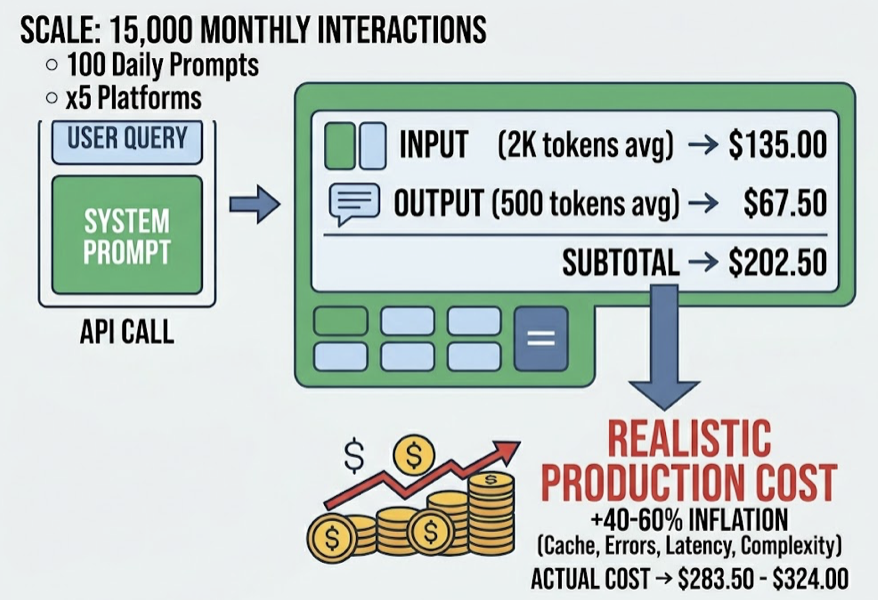
Your agentic AI dashboard looks great. Mentions are up. Prompt coverage is green. And yet, somewhere in your funnel, qualified buyers who asked ChatGPT for a recommendation never made it to your site.
That’s the gap most marketing teams don’t see until it’s too late.
Agentic AI tools have fundamentally changed what’s possible in brand monitoring. But the tools that excel at tracking activity often leave out the metrics that drive revenue. Understanding the difference between the two is the most important diagnostic question a marketer can ask in 2026.
What Agentic AI Actually Does for Marketing Teams
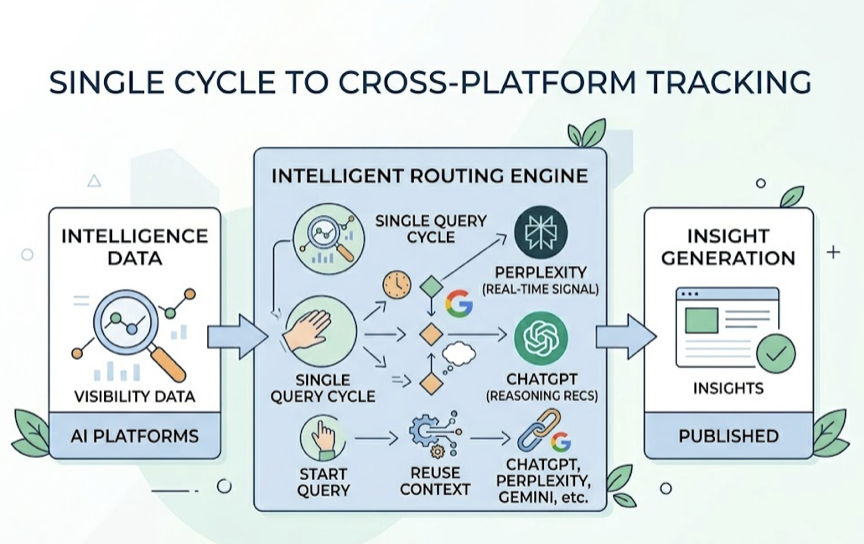
An agentic AI tool doesn’t wait for instructions. It monitors, decides, and acts.
Where traditional marketing automation runs on “if-then” decision trees, agentic systems use probabilistic reasoning to navigate uncertain environments. A traditional tool sends a welcome email when a trigger fires. An agentic tool tracks competitor pricing shifts, detects sentiment drifts in third-party reviews, spots a content gap across AI platforms, and initiates a content response, all without a human setting each step.
In a marketing context, this plays out in real use cases: a listener agent monitors AI-generated answers for brand mentions, a creator agent drafts tailored assets based on what buyers are asking, and a deployment agent pushes updates to the content pipeline. The cycle is continuous, not batch-processed.
That shift matters because consumer discovery has moved. Search volume is rising, but clicks to websites are declining as AI-generated summaries resolve queries without ever sending a user to a brand page. Marketers who rely solely on traditional tools are missing the layer where AI shapes preferences before a website visit happens.
The 4 Things Agentic AI Tracking Does Well
These tools have genuine strengths. It’s worth being clear about where they actually deliver.
Prompt frequency and volume. Agentic tools surface how buyers are asking questions in AI interfaces, not search bars. The average AI prompt runs 12.3 words versus Google’s 2.8, which means the intent signal is significantly richer. Topify’s High-Value Prompt Discovery continuously maps these prompts, including the 95% that have no recorded search volume in traditional SEO tools like SEMrush or Ahrefs.

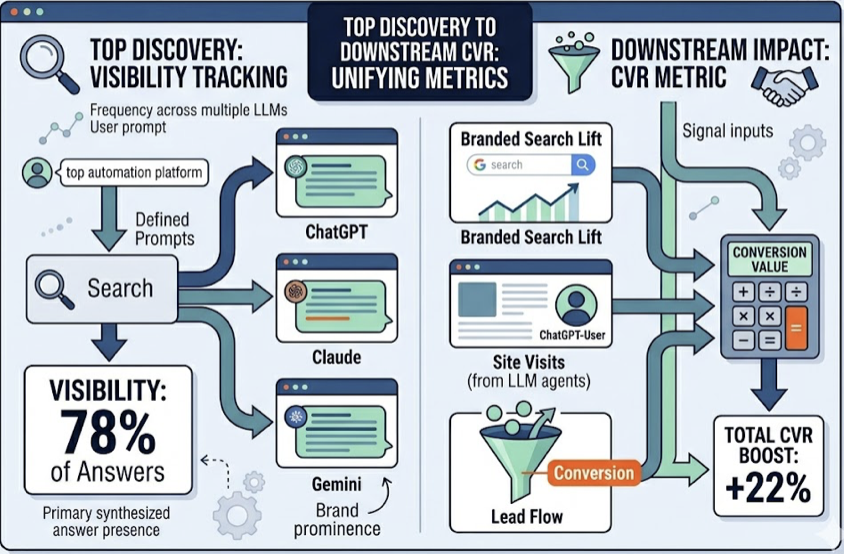
AI Visibility Rate. This measures what percentage of AI-generated responses for a target prompt set include your brand. Average brand visibility sits at 0.3%, while leaders in competitive SaaS categories reach 59.4%. Tracking this number is the baseline for any serious GEO strategy.
Competitor benchmarking in AI answers. Unlike traditional search, where competitors appear in a vertical list, AI engines cluster brands by semantic relevance. Agentic monitoring shows which rivals are consistently recommended alongside or instead of you, including niche aggregators that don’t rank on the first page of Google.
Citation source tracking. Because 85% of brand mentions in AI-generated answers come from third-party domains, knowing which URLs are driving a competitor’s visibility is as valuable as knowing your own citation rate. Agentic tools track which platforms (Reddit, G2, Trustpilot) are feeding the model’s recommendations.
These four capabilities are genuinely useful. They’re also incomplete.
The 3 Gaps That Undermine Your Agentic AI Stack
Most tools track whether you’re showing up. Few track how you’re showing up, or what happens next.
Gap 1: Sentiment Polarity
Tracking mentions without tracking sentiment is like counting impressions and ignoring click-through rate.
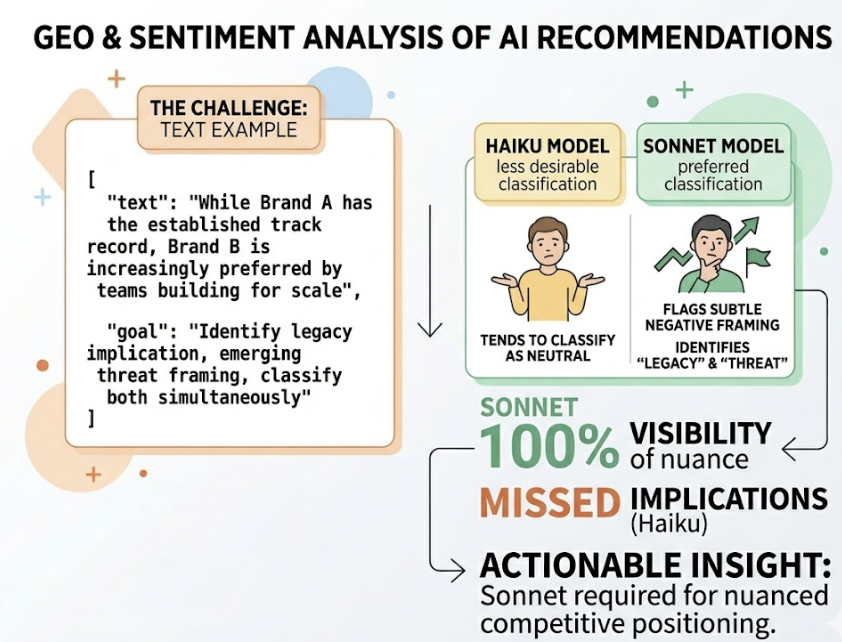
AI models don’t just list brands. They characterize them. A brand with a high visibility score might be described as “an outdated solution” or “prone to support issues,” which actively works against conversion. Google AI Overviews are 44% more likely to surface negative brand sentiment than ChatGPT. If the language framing is neutral or negative, that brand is structurally ineligible to win “best-of” queries regardless of how often it appears.
Topify’s Sentiment Analysis scores brand sentiment on a 0-100 scale across platforms, so teams can see not just that they were mentioned, but whether the AI is positioning them as a recommended option or a cautionary example.
Gap 2: Position Within the Answer
Being mentioned fifth in a recommendation is not the same as being mentioned first.
In a conversational interface, position signals the model’s confidence and determines where the user’s attention lands. Research shows 44.2% of AI citations are drawn from the first third of a page’s content, and brands appearing in the initial summary capture the majority of the trust transfer from AI to buyer. The challenge is that AI responses are probabilistic: a brand might be first in 40% of responses and fifth in the other 60%. Without position tracking, you can’t see the distribution.
Topify’s Position Tracking monitors where your brand lands relative to competitors across each target prompt, giving teams the data to understand whether they’re consistently leading the answer or drifting toward the footnotes.
Gap 3: The Conversion Signal
This is the gap that makes the other two feel manageable by comparison.
Traditional analytics tools are structurally blind to AI interactions. The engagement happens on the AI platform’s servers, not your website. But the traffic that does arrive from AI referrals converts at 14.2%, compared to 2.8% for Google organic. That’s a 5x advantage. AI search traffic also generates $47 revenue per visit against $9 for Google search.
Without tracking what happens after an AI recommendation, marketers can’t close the loop between visibility and pipeline. Topify’s Conversion Visibility Rate (CVR) connects AI discovery to downstream funnel signals, giving teams a way to prove that GEO investment is translating into high-value leads.
Why These Gaps Get Worse Over Time
Missing sentiment and position data isn’t a static oversight. It compounds.
Large language models operate through reinforcement feedback loops. Outputs are fed back as training inputs, which means existing characterizations get amplified with each model update. If a brand’s sentiment is consistently neutral or negative, the model’s internal probability weights progressively favor competitors with stronger authority signals and positive framing. The gap widens automatically.
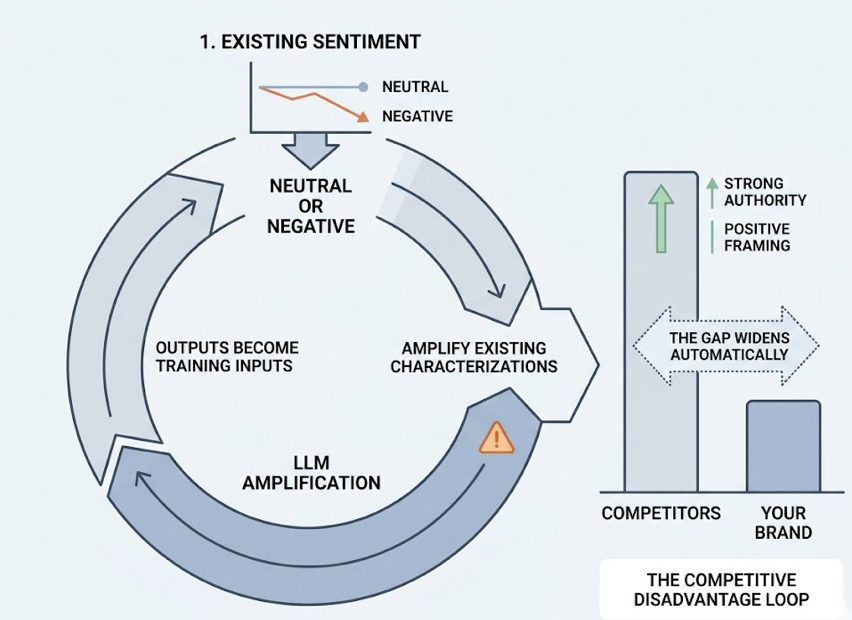
This effect is especially acute in B2B, where AI search queries average 12.3 words and the model typically returns only 2-3 curated solutions rather than a page of ten links. Being left off that shortlist isn’t a ranking problem. It’s binary exclusion.
The math on CTR reinforces this. Even a brand that ranks #1 in traditional SEO can see its click-through rate drop by 47% if an AI summary resolves the user’s query without sending them anywhere. AI visibility within the answer is the only defensible KPI for top-of-funnel protection.
That’s not a future risk. It’s the current condition.
A 3-Layer Tracking Framework That Covers the Full Picture
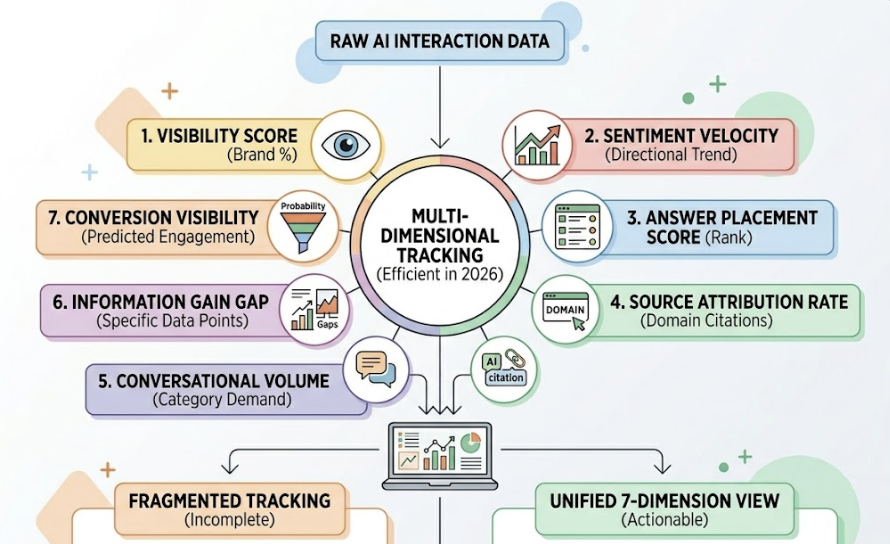
Moving from passive monitoring to strategic execution requires a structure that connects technical visibility to brand quality and revenue. Topify’s seven core metrics (visibility, sentiment, position, volume, mentions, intent, and CVR) map directly onto three tracking layers.
Layer 1: Visibility. Are you showing up at all? This layer tracks prompt coverage and AI Visibility Rate across ChatGPT, Gemini, and Perplexity. If a brand is absent from 90% of relevant prompts, it signals a structural content problem or a failure in how the retrieval-augmented generation process is pulling brand information.
Layer 2: Quality. How are you showing up? This layer audits sentiment polarity and position within the answer. It identifies whether the AI is framing your brand as a market leader or a niche fallback, and which third-party domains are influencing that framing. Topify’s Source Analysis reverse-engineers the exact citation sources shaping the model’s characterization.
Layer 3: Impact. What happens after? This connects AI discovery to CVR and pipeline signals. Buyers who find a brand through AI move 73% faster to a purchase decision than those coming from Google. Tracking this layer is how GEO investment gets defended in a budget conversation.
Each layer is necessary. Running only Layer 1 is like tracking email deliverability without tracking opens or clicks.
How to Audit Your Agentic AI Setup Now
This doesn’t require a full platform overhaul. A structured audit cycle surfaces the gaps quickly.
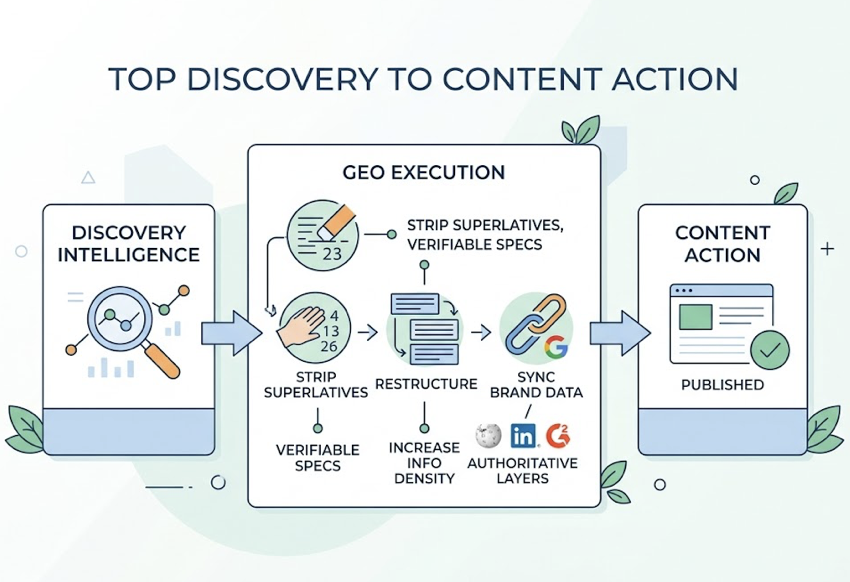
Step 1: Map your high-value prompts. List the natural-language questions your buyers are likely asking AI interfaces during discovery. Traditional keyword tools don’t capture this; you need an intelligence layer that sees actual prompt frequency inside AI platforms. Topify’s High-Value Prompt Discovery automates this and surfaces emerging prompts as they shift.
Step 2: Run cross-engine benchmarking. Test each prompt across ChatGPT, Gemini, and Perplexity separately. Platform-specific biases are real: Perplexity tends to favor niche expertise and citation depth, while Gemini has grown 388% year-over-year and integrates tightly with Google’s search ecosystem. What surfaces on one platform won’t always match another.
Step 3: Audit narrative framing. For each prompt where your brand appears, check the characterization. Is the AI citing your documentation? A G2 review? A Reddit thread from 2022? The source shapes the framing. Topify’s Source Analysis identifies exactly which domains are feeding the model’s description of your brand.
Step 4: Map gaps to execution. Identify where your brand is missing, characterize the cause (content gap, citation gap, or sentiment signal), and deploy targeted fixes. Topify’s AI Agent can identify a citation gap, propose a content restructure, and deploy to the CMS with one click, closing the loop from insight to action without a manual handoff.
Conclusion
Agentic AI tools are only as good as what they’re measuring. If your stack tracks activity but not outcomes, you’re flying with half the instruments.
The financial stakes are documented: cited brands receive 35% more organic clicks and 91% more paid clicks. AI traffic converts at 5x the rate of Google organic. Missing from the AI’s recommended shortlist isn’t a visibility problem. It’s a revenue problem.
The shift from “are we mentioned?” to “how are we characterized, where do we rank in the answer, and what do buyers do next?” is the difference between a monitoring stack and a growth strategy. Building toward Topify and a full 3-layer framework is how marketing teams close that gap before the compounding effect works against them.
FAQ
What’s the difference between agentic AI and regular AI tools?
Regular AI tools are task-specific and reactive. They wait for a human to set a trigger, then execute a narrow instruction. Agentic AI is goal-oriented and autonomous: it can plan multi-step workflows, reason across platforms, and initiate actions independently to pursue a broader objective like managing brand visibility across multiple AI engines.
Which AI platforms should marketers track in 2026?
At minimum: ChatGPT for volume, Gemini for its 388% year-over-year growth and Google ecosystem integration, and Perplexity for B2B and research-heavy segments where citation accuracy drives trust. Claude traffic converts at 16.8%, making it essential for high-intent niches despite lower overall volume.
How do I know if my brand’s AI sentiment is hurting conversions?
Monitor your Sentiment Polarity score across high-intent queries. If AI engines consistently describe your brand with negative qualifiers or place a competitor first despite your brand appearing in the same answer, sentiment is likely causing buyers to self-select out before they reach your site. The signal shows up in lower CVR even when visibility numbers look healthy.
Is agentic AI tracking different from traditional SEO monitoring?
Yes. Traditional SEO focuses on keyword rankings, backlinks, and click-through rates on search results pages. Agentic AI tracking (GEO) focuses on Share of Answer: the frequency, position, and sentiment of your brand within synthesized AI responses, and the third-party domains the model is using to form its characterization of you.