The biggest open-source AI drop of 2026 just changed where your audience searches. Here’s what it means for your brand visibility strategy.
Most marketers heard about DeepSeek V4’s release and filed it under “model news.” That’s a mistake. DeepSeek V4 isn’t just a smarter chatbot. It’s a new discovery channel, and by March 2026, it was pulling 350.8 million monthly web visits with no signs of slowing down.
If you’re not tracking your brand on it, you’re not just missing data. You’re missing recommendations.
DeepSeek V4 in Plain English: What Actually Changed for Brand Visibility
Forget the parameter counts. What matters for marketers is behavioral change, and DeepSeek V4 changed a lot.
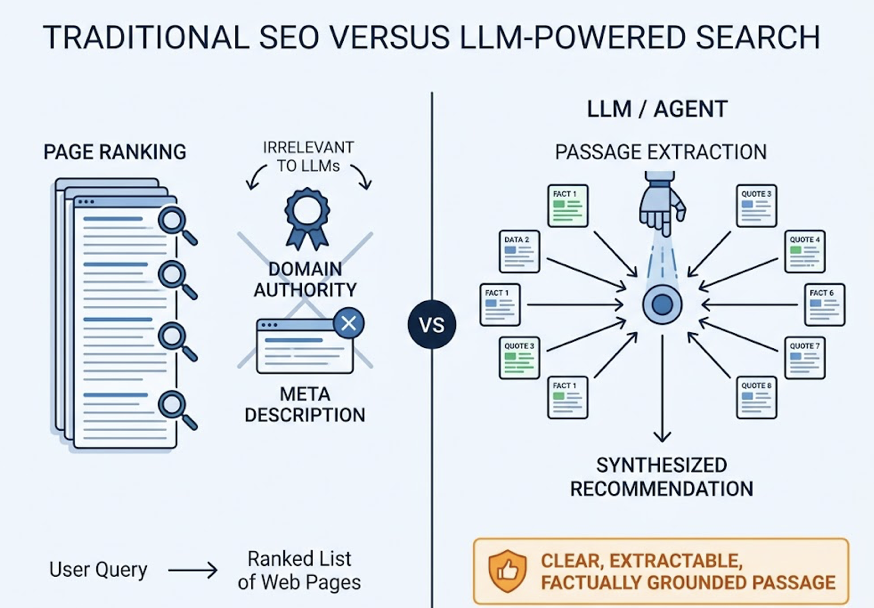
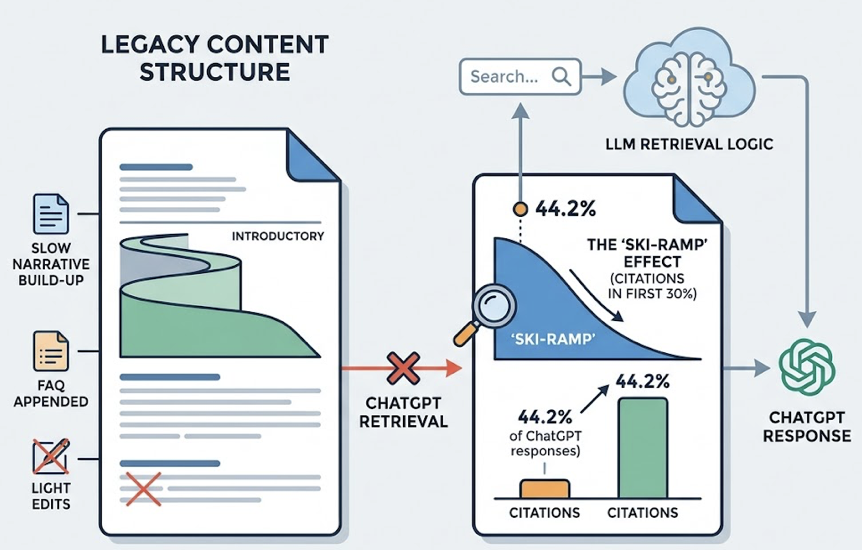
V3 was reactive. A user asked, and the model answered by pulling from what it had seen. V4 operates differently. It runs what researchers call a “Deliberative Search Model,” a cycle of Planning → Query Generation → Search → Reflection before it ever surfaces a recommendation. In practice, this means the model is no longer summarizing the internet. It’s auditing it.
When a user asks DeepSeek V4 to recommend an enterprise CRM, the model doesn’t just pull a list. It decomposes the query into verification points, including scalability benchmarks, security certifications, and verified user reviews, then cross-validates claims across sources before assigning confidence scores.
How DeepSeek V4 Differs from V3 in the Way It Recommends Brands
The table below captures what’s actually shifted for brand teams:
| Behavioral Dimension | DeepSeek V3 | DeepSeek V4 |
|---|---|---|
| Reasoning | Single-pass inference | Multi-stage “Thinking” mode |
| Citation style | Broad summaries | Footnote-level verifiable sources |
| Task behavior | Reactive responses | Agentic workflow execution |
| Context window | 128K tokens | 1 million tokens (“Interleaved” history) |
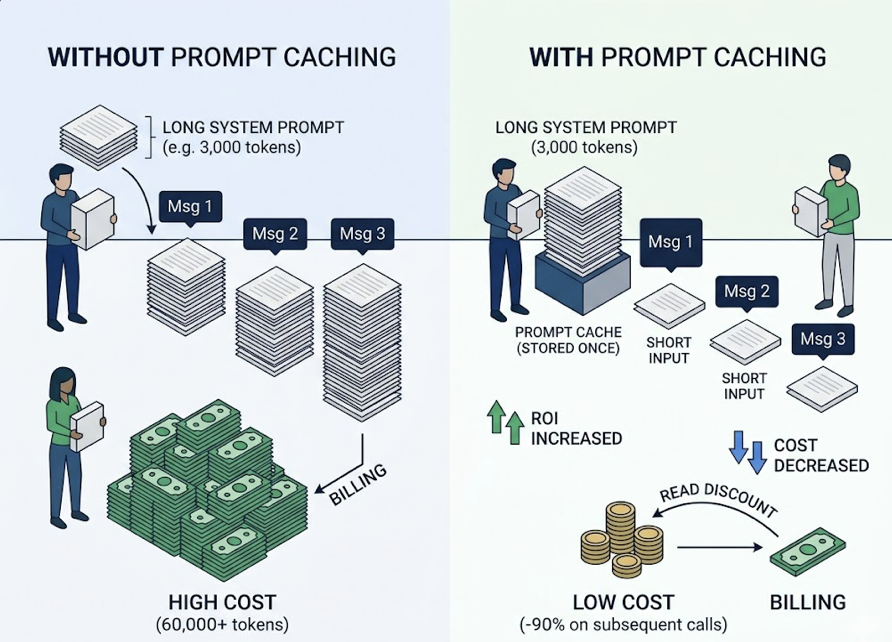
The context window expansion isn’t a technical footnote. A 1-million-token window means V4 can process a full decade of brand financial reports or an entire enterprise documentation site in one pass. It’s no longer skimming. It’s reading.
Why Marketers Are Paying Attention to DeepSeek V4 Now
DeepSeek V4’s global reach grew from 33.7 million monthly active users in January 2025 to 181.6 million by February 2026, a roughly 430% increase year over year.
That growth isn’t evenly distributed. Over 51% of DeepSeek’s monthly active users come from China, India, and Indonesia. If your brand targets any of those markets, or the broader Asia-Pacific region, DeepSeek V4 is no longer optional to monitor. It’s table stakes.
The economic efficiency of V4 is the other driver. DeepSeek V4 Flash is priced at roughly $0.14 per million input tokens, approximately 1/100th the cost of comparable closed-source models. That price point means thousands of third-party applications are integrating DeepSeek as their intelligence layer, from customer support bots to competitive analysis tools.
More AI surfaces. More places your brand can either show up or go missing.
Your Brand Is Already on DeepSeek V4. Just Not How You Think.
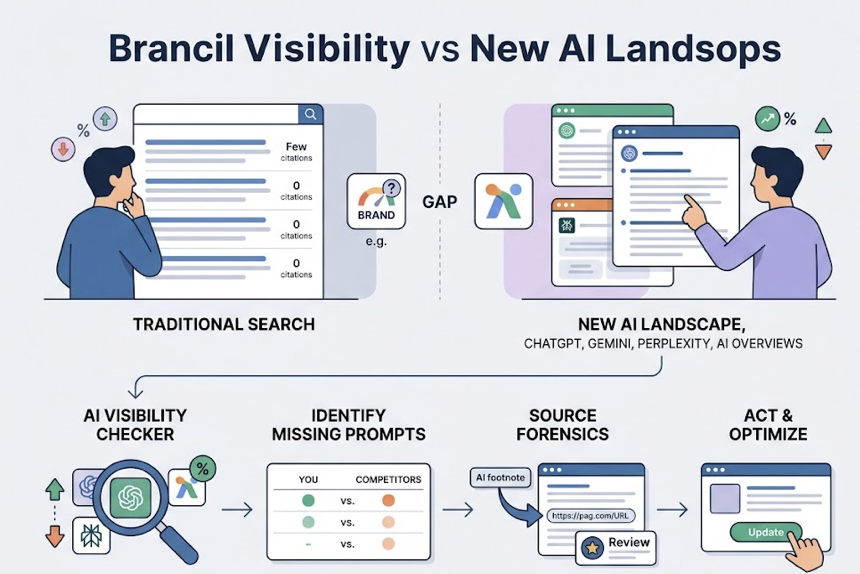
Here’s what most marketing teams don’t realize: AI answers are not search results. They’re active recommendations. Your brand is likely already appearing in DeepSeek’s reasoning pool. Whether it’s being represented accurately is a different question entirely.
Traditional SEO metrics don’t exist in a zero-click AI environment. There are no impressions. There are no clicks. There’s only whether the model selects your brand as evidence, or filters it out.
Research from the report above identifies three specific gaps driving brand invisibility on DeepSeek V4:
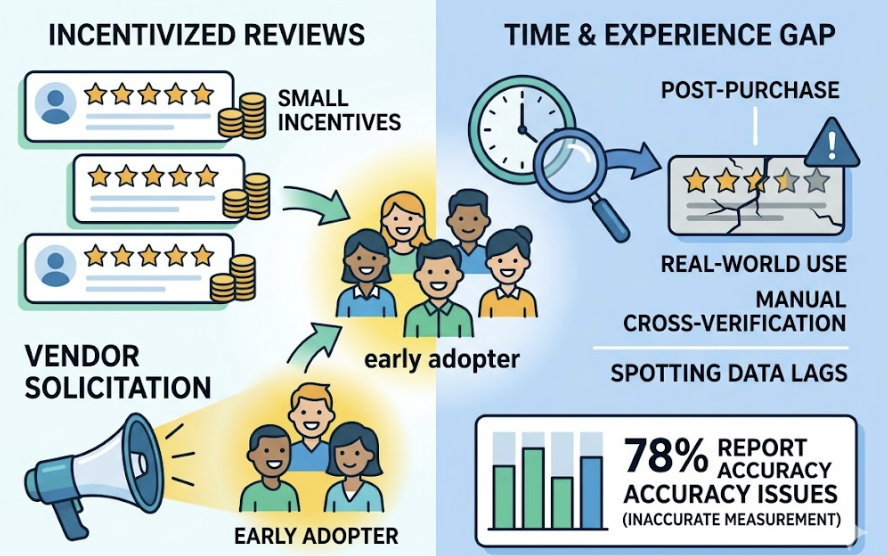
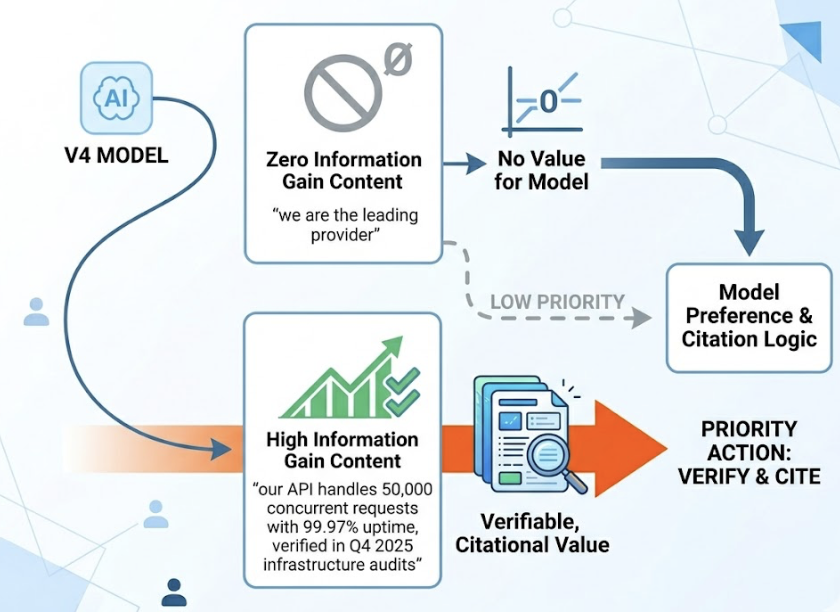
The Information Gain Gap. V4 is trained to prioritize content that provides unique, structured, factual data. If your content replicates information available elsewhere, the model’s reasoning agent treats it as redundant and skips it in favor of the original source. “Me-too” content doesn’t survive V4’s audit.
The Extraction Gap. Content locked in PDFs or behind non-semantic code is difficult for DeepSeek’s Retrieval-Augmented Generation systems to parse into structured verification points. The model can’t extract what it can’t read cleanly.
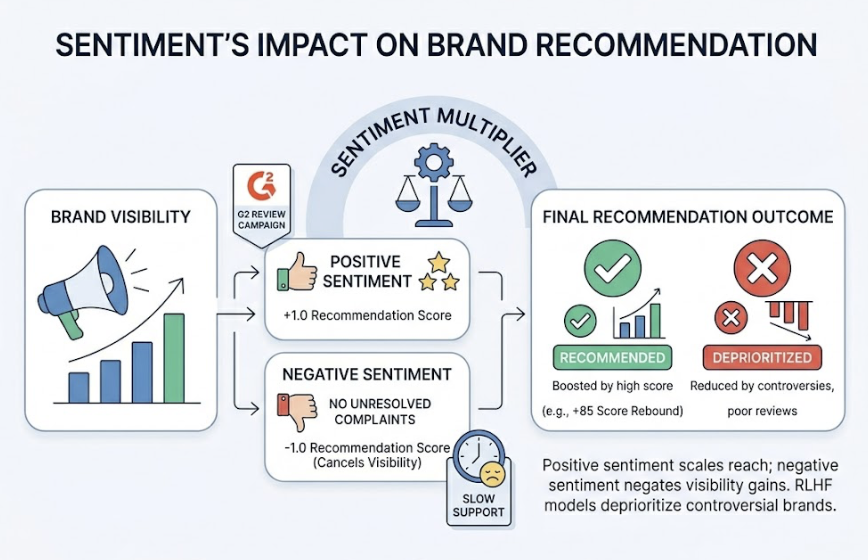
The Persistence Problem. Only 30% of brands maintain consistent visibility across multiple regenerations of the same prompt. A brand that appears in one session may vanish entirely in the next, because V4’s “Thinking” mode can produce different reasoning paths through the same query.
The median enterprise brand is cited in only 3% of the relevant AI answers where it should logically appear. That’s not a ranking problem. That’s a content architecture problem.
What DeepSeek V4’s Reasoning Upgrade Means for Your Content Strategy
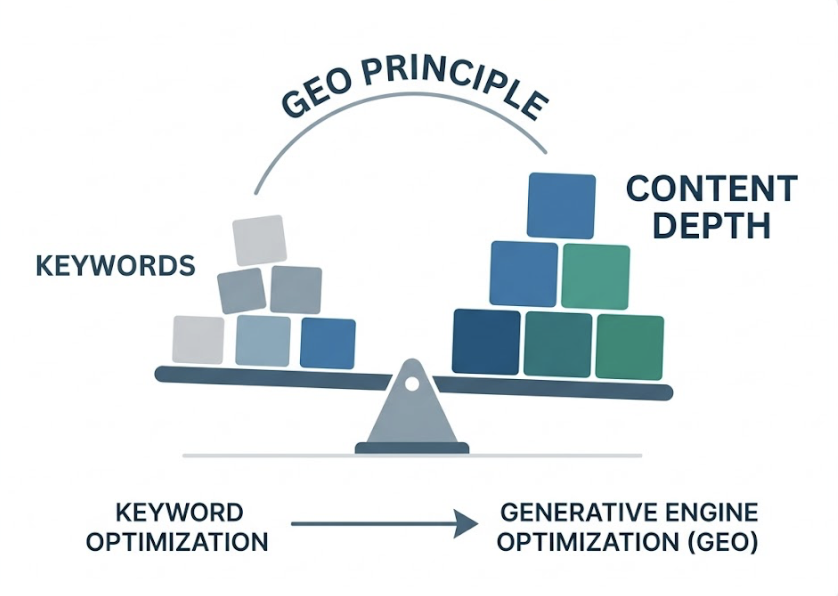
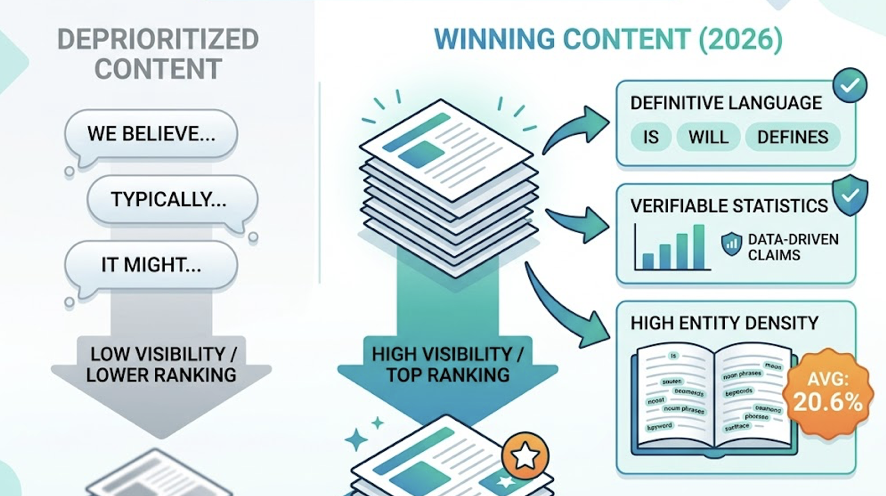
DeepSeek V4’s multi-step reasoning changes what “good content” means. Writing for emotion won’t get you cited. Writing for keyword density won’t either.
V4’s recommendation logic is built around “Information Gain.” The model favors sources that provide raw data, technical documentation, and structured specifications, the kind of content that gives it something new to extract, not something it already knows. A paragraph that says “we are the leading provider” offers zero information gain. A paragraph that says “our API handles 50,000 concurrent requests with 99.97% uptime, verified in Q4 2025 infrastructure audits” gives the model something it can verify and cite.
The strategic shift looks like this:
| Optimization Layer | Old Goal | DeepSeek V4 Goal |
|---|---|---|
| Content goal | Clicks and impressions | Inclusion in reasoning chains |
| Writing focus | Keyword density | Verifiable ground truth |
| Page structure | Engaging narrative | Data-rich specifications |
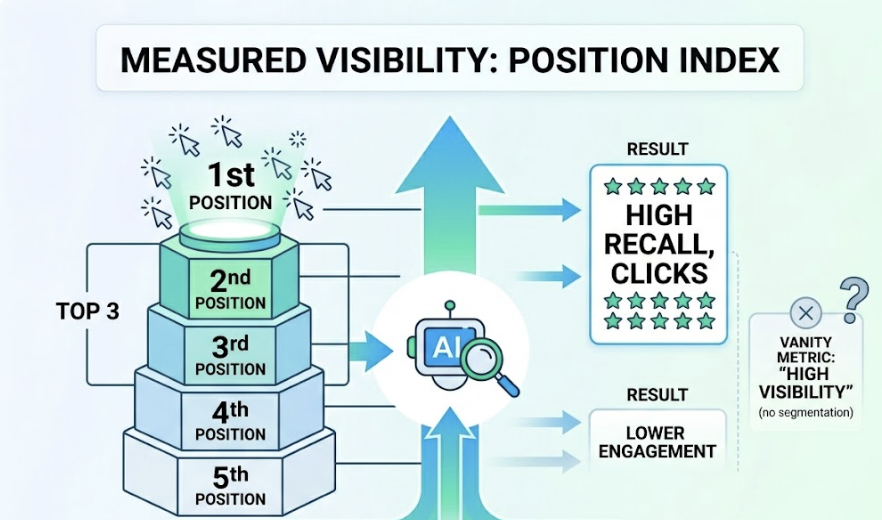
| Success metric | High ranking | Selection as primary evidence |
The “Atomic Answer” strategy is worth implementing now. This means placing a 30-to-60-word direct factual summary at the top of every high-value page, a format that directly supports V4’s “Extract Agent” in converting natural language into independent verification points.
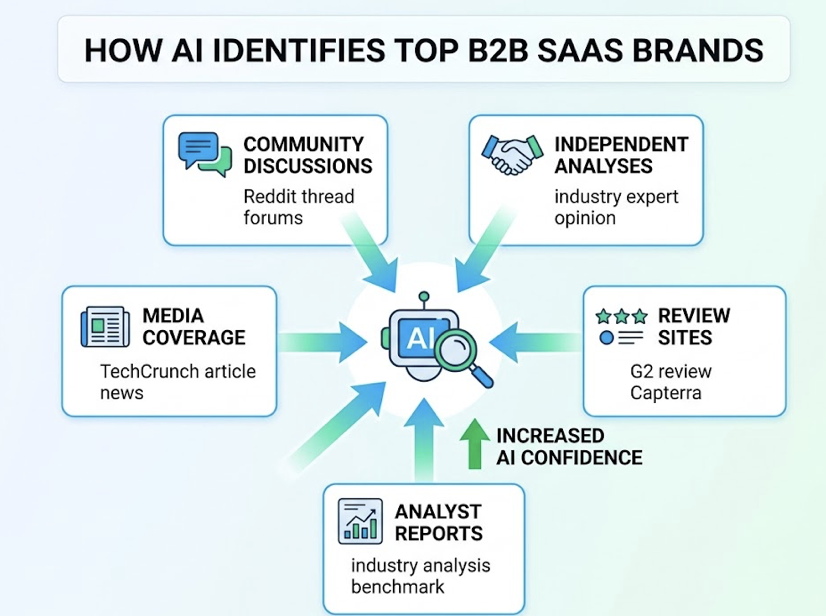
Also worth noting: 82% to 85% of AI citations come from third-party sources like Reddit, industry forums, and academic publications. If your content strategy is focused solely on your owned domain, you’re working with roughly 15% of the available citation surface. The rest of the authority signals DeepSeek uses to validate brand recommendations live off-site.
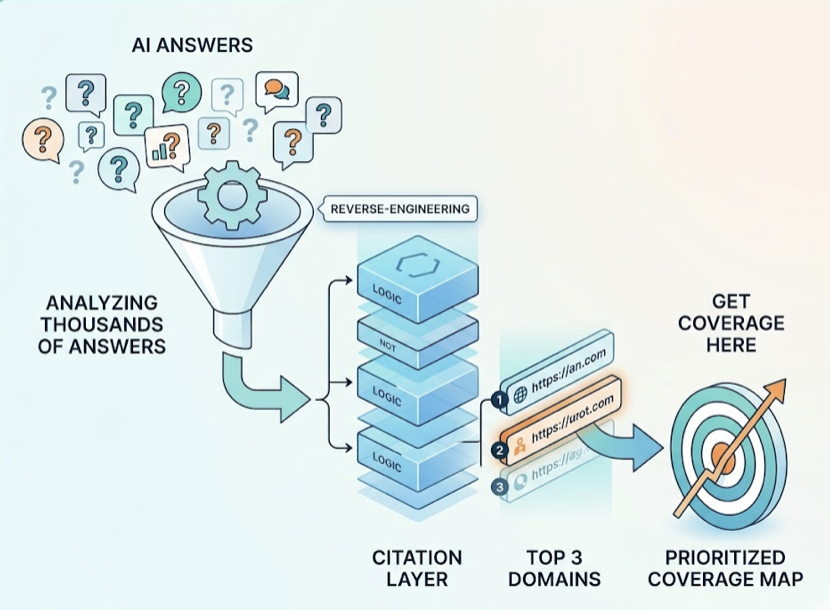
Topify’s Source Analysis feature reverse-engineers the exact URLs and third-party threads DeepSeek cites in your category. That gives you a map of where the model’s authority signals are actually coming from, and where your brand can realistically be planted into that citation network.
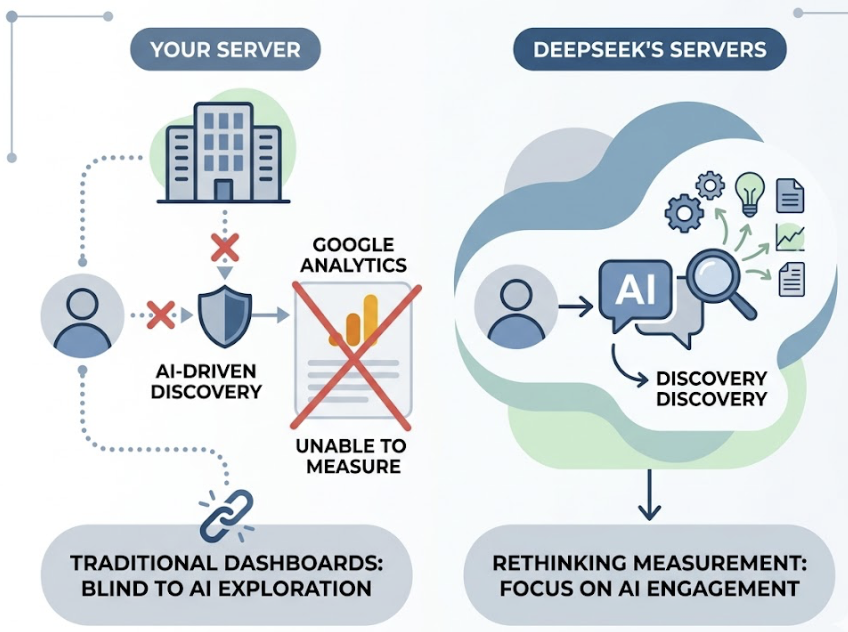
How to Track Your Brand’s Presence on DeepSeek V4
Google Analytics won’t measure this. The interaction happens on DeepSeek’s servers, not yours. Traditional analytics tools are structurally blind to AI-driven discovery, which means if you’re relying on existing dashboards, you’re measuring the wrong channel entirely.
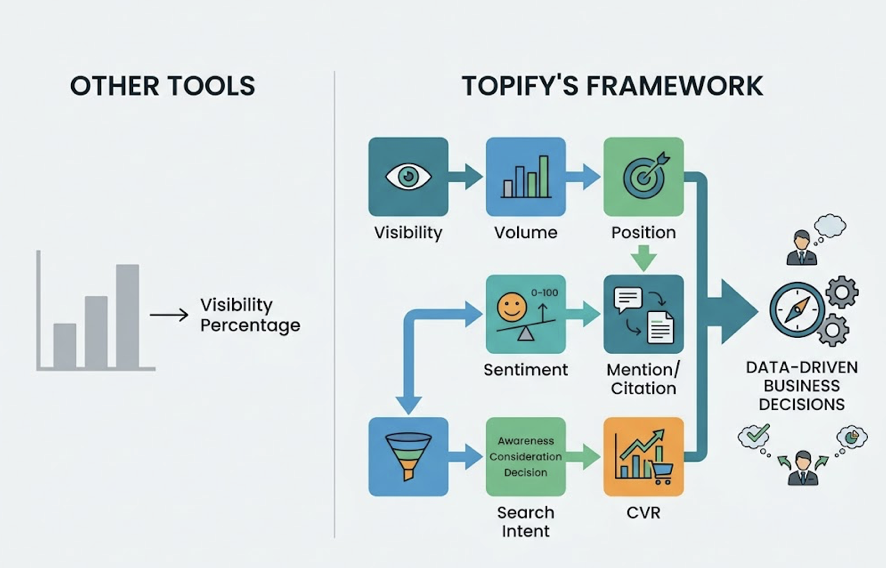
Tracking brand presence on DeepSeek V4 requires a framework built around seven core metrics:
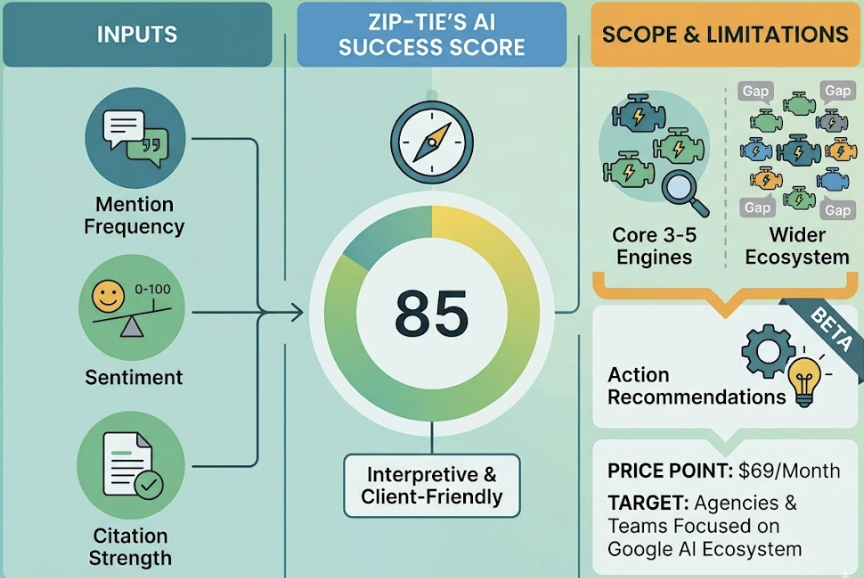
- AI Visibility Score (AVS): The percentage of relevant, high-intent prompts where your brand appears.
- Mention Frequency: How often DeepSeek names your brand without necessarily linking to it.
- Sentiment Polarity: A 0-100 score tracking how favorably the AI characterizes your brand.
- Brand Position Index: Whether your brand is named first in a comparison or buried in a footnote.
- Information Gain Gap: How much unique data your content provides compared to category baseline.
- Citation Rate: How often DeepSeek provides a specific URL back to your brand as a source.
- CVR (Conversion Visibility Rate): Connecting AI mentions to downstream branded search lift or revenue signals.
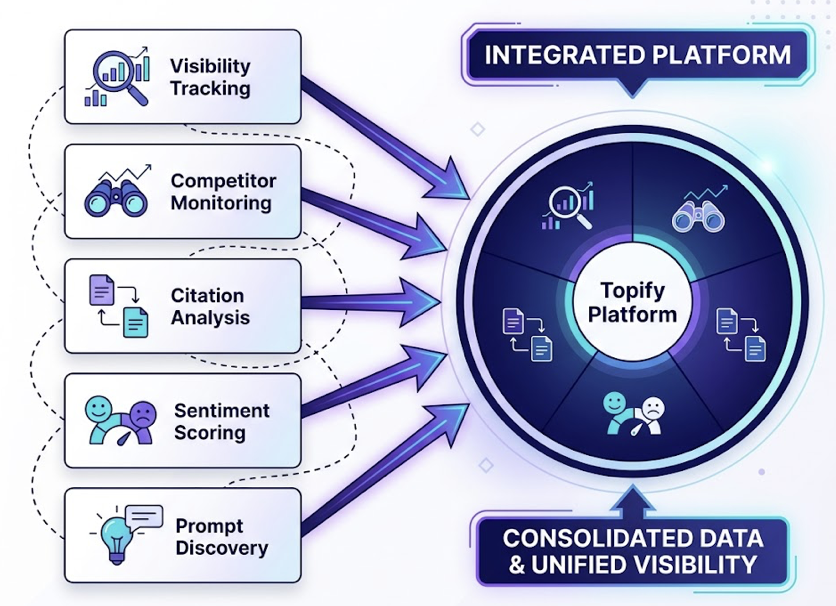
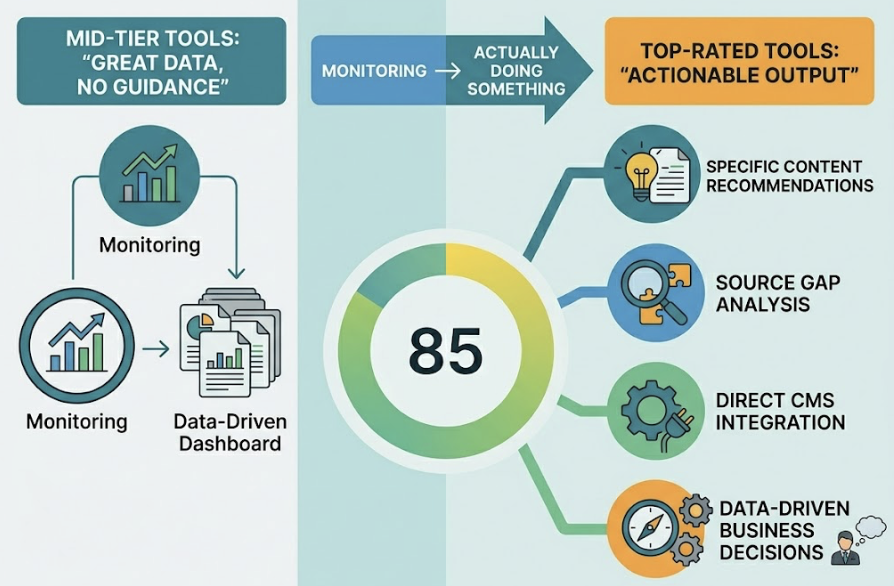
Topify already covers DeepSeek as a tracked platform alongside ChatGPT, Gemini, Perplexity, and others. All seven metrics above are available in a single dashboard, which matters because cross-platform visibility gaps are often where the most actionable insights live.
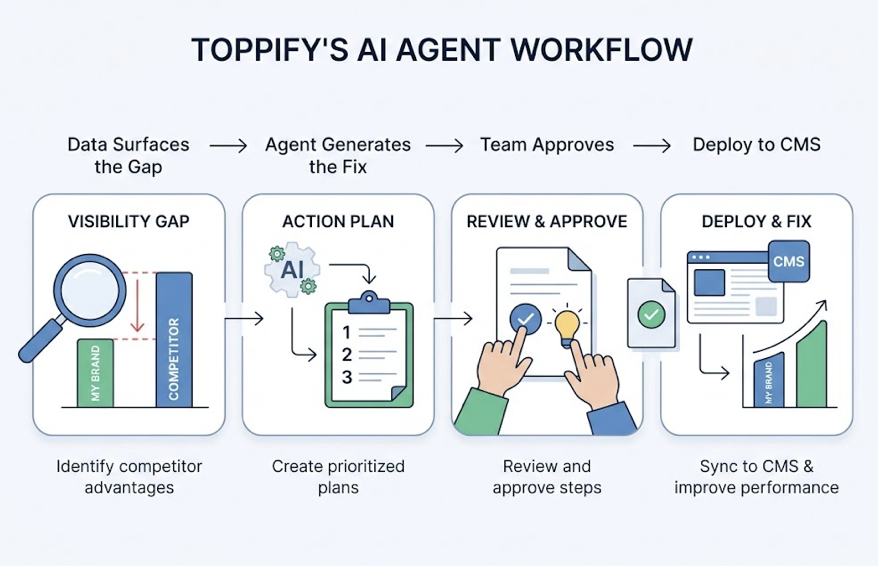
Three steps to get started:
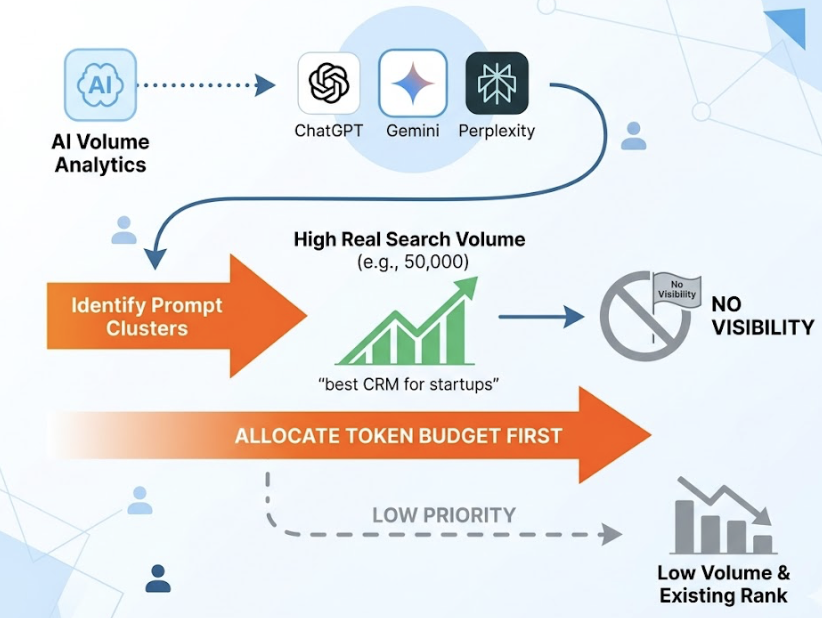
Step 1: Prompt-Level Audit. Identify the top 50 high-intent prompts your buyers use during discovery and evaluation, for example, “How does [your product] compare to [Competitor] for [Use Case]?”
Step 2: Source Analysis. Use Topify to reverse-engineer which external domains DeepSeek V4 is citing to validate claims in your category. That list tells you exactly where to build authority.
Step 3: Continuous GEO Monitoring. Set up automated scanning to track Persistence and Sentiment Drift over time. V4 retrains on new data, so what’s true this month may shift by next quarter.
DeepSeek V4 vs. ChatGPT: Where Should You Focus First?
This is no longer an either/or question. But it is a sequencing question.
| Feature | DeepSeek V4 | ChatGPT (GPT-5.x) |
|---|---|---|
| Primary audience | Asia, developers, researchers | US/EU, generalists, creatives |
| Cost efficiency | Extremely high (1/10 to 1/100) | Premium pricing |
| Reasoning behavior | Transparent, logical, citation-heavy | Fluid, nuanced, conversational |
| Multimodality | Mainly text and images | Advanced voice, video, vision |
| Best use case | Technical B2B, fact-checking queries | Brand storytelling, broad awareness |
Bottom line: if your brand is in a technical category (SaaS, FinTech, engineering) or targets Asia-Pacific markets, DeepSeek V4 should be your primary optimization target in 2026. Its reasoning traces pick up on structured technical documentation more aggressively than ChatGPT’s conversational model.
That said, both platforms are now active discovery channels, and treating them as separate silos leads to blind spots. A cross-platform tracking approach, monitoring visibility scores across ChatGPT, DeepSeek, Perplexity, and Gemini simultaneously, is the only way to see the full picture.
Conclusion
DeepSeek V4 is not just a model update. It’s a signal that the Agentic Era has arrived, where brands are no longer found via keywords but selected through multi-step reasoning chains.
The shift from “search results” to “active recommendations” means brand visibility is now a probability. That probability is shaped by verifiable evidence, information gain, and third-party authority signals. None of those are traditional SEO metrics.
Marketers who aren’t monitoring their DeepSeek presence are flying blind in a discovery channel that now reaches 350 million users and powers thousands of third-party applications. The mandate for 2026 is clear: integrate DeepSeek into your AI visibility monitoring, or risk being filtered out of the reasoning chains that drive tomorrow’s buying decisions.
Topify tracks brand visibility across DeepSeek, ChatGPT, Gemini, Perplexity, and more, with all seven core GEO metrics in one place.
FAQ
What is DeepSeek V4 and why does it matter for marketing?
DeepSeek V4 is an open-source AI model released in early 2026 with advanced multi-step reasoning capabilities and a 1-million-token context window. It matters for marketing because it functions as an active recommendation engine, not just a search tool, and it reached 350.8 million monthly web visits by March 2026. Brands that aren’t tracking their presence on it are missing a significant and growing discovery channel.
Does DeepSeek V4 affect my brand’s SEO?
Not directly in the traditional sense, but it does affect brand discovery. DeepSeek V4 operates in a zero-click environment where there are no impressions or click-through rates to measure. Instead, the relevant metric is whether the model cites your brand as a trusted source in its reasoning chain. This falls under Generative Engine Optimization (GEO), which is distinct from traditional SEO but increasingly critical for brands targeting technical audiences or Asia-Pacific markets.
How do I know if my brand appears in DeepSeek answers?
Google Analytics and traditional SEO tools can’t tell you. You need a dedicated AI visibility platform. Topify tracks brand mentions, sentiment, citation rates, and position across DeepSeek and other major AI platforms in real time. The fastest starting point is a prompt-level audit: identify the top 50 queries your buyers use during discovery, then run them through a tracking tool to see where and how your brand currently appears.