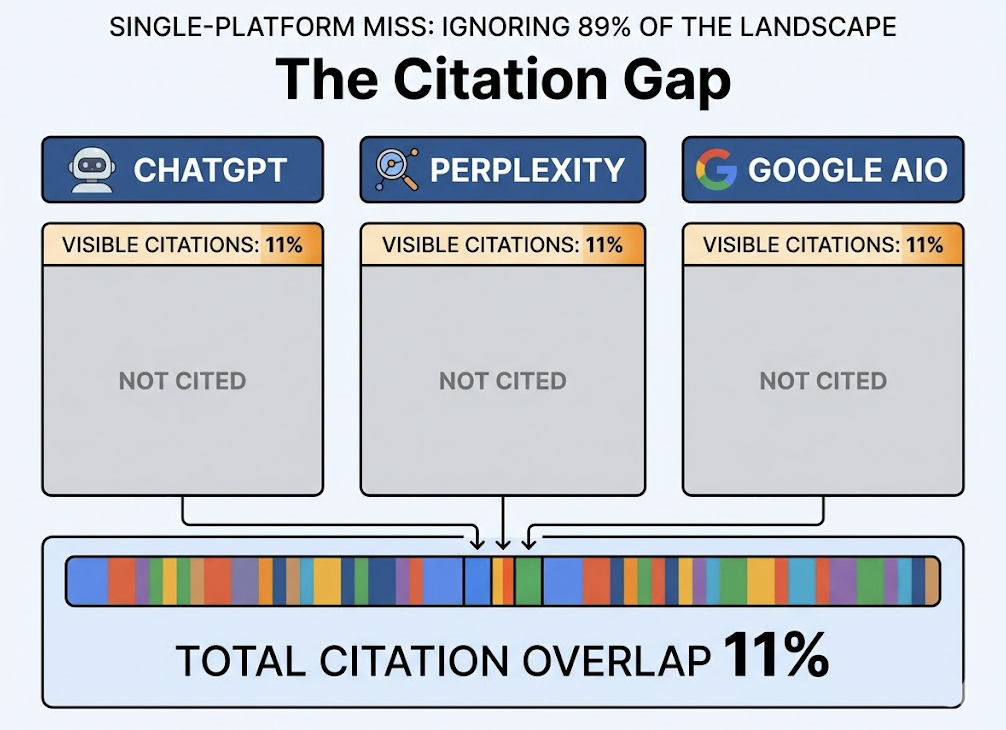
The 2026 AI search market isn’t one platform. It’s at least six. ChatGPT leads with 900 million weekly active users and roughly 60.7% of AI search interactions, but Google Gemini, Microsoft Copilot, Perplexity, and the Chinese ecosystem (DeepSeek, Doubao, Qwen) collectively account for a substantial portion of global activity. A tool that only monitors one of these isn’t tracking AI answers. It’s tracking a fraction of one engine’s output.
The second problem is metric depth. Most entry-level trackers report a binary result: cited or not cited. That tells you almost nothing useful. 75% of users have been misled by AI hallucinations at least once, and AI models produce erroneous or distorted content in 45% of informational news queries. Your brand could be “mentioned” in a way that actively misrepresents your product, and a simple visibility score won’t catch it.
That’s the buying trap. Not a lack of tools, but a lack of the right metrics to evaluate them.
To cut through the noise, a qualified AI answer tracking system in 2026 needs to satisfy four pillars: multi-platform coverage across both Western and Chinese LLMs, sentiment and position data at the mention level, conversion attribution linking AI citations to actual revenue, and an action layer that turns insights into a strategy.
The 6 Best AI Answer Tracking Tools, Ranked
| Rank | Tool | Platform Coverage | Key Differentiator | Starting Price |
|---|---|---|---|---|
| #1 | Topify | ChatGPT, Gemini, Perplexity, DeepSeek, Qwen, Doubao | 7-Dimension Metric System with CVR | $99/mo |
| #2 | Profound | 10+ engines incl. Claude, Grok, Meta AI | Log-level crawler analytics | $99/mo (Lite) |
| #3 | ZipTie | ChatGPT, Perplexity, Google AIO | Screenshot evidence and technical audits | $69/mo |
| #4 | SE Ranking | Google AI Mode, AIO, ChatGPT | Integrated SEO/GEO workflow | $119/mo |
| #5 | Peec AI | ChatGPT, Gemini, Perplexity, Claude | Unlimited team seats and SOV analysis | €95/mo |
| #6 | AthenaHQ | 8+ LLMs incl. Grok, Copilot, Rufus | Narrative tone and PR risk monitoring | $295/mo |
#1 Topify: The Most Complete AI Answer Tracking Platform
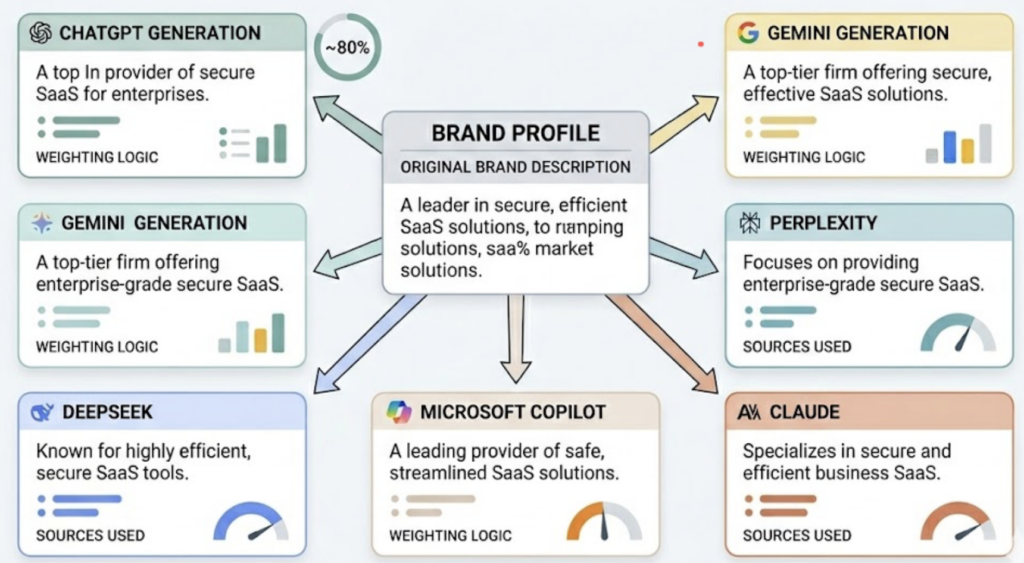
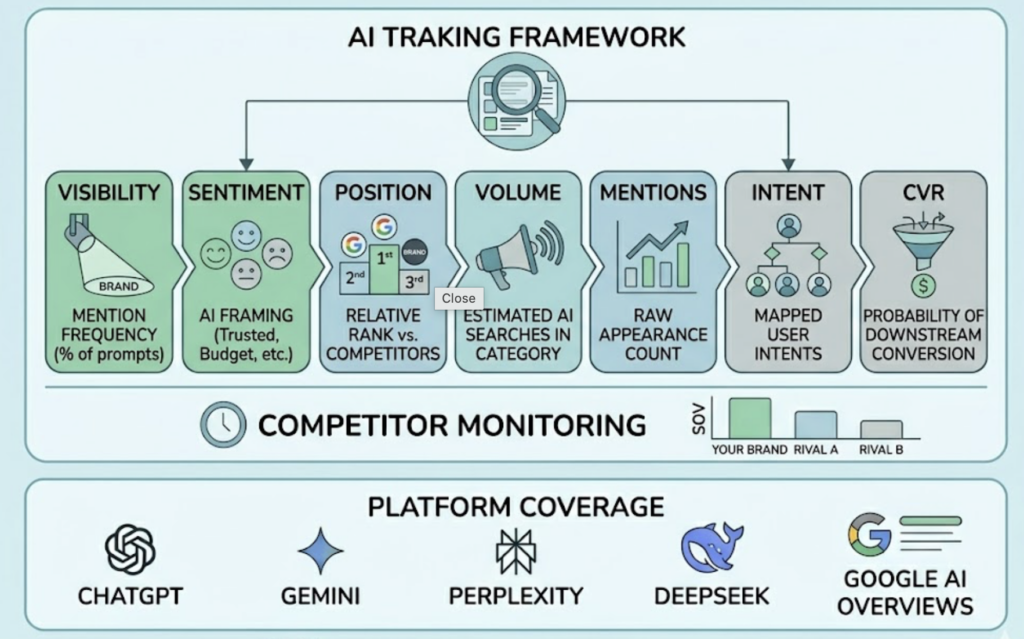
Topify stands apart from the field because it was built as a GEO-native AI answer tracking platform, not an SEO tool with an AI module bolted on. The core of the product is a Seven-Dimension Metric System that covers what every other tool on this list measures partially or not at all.
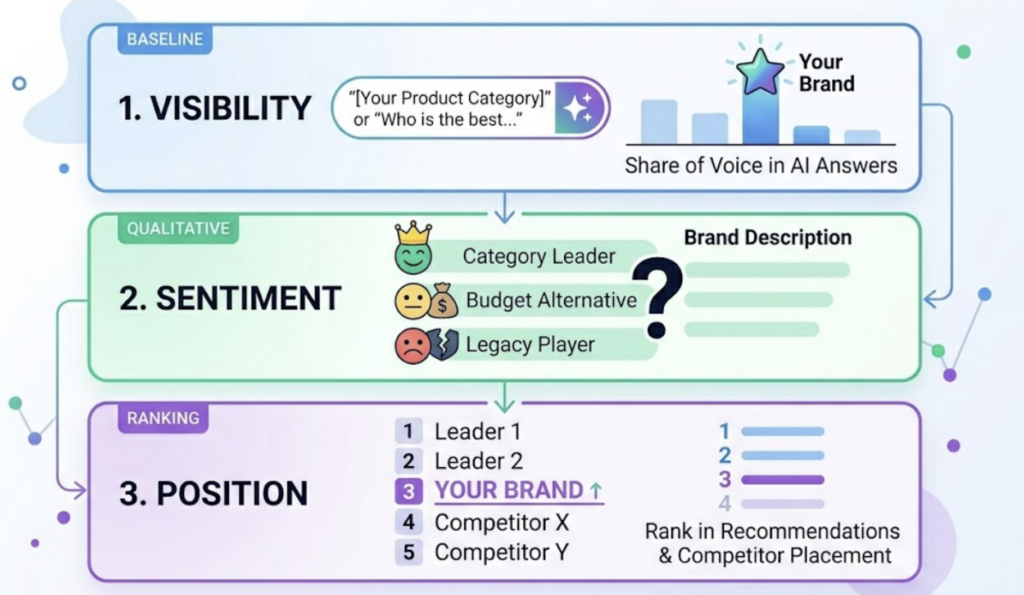
Those seven dimensions are: Visibility Score (the percentage of AI responses that include the brand across a defined prompt set), Sentiment Score (a 0–100 NLP-driven rating of how the brand is framed), Position Weighting (ordinal placement within the response), Conversational Volume (the generative equivalent of search volume), Entity Mentions, User Intent Analysis, and CVR.
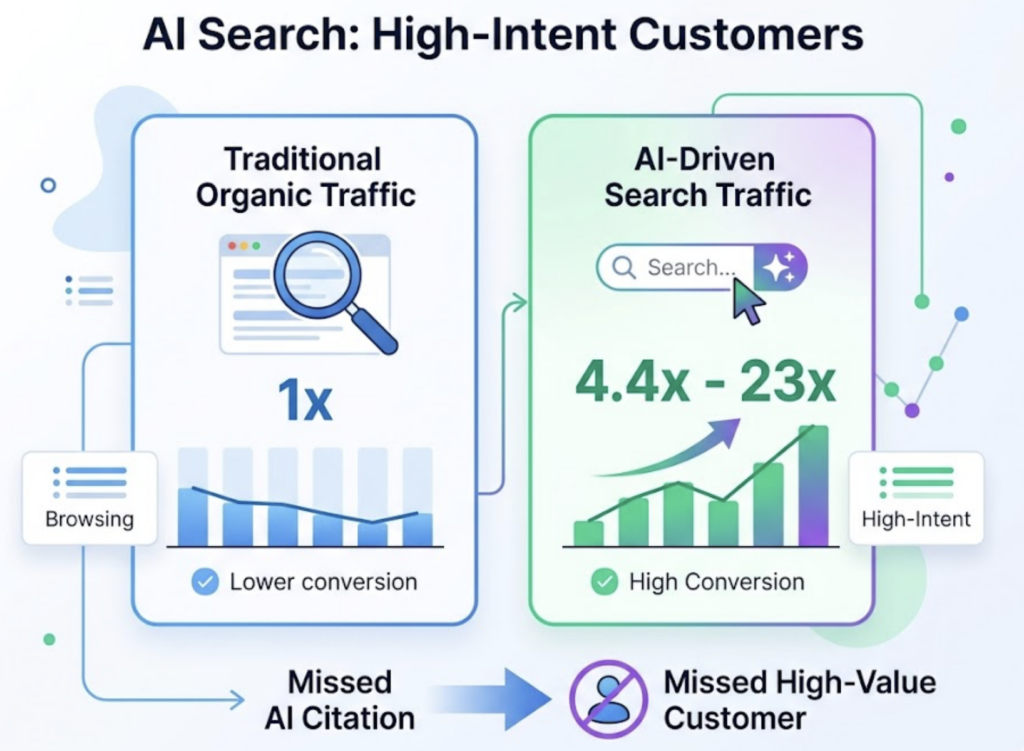
The CVR dimension is where Topify separates itself from every other AI answer tracking software on the market. Through native integration with Google Analytics 4 and Shopify, Topify connects AI citations directly to on-site revenue. Early adopters report that traffic arriving from AI citations converts at 27%, compared to 2.1% for traditional organic search, a 12.9x lead efficiency improvement. For most B2B teams, that number alone justifies the investment.
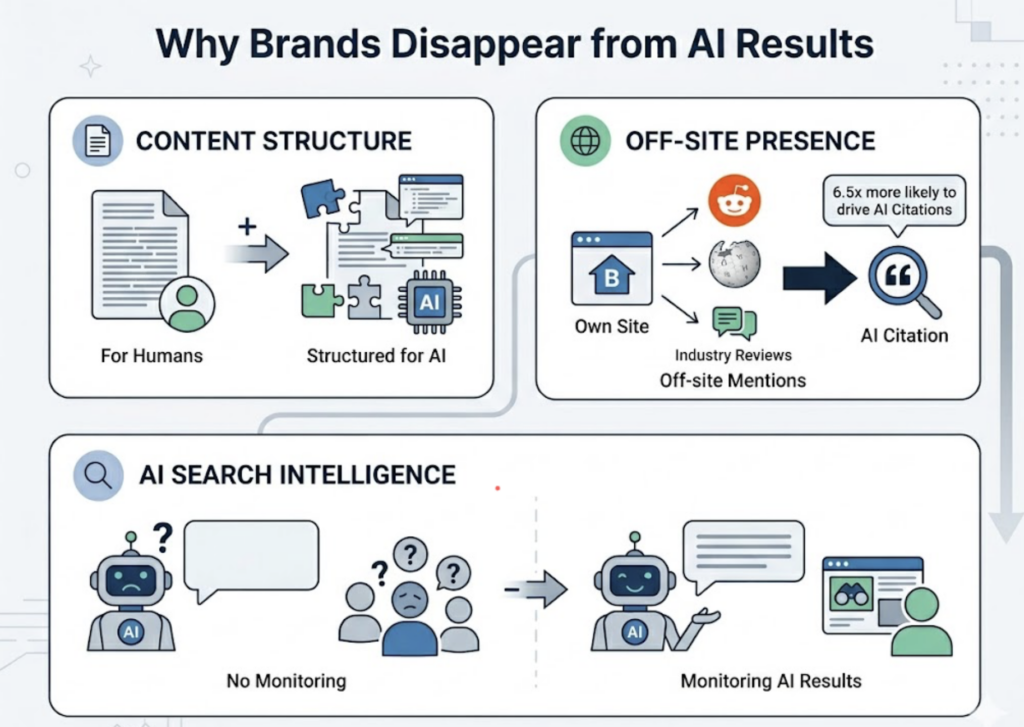
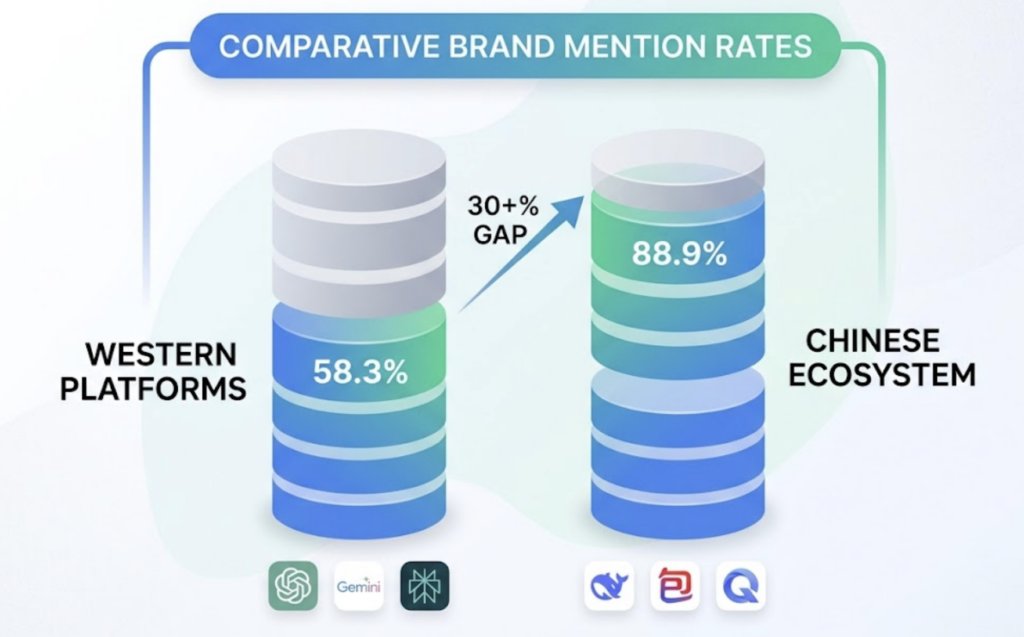
Platform coverage is global and genuinely multi-model. Topify monitors ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, and Qwen natively, covering both Western platforms and the increasingly influential Chinese ecosystem. Research on cultural encoding in LLMs shows that Chinese models like Qwen and DeepSeek mention brands at a rate of 88.9% for pure-English queries compared to 58.3% for international models. A 30+ percentage point gap in brand mention rates is not a rounding error. It’s a blind spot that tools without Chinese platform coverage leave completely unaddressed.
Beyond tracking, Topify includes a one-click execution layer where teams can define optimization goals in plain English, review a proposed GEO strategy, and deploy it without building custom workflows. For teams that don’t have the bandwidth to interpret a dashboard and then manually figure out what to do next, this closes the loop between data and action.
Topify’s Basic plan starts at $99/mo and includes 100 prompts and 9,000 AI answer analyses across 4 projects. The Pro plan at $199/mo expands to 250 prompts and 22,500 analyses. Enterprise plans start at $499/mo with dedicated account management and custom configurations. Get started with a free trial here.
Best for: In-house marketing teams, B2B SaaS brands, and agencies managing multiple clients who need to connect AI visibility directly to revenue KPIs.
#2 Profound: The Enterprise Standard for Crawler Intelligence
Profound is designed for large-scale organizations that need to understand not just what AI outputs, but what AI ingests. Rather than tracking the final answer, it analyzes the input by monitoring log-level data from AI crawlers like GPTBot and PerplexityBot across 10+ engines, including Claude, Grok, and Meta AI.
That depth comes with trade-offs. Profound’s “Conversation Explorer” surfaces patterns from 400 million real user prompts, but the platform’s complexity and enterprise-tier pricing (often starting in the thousands per month) put it out of reach for smaller teams.
Best for: Enterprise legal, compliance, and technical teams that need governance-level visibility into how AI bots interact with their web infrastructure.
#3 ZipTie: Data Quality and Technical Verification
ZipTie’s core strength is evidence. Where most API-based tools receive standardized text responses, ZipTie captures actual user-facing screenshots of Google AI Overviews and ChatGPT carousels. For agency reporting, this matters: visual proof of placement is often more persuasive to clients than a percentage score in a dashboard.
Its indexation audit feature also identifies whether AI retrieval systems are failing to parse a site’s JavaScript or missing critical schema, which is a practical starting point for teams troubleshooting their technical GEO health.
Best for: Digital agencies that need client-ready visual evidence of AI placements, and technical SEO teams diagnosing extraction readiness issues.
#4 SE Ranking: The Smoothest On-Ramp for SEO Professionals
SE Ranking offers the most practical transition path for teams that are deeply invested in traditional SEO and want to add AI tracking without overhauling their workflow. Its AI Search Toolkit sits inside the same interface as its keyword rank tracker, allowing users to view Google organic rankings and AI Overview citations side by side.
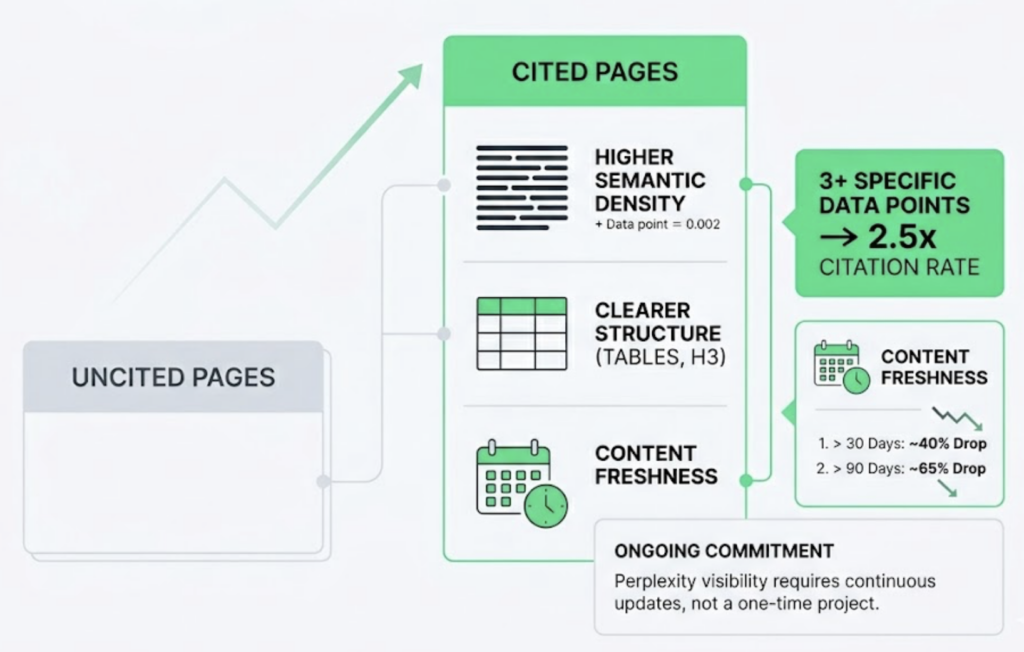
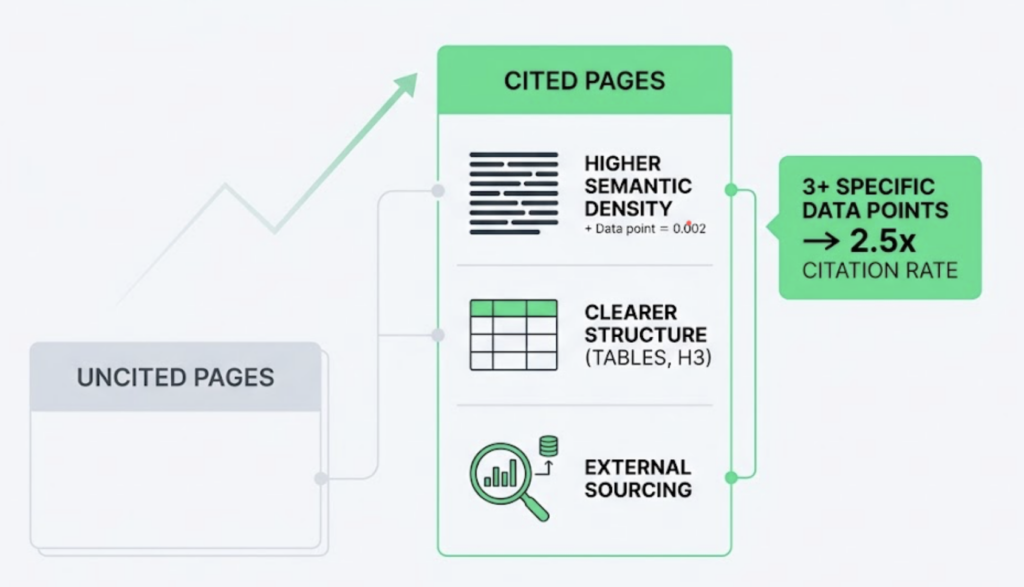
Its standout feature is a “Not Cited” diagnostic flag, which identifies queries where the brand ranks in the top 3 organic results but gets excluded from the corresponding AI Overview. That gap between ranking authority and extraction readiness is one of the most common and underreported problems in 2026 search performance.
Best for: SEO-first teams that want AI tracking integrated into an existing workflow without adopting a separate platform.
#5 Peec AI: The Share of Voice Specialist
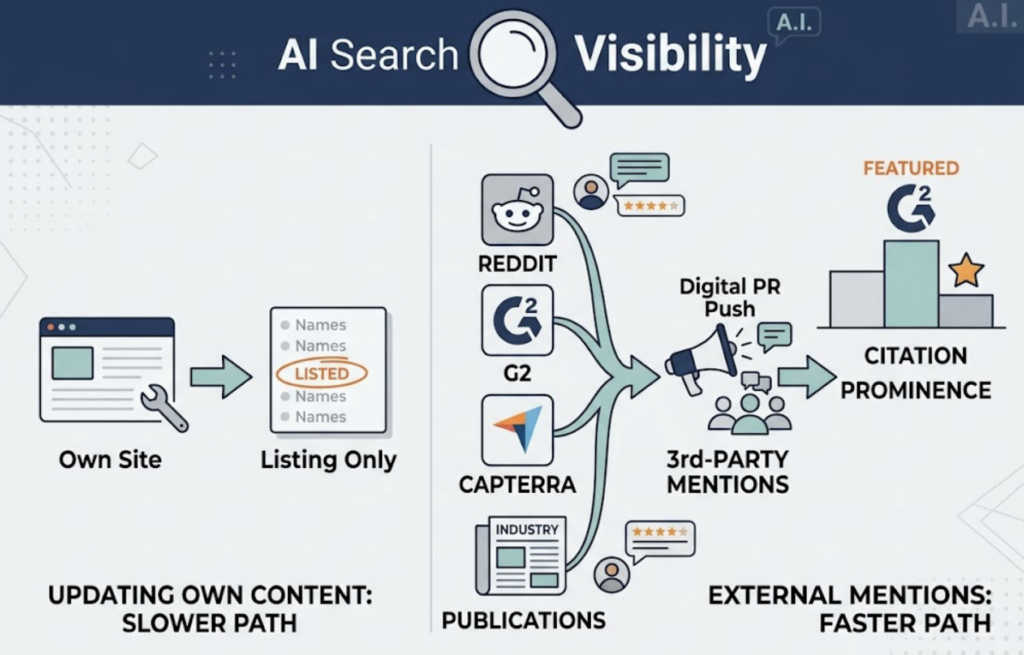
Peec AI’s strength is competitive benchmarking. Its Share of Voice dashboards show how a brand’s AI presence compares to up to nine competitors simultaneously, and its Citation Source Mapping identifies whether an LLM is forming its opinions based on Reddit threads, YouTube transcripts, or branded content. That insight is especially actionable for PR teams.
The platform covers ChatGPT, Gemini, Perplexity, and Claude, but lacks coverage of the Chinese ecosystem and doesn’t offer conversion attribution. For B2B SaaS teams that need CVR data, that gap is significant.
Best for: B2B SaaS and e-commerce brands running competitive analysis, where share of voice is the primary reporting metric.
#6 AthenaHQ: Narrative Risk and Reputation Monitoring
AthenaHQ is built for brand managers and PR teams who care less about citation frequency and more about how AI describes the brand. Its Narrative Tone analysis spans 8+ LLMs, including Grok, Copilot, and Amazon Rufus, and its Action Center prioritizes fixes based on their potential impact on entity signals.
It’s the right tool if your primary concern is correcting hallucinations or reclaiming a brand narrative that has drifted from its intended positioning. At $295/mo starting price, it’s a specialist tool for a specific use case.
Best for: Enterprise brand and communications teams managing reputational risk across global AI platforms.
What LLM Visibility Actually Means (And Why Rank Trackers Can’t Measure It)
Traditional rank trackers are built to find a specific URL within a structured HTML list. An AI-generated answer has no fixed URL structure. A brand might be mentioned by name but not linked to, cited in the summary text while the link points to a third-party review site, or described accurately without the brand name ever appearing.
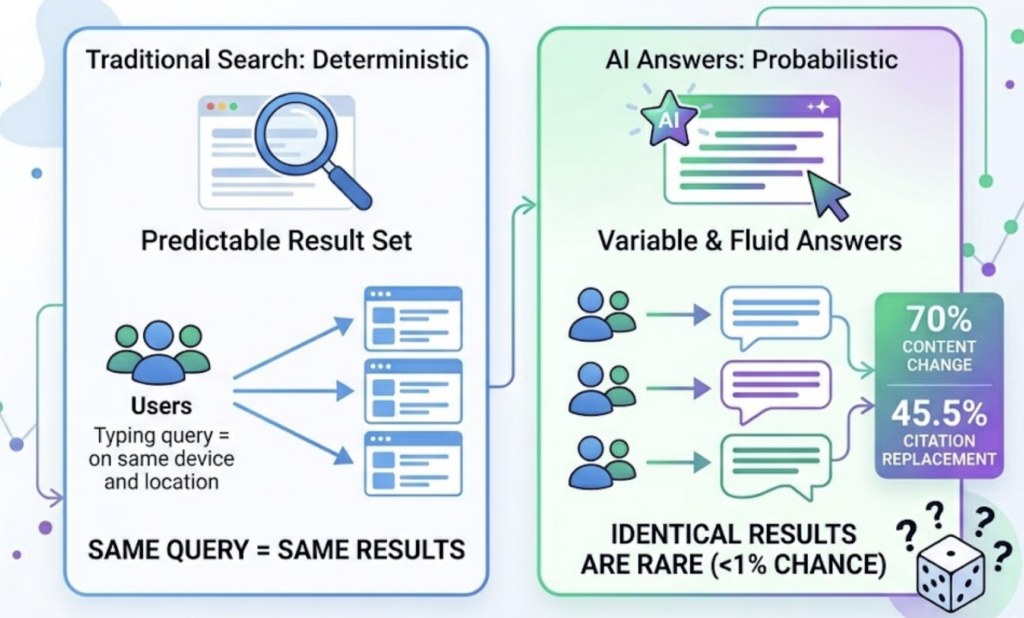
That’s the core divergence. In traditional SEO, visibility is a position: #1, #3, #7. In LLM-based search, LLM visibility is a probability: the likelihood that an AI will include your brand in a synthesized response to a specific prompt. Research shows that only 30% of brands stay visible from one AI answer to the next, and only 20% remain present across five consecutive runs of the same prompt. A daily-refresh rank tracker has no framework to measure that kind of volatility.
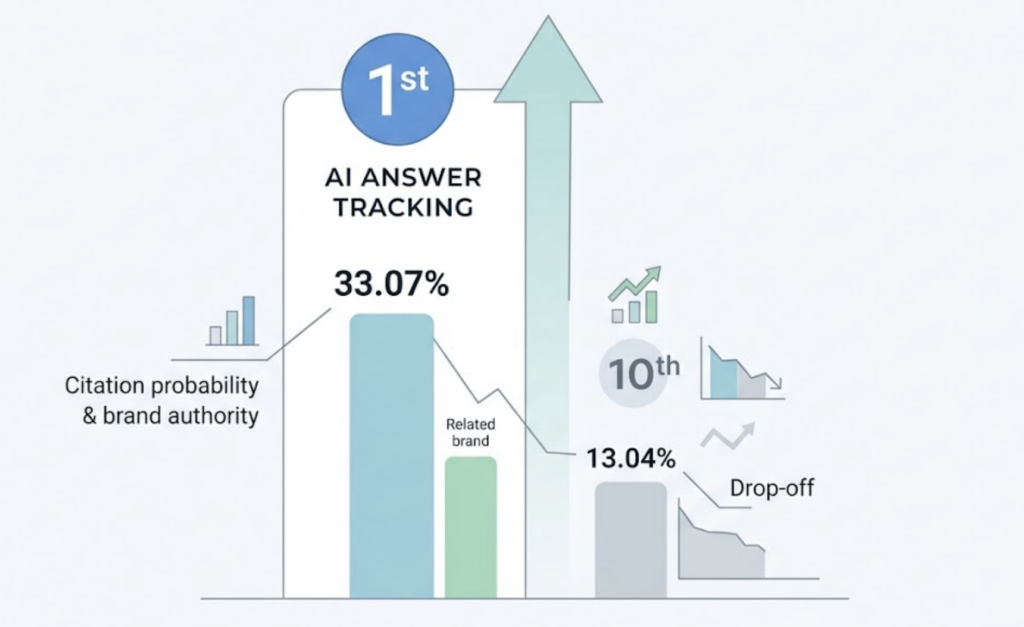
There’s also a positional dimension that doesn’t exist in traditional search. Research indicates the first-mentioned brand in an AI recommendation earns a 33.07% citation probability, while the tenth drops to 13.04%. Being included in an AI answer and being mentioned first in that answer represent meaningfully different levels of brand authority. Only an AI answer tracking dashboard with position weighting can capture that distinction.
GEO vs SEO: Why the Metrics Are Fundamentally Different
SEO and GEO are not competing disciplines. They’re two parallel measurement tracks, each serving a different stage of how buyers discover and evaluate brands.
| Metric Dimension | SEO (Traditional Search) | GEO (AI Answer Engines) |
|---|---|---|
| Visibility | Keyword Ranking (1–10) | Citation Frequency (%) |
| CTR Basis | Clicks relative to rank | Attribution rate relative to mentions |
| Authority Signal | Backlinks and Domain Rating | Entity mentions and expert co-mentions |
| Technical Requirement | Speed and mobile-friendliness | Extraction readiness and schema depth |
| Avg. Conversion Rate | 2.1%–2.8% | 14.2%–27.0% |
| Source Type | Brand-owned website | Multi-source (Reddit, YouTube, PR) |
The conversion gap is significant. The zero-click rate has reached 68–72% as of early 2026, but users who click through from an AI citation arrive pre-qualified. The AI has already compared the product against alternatives and validated the brand’s credentials. That’s why GEO traffic converts at 27% while traditional organic traffic sits at 2.1%.
SEO remains the infrastructure layer. 76% of URLs cited in AI Overviews still come from the top 10 organic results, which means a strong SEO foundation is a prerequisite for GEO traction, not a substitute for it. The brands that will win in 2026 are running both tracks simultaneously, and measuring each one with the right tools.
How to Choose an AI Answer Tracking Solution for Your Team
Three factors should drive the decision.
The first is platform coverage. If your audience includes technical, developer, or research segments, Chinese LLMs like DeepSeek and Doubao are no longer optional data points. The 30.6 percentage point gap in brand mention rates between Chinese and international models means your brand’s visibility profile looks very different depending on which platforms you’re monitoring.
The second is the presence of a conversion layer. Most AI answer tracking analytics platforms stop at the dashboard. They show you visibility scores, sentiment trends, and position data, but leave the “so what” entirely to your team. If your marketing org needs to justify GEO spend to leadership, you need a tool that connects citations to revenue, not just impressions.
The third is refresh frequency. LLM outputs are non-deterministic: the same prompt asked on Monday may return a different answer on Tuesday. Weekly data refresh cycles are insufficient for competitive markets where AI citation patterns can shift within days of a news cycle, a product update, or a competitor’s content push. Daily refresh is the minimum viable standard.
One additional technical check is worth running before committing to any platform. 34% of B2B SaaS companies have blocked AI crawlers like GPTBot via robots.txt, believing this protects their intellectual property. In practice, it means those brands are excluded from the AI’s consideration set in 81% of test cases, even when they’re the category leader. A credible AI answer tracking tool should include a crawlability audit as part of its onboarding flow.
For most in-house marketing teams and agencies, Topify covers all three factors: global platform coverage including Chinese LLMs, direct CVR integration with GA4 and Shopify, and the only seven-dimension measurement framework currently available in the market.
Conclusion
The core question for marketing teams in 2026 is no longer “where do we rank?” It’s “what does the AI say about us, and is anyone buying because of it?”
Most AI answer tracking tools answer the first half of that question. Topify answers both. For teams that need to move from visibility data to revenue impact, that distinction is the bottom line. Start with a free trial and run your first prompt set in under 10 minutes.
FAQ
Q: What is the best rank tracking tool for LLM-based search engines?
A: For teams that need multi-platform LLM tracking with revenue attribution, Topify is the strongest option in 2026. Its seven-dimension metric system covers visibility, sentiment, position, and CVR across ChatGPT, Gemini, Perplexity, DeepSeek, and the Chinese ecosystem. SE Ranking is a strong alternative for teams that want to keep LLM tracking inside an existing SEO workflow.
Q: What is the best AI overview tracker?
A: SE Ranking and ZipTie are the most effective for tracking Google’s AI Overviews specifically. SE Ranking flags gaps between organic rankings and AI Overview citations, while ZipTie captures screenshot-level evidence of actual placements. For broader AI search tracking that goes beyond Google, Topify’s AI answer tracking dashboard covers a wider range of platforms.
Q: What is LLM visibility?
A: LLM visibility measures how consistently a brand is included, positioned, and described within AI-generated answers. Unlike a keyword ranking, it’s a probabilistic metric: research shows only 30% of brands stay visible from one AI answer to the next on identical prompts. It’s influenced by semantic clarity, factual density, and how frequently your brand is cited by sources the AI trusts.
Q: What is GEO vs SEO?
A: SEO (Search Engine Optimization) optimizes content for algorithms that rank links and earn clicks. GEO (Generative Engine Optimization) optimizes content for AI retrieval engines that synthesize direct answers and earn citations. The key practical difference is conversion rate: GEO traffic typically converts at 14–27%, compared to 2–3% for traditional organic search. The two disciplines are complementary, not competing.