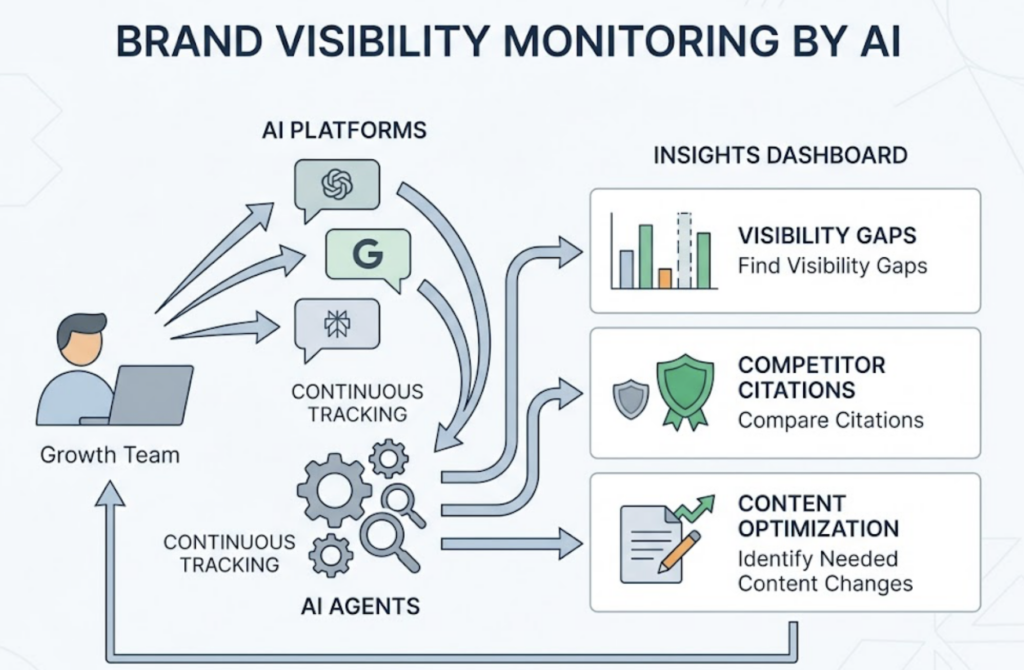
Most AI visibility tools stop at the dashboard. They show you where your brand appears, which platforms mention you, and how sentiment trends over time. Then they hand the work back to you.
Topify AI Agent is built around a different premise. Instead of delivering a report and waiting, the agent monitors your AI search performance, reasons through the data, and executes strategy on your behalf. That shift, from insight to action, is what separates an agentic system from a tracking tool.
What Topify AI Agent Actually Is
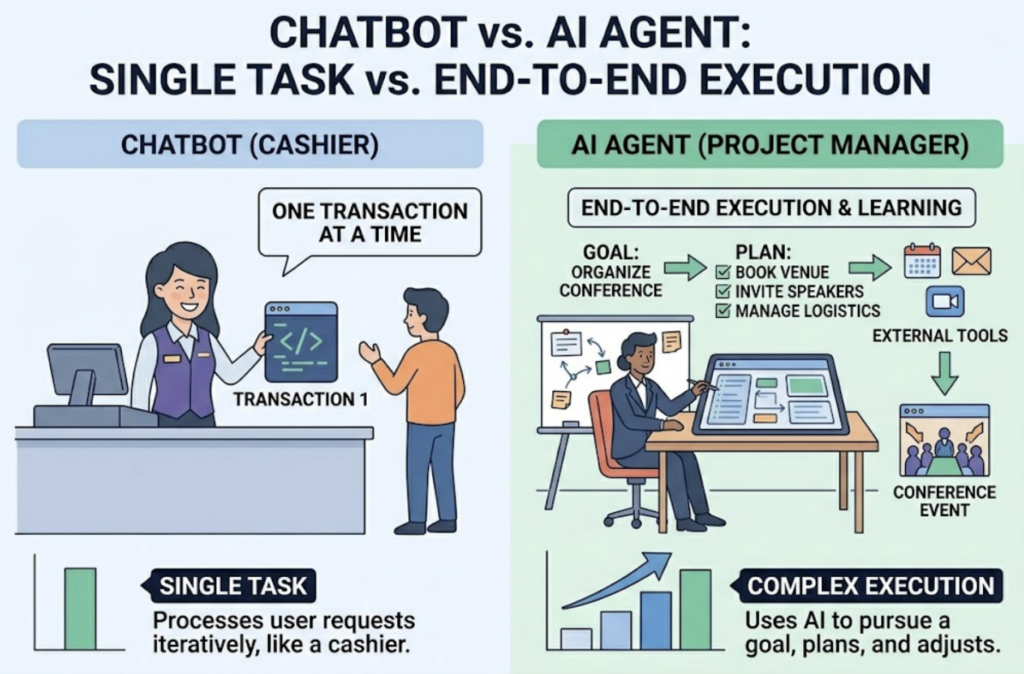
The term “AI agent” gets applied to a lot of things in 2026, from simple chatbots to fully autonomous workflows. Topify AI Agent sits firmly in the latter category.
At its core, it runs a continuous loop: monitor brand performance across AI platforms, analyze what the data means for your visibility, and execute GEO and AEO strategies without requiring manual input at every step. You define the goal in plain English. The agent handles the rest.
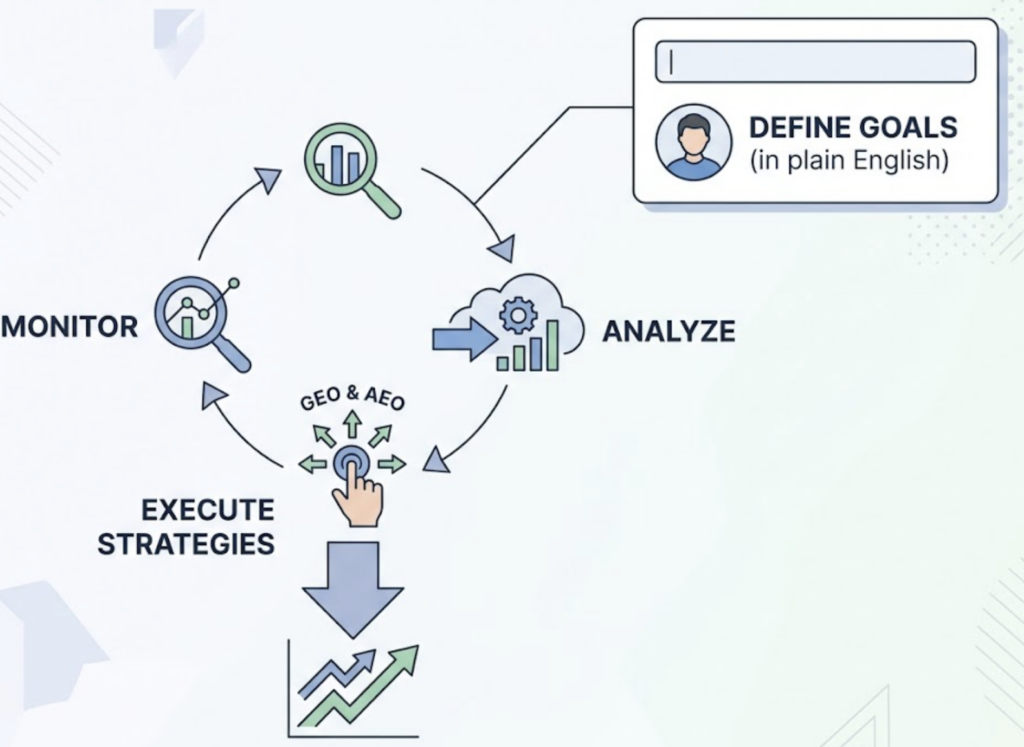
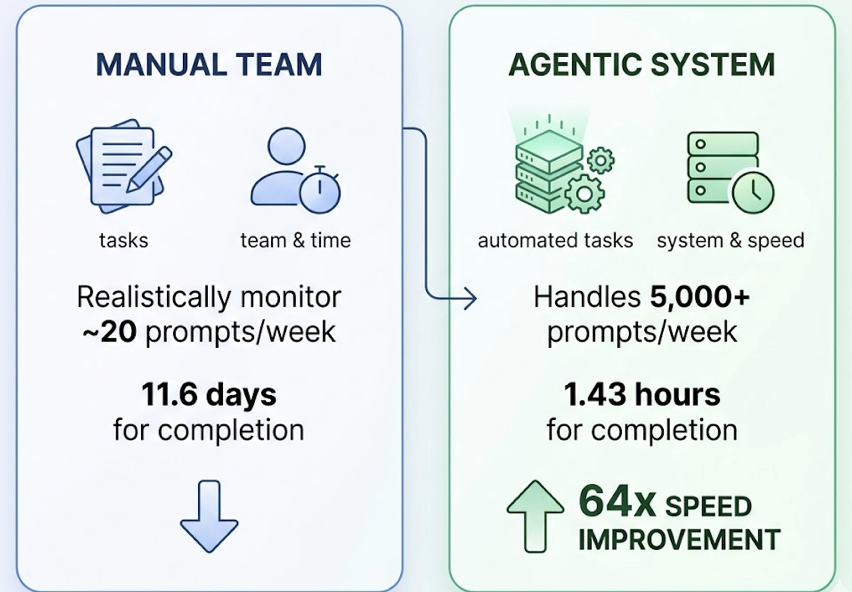
That’s a meaningful distinction. Most teams using GEO tools spend hours translating data into action. Topify AI Agent compresses that cycle into a single operation.
The Search Environment That Made This Necessary
To understand why an agentic approach matters, it helps to see what the search landscape actually looks like right now.
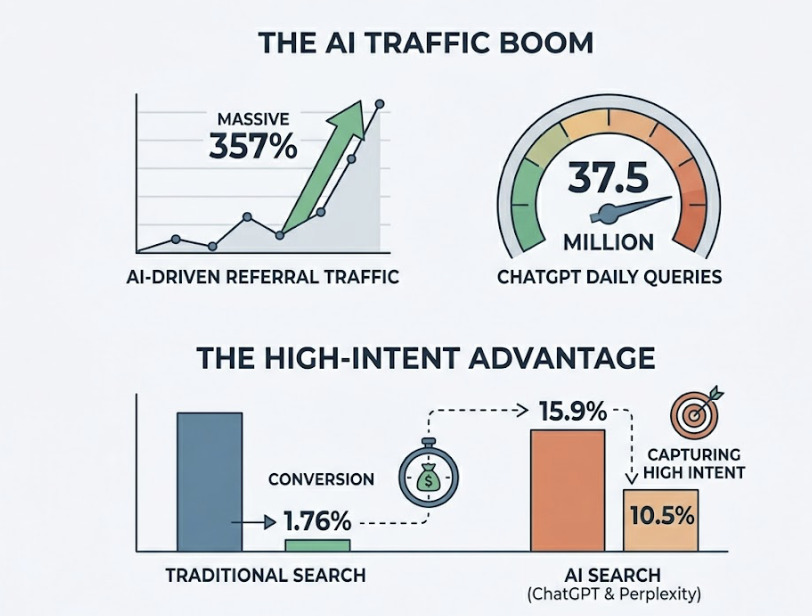
ChatGPT now exceeds 900 million weekly active users, and Google AI Overviews appear in over 25% of all searches. More telling: approximately 65% of all searches now end without a click. The user got their answer directly from the AI, and no one’s website got the visit.
Traditional organic conversion rates run around 2.8%. Visitors arriving via LLM citations convert at 14.2%, roughly five times higher. LLM referral traffic is up 357% year over year.
The math is clear. The question is how to consistently appear in those AI answers at scale.
How Topify AI Agent Works: Monitor, Reason, Act
The agent operates on a three-stage cycle that runs continuously in the background.
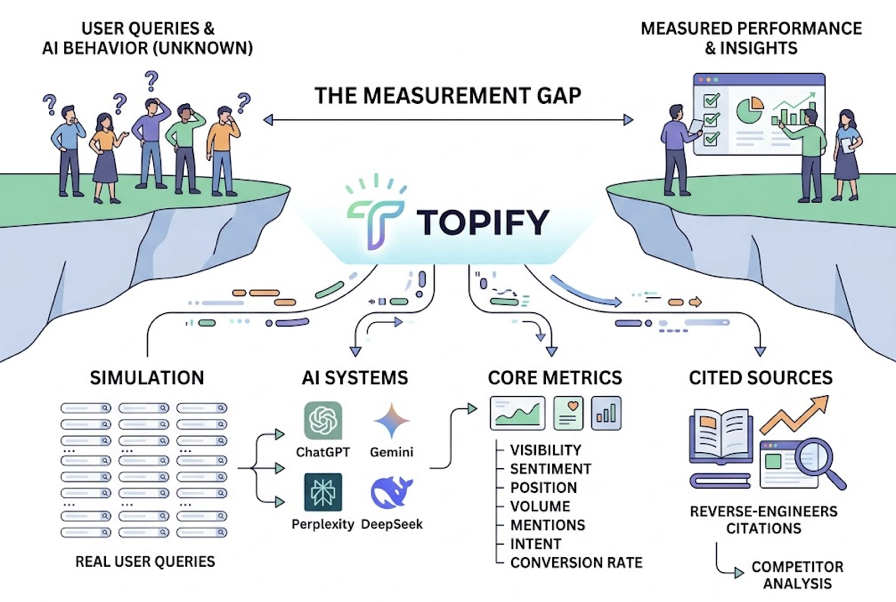
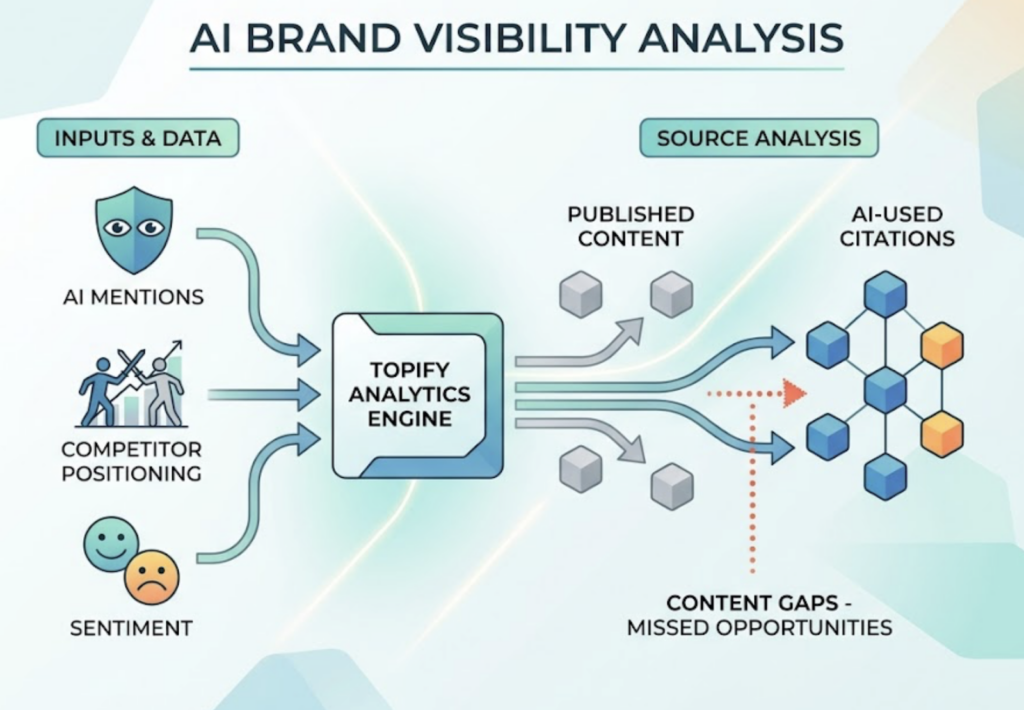
Monitor. Topify tracks brand performance across ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and Google AI Overviews. It measures seven core metrics: visibility, sentiment, position, volume, mentions, intent, and CVR. The agent systematically sends prompts across these platforms and captures how each one responds to queries in your category.
Reason. Raw data gets processed through Topify’s analytics layer. One key capability here is Dark Query discovery. These are high-intent conversational prompts that users type into AI engines but that don’t appear in tools like Semrush or Ahrefs. Research shows that AI visibility correlates far more strongly with brand mentions (0.664) than with traditional backlinks (0.218). Dark queries are often where the real visibility gap lives.
Act. Once the agent identifies content gaps, citation opportunities, or competitive threats, it generates an execution plan and deploys it. You review the proposed strategy and launch with one click. No manual workflow required.
Most tools give you the first two stages. Topify AI Agent closes the loop on the third.
5 Ways Topify AI Agent Boosts Your Content
The agent’s impact on content is specific. Here’s where it shows up in practice.
Prompt Discovery That Surfaces What You’re Missing
The agent continuously uncovers high-volume AI prompts in your category that you’re not currently winning. It runs a 10-step query fan-out pipeline, from multi-seed research to a 0-100 citability score, to prioritize which opportunities deliver the most visibility gain. This is especially useful for catching dark queries before competitors do, since those queries won’t show up in any traditional keyword research tool.
Source Analysis to Close Citation Gaps
Topify tracks exactly which domains AI platforms cite when they answer questions in your category. If your site isn’t among them, the agent identifies what content you’d need to produce or update to become citable. Sites with over 32,000 referring domains are 3.5x more likely to be cited by ChatGPT than those with fewer than 200. Source analysis tells you where you stand and what to fix first.
Competitor Benchmarking in Real Time
The agent monitors which competitors are being recommended in your category, how their sentiment scores compare to yours, and how their position is shifting week over week. You don’t have to go looking for this. If a competitor gains ground in a specific prompt cluster, you’ll know.
Content Generation Tied to GEO Data
Content created through Topify is generated from actual AI visibility data, not generic topic research. That means the articles, FAQ entries, and structured data it produces are designed to address the specific prompts where your brand needs to appear.
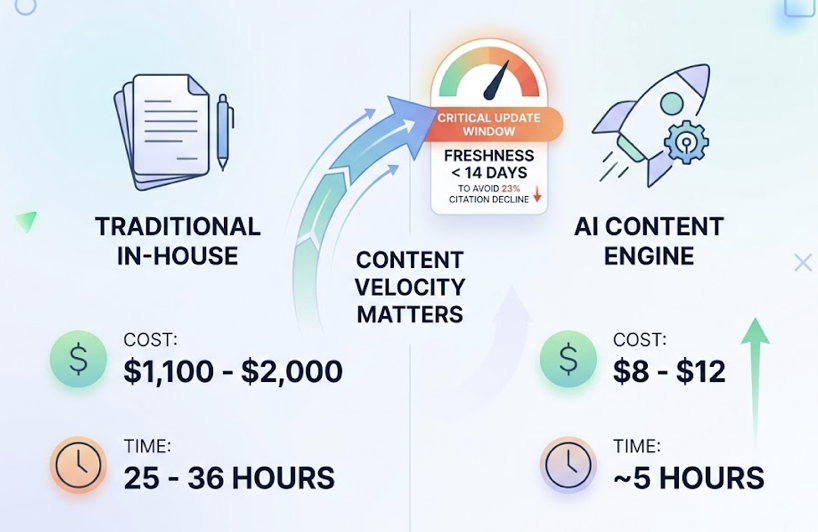
The cost difference is significant. AI content engines bring per-article costs down to roughly $8-12, compared to the $1,100-$2,000 range for in-house production. A team producing three articles per week through the platform invests around five hours total, versus 25-36 hours through traditional processes. One thing worth noting: pages not updated within 14 days show a 23% decline in AI citation frequency. Content velocity matters here more than it does in traditional SEO.
Seven-Metric Performance Tracking
Topify measures what actually matters in AI search: AI Brand Mention Rate, AI Share of Voice, AI Citation Rate, Answer Inclusion Rate, Sentiment Distribution, Dark Query Capture, and LLM Visitor Conversion Rate. These go well beyond what any traditional rank tracker provides and give teams a real performance signal tied to business outcomes, not proxy metrics.
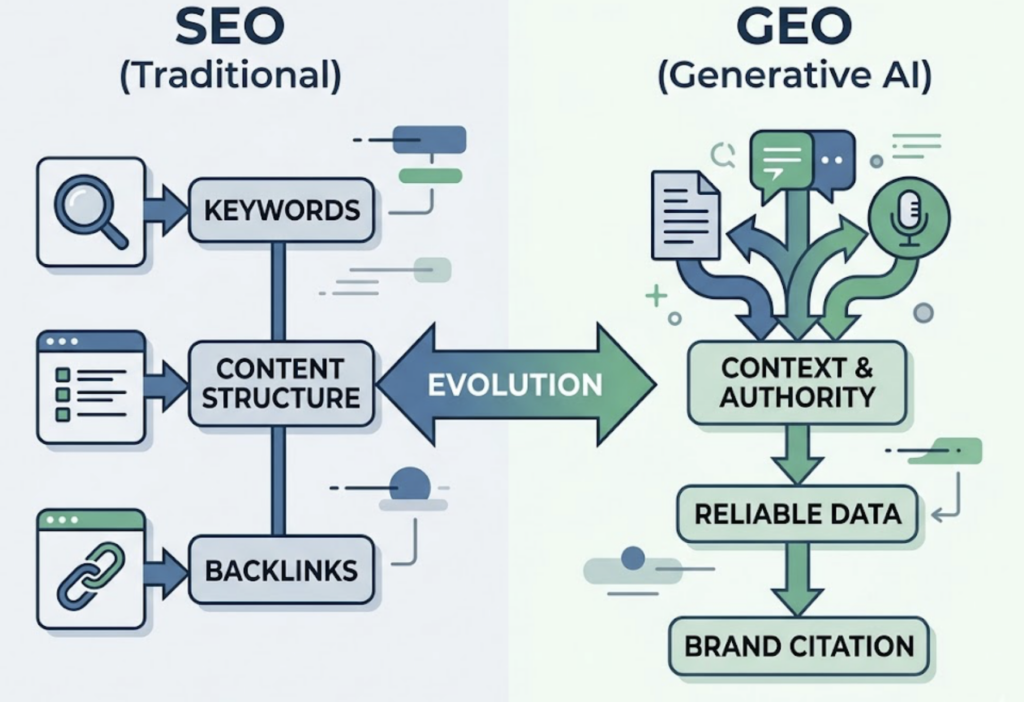
AEO vs. GEO: What Topify AI Agent Optimizes For
These two strategies are often conflated, but they target different outcomes.
GEO (Generative Engine Optimization) focuses on long-term citation presence in AI-generated answers. The academic definition, developed by researchers at Princeton and Georgia Tech, emphasizes content depth, accuracy, and citation-worthiness. It’s about shaping how AI models synthesize your brand across future responses, not just capturing a snapshot ranking.
AEO (Answer Engine Optimization) is faster and more tactical. It targets featured snippets, voice assistant responses, and zero-click results. AEO content uses Q&A pairs, direct answer sections, and structured schema to make it easy for AI to select your content as the primary source for a given query.
Topify AI Agent works across both simultaneously. It optimizes for immediate citation inclusion through AEO-style content structure, while building the authority and content depth that determines long-term generative visibility through GEO. The two strategies reinforce each other. As of early 2026, 94% of enterprise digital leaders plan to increase their AEO/GEO investments, with around 12% of digital marketing budgets now going toward AI visibility.
Who Gets the Most Out of Topify AI Agent
The agent scales differently depending on how you use it, but three profiles tend to see the clearest returns.
Marketing agencies managing multiple client brands benefit from the agent’s ability to run parallel monitoring and execution across accounts. Instead of manually querying AI platforms for each client, the agent handles it from a single platform with consistent methodology.
In-house marketing and growth teams without dedicated GEO analysts can use the agent to close the expertise gap. You don’t need a team of specialists to run a structured AI visibility program. The agent replaces a significant amount of the analytical and execution labor that would otherwise require hiring or outsourcing.
SaaS and AI product companies competing for discovery in a crowded category need consistent presence in AI recommendations. The agent ensures your product appears in the prompts where buyers are making decisions, not just in traditional search results where you’ve already invested.
Topify’s plans start at $99/month for the Basic tier, which includes 100 prompts, tracking across ChatGPT, Perplexity, and AI Overviews, 50 content generations, and 4 seats. The Pro plan at $199/month scales to 250 prompts and 100 content generations for larger teams. Enterprise plans start at $499/month and include dedicated account management and custom configurations.
Conclusion
Most content strategies stall not at the insight stage, but at execution. You know what AI platforms are saying about your brand. You see where competitors are being cited instead of you. Then comes the manual work of translating that into content, distribution, and tracking, which rarely keeps up with how fast AI recommendation patterns shift.
Topify AI Agent is designed to close that gap. By running the monitor-reason-act cycle continuously, it turns AI visibility data into deployed strategy without requiring a team to manage every step. In a landscape where 65% of searches end without a click and LLM conversion rates outpace organic by 5x, that execution speed is the actual competitive advantage.
Get started with Topify to see where your brand currently stands in AI search.
FAQ
Q: What’s the difference between Topify AI Agent and a standard AI content tool?
A: Most AI content tools generate text from a prompt you provide. Topify AI Agent starts by monitoring how AI platforms respond to queries in your category, identifies where your brand is missing or underrepresented, and then generates content specifically designed to close those gaps. The input is AI visibility data, not a blank brief.
Q: Does Topify AI Agent support AEO optimization specifically?
A: Yes. The agent optimizes for both AEO and GEO at the same time. On the AEO side, it helps structure content for direct inclusion in featured snippets and zero-click results using Q&A formats and structured schema. On the GEO side, it builds the citation authority and content depth that shapes long-term inclusion in generative responses.
Q: Which AI platforms does Topify AI Agent monitor?
A: Topify tracks brand performance across ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and Google AI Overviews, covering the major platforms where target audiences are searching across global markets.
Q: How quickly does Topify AI Agent show results?
A: AEO improvements, such as structured schema and direct-answer content, typically show up in AI responses within days to a few weeks. GEO results, which involve building citation authority across the broader web, tend to compound over one to three months. The agent’s continuous monitoring means you’ll see signal changes as they happen rather than waiting for a monthly report.