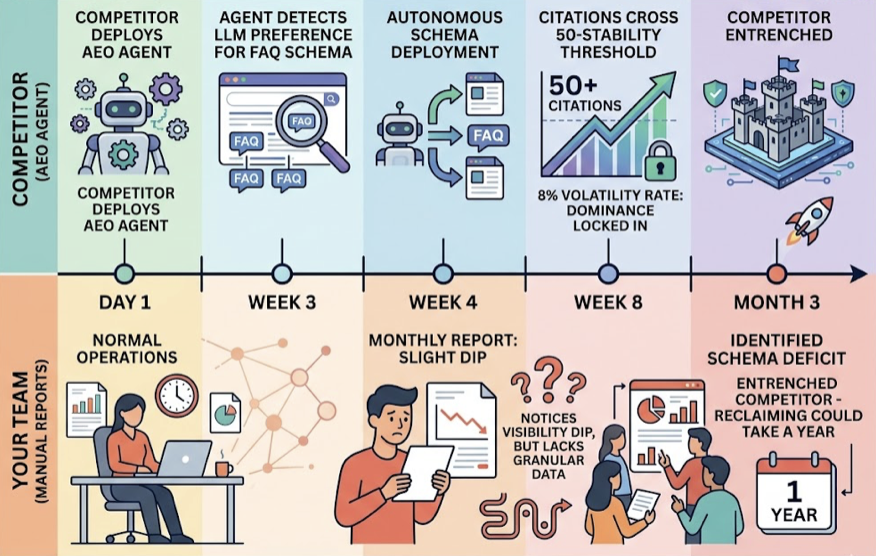
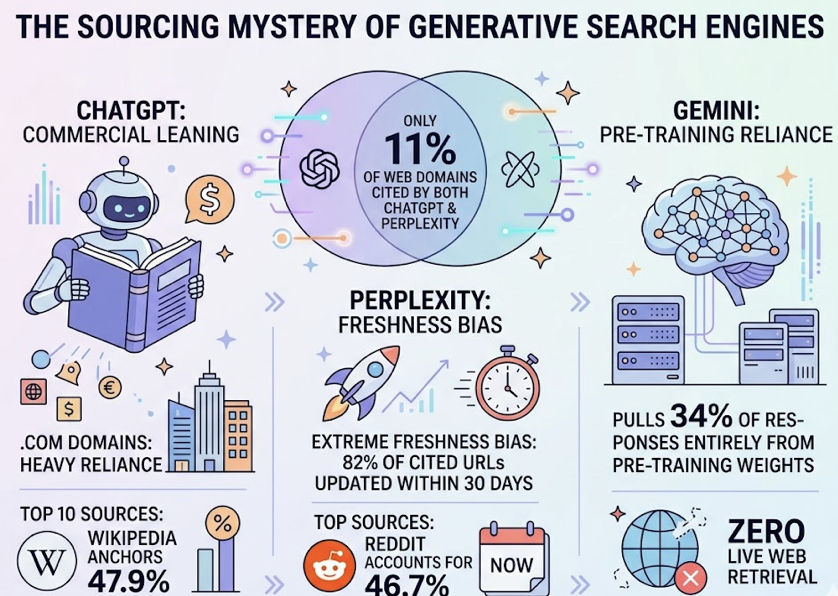
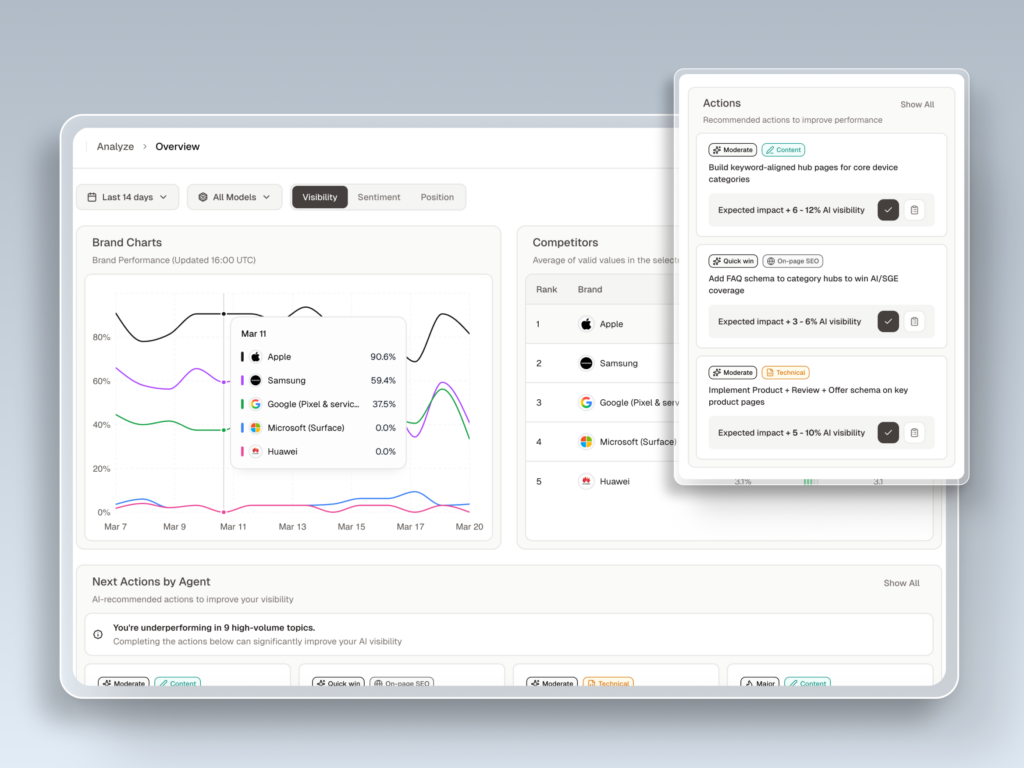
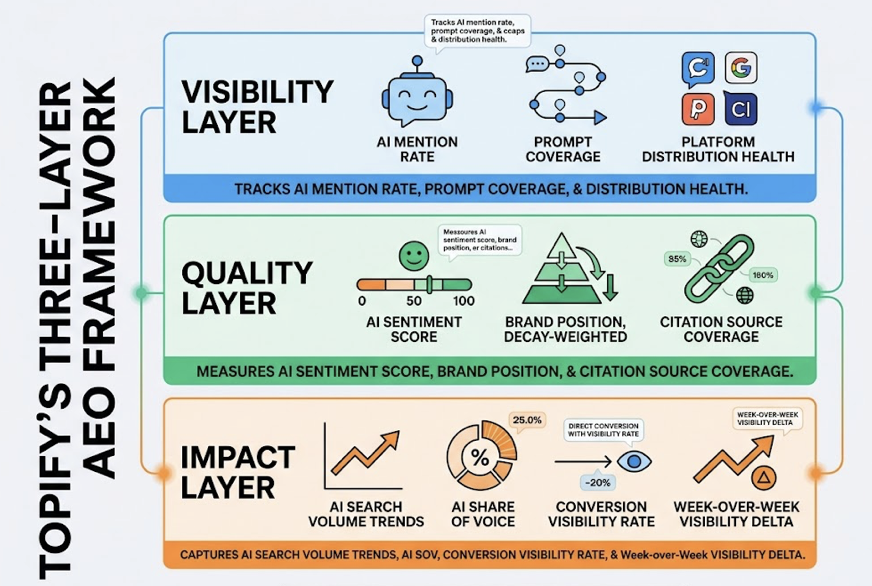
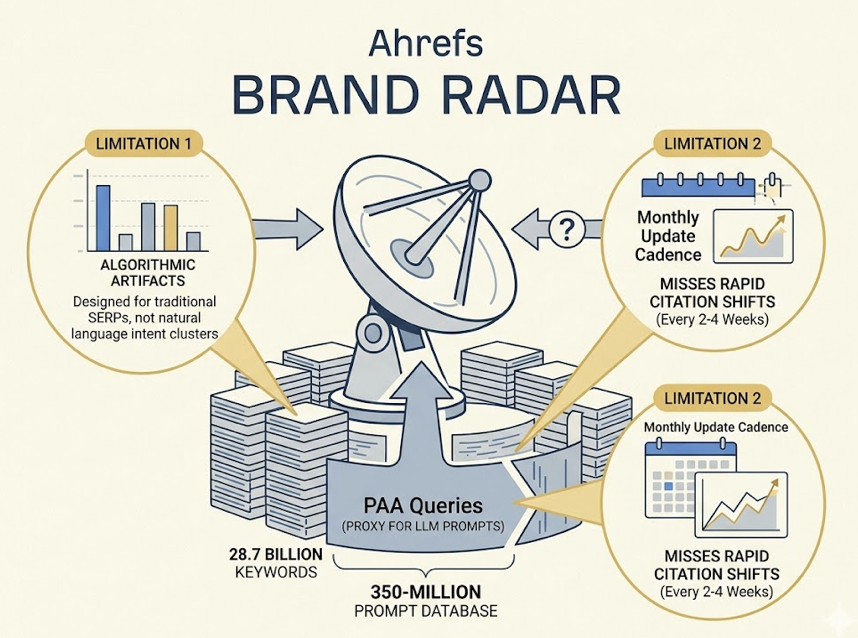
Your domain authority is 72. Your keyword rankings are climbing. Your backlink profile is stronger than it’s been in years. None of that tells you whether ChatGPT just recommended your competitor to someone asking for the exact product you sell.
That’s the gap. Traditional SEO metrics were built to measure visibility in index-based search engines. But when a user asks Perplexity or Gemini for a recommendation, the AI doesn’t return a list of blue links. It generates an answer, pulls from a handful of sources, and cites them. If your brand isn’t in that citation list, you’re invisible to a growing share of search traffic. LLM citation tracking is how you find out where you stand.
Every LLM Answer Has a Bibliography. Most Brands Don’t Know What’s in It
LLM citation tracking is the systematic process of identifying, monitoring, and analyzing the URLs and domains that large language models surface as sources in their generated answers. Think of it as backlink analysis, but for AI search engines instead of Google.
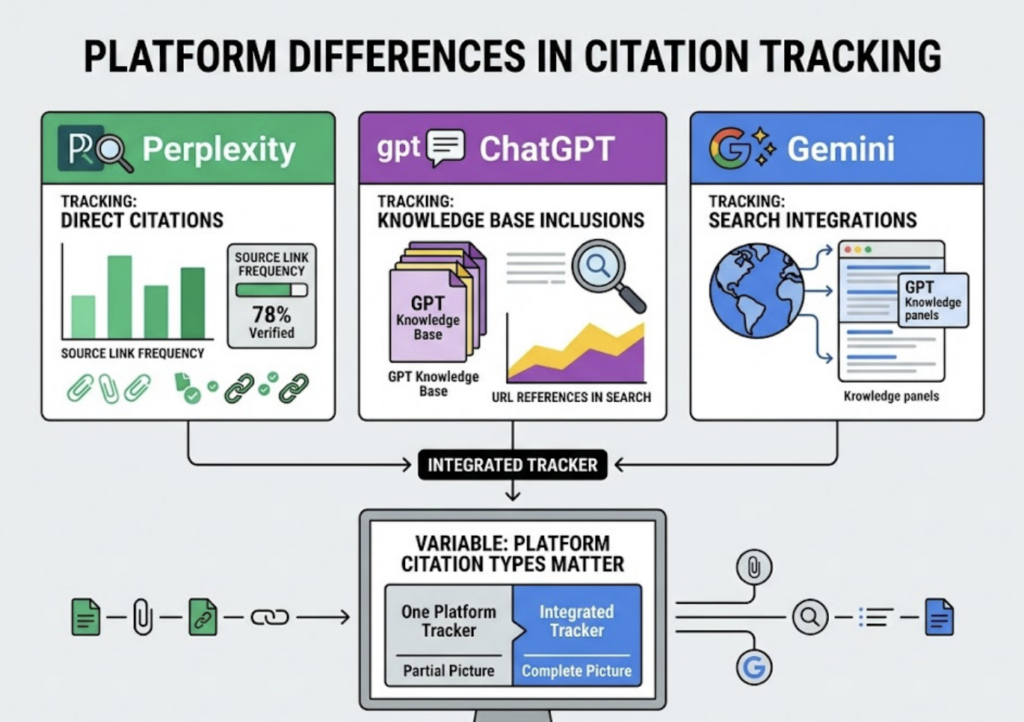
The distinction matters because AI platforms handle citations in fundamentally different ways. Perplexity displays explicit footnotes with clickable URLs. Gemini surfaces “source bubbles” alongside its responses. ChatGPT, depending on the mode and plugin configuration, may or may not expose its retrieval sources directly.
Then there’s the implicit layer. Some of what an LLM “knows” comes from training data, not real-time retrieval. A brand can influence an AI’s response without a visible citation, simply because the model internalized that brand’s content during training. That’s harder to measure, but it’s real.
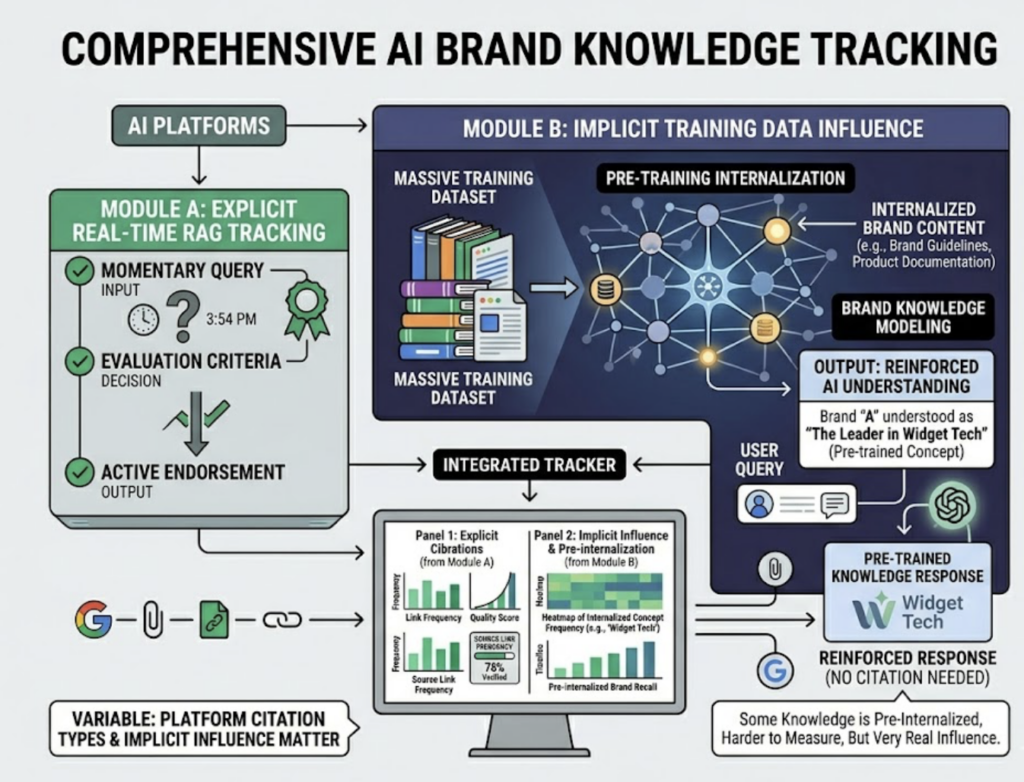
The bottom line: every AI-generated answer is a synthesized summary of a retrieval corpus. Brands absent from that corpus are absent from the answer.
How LLM Citation Tracking Actually Works
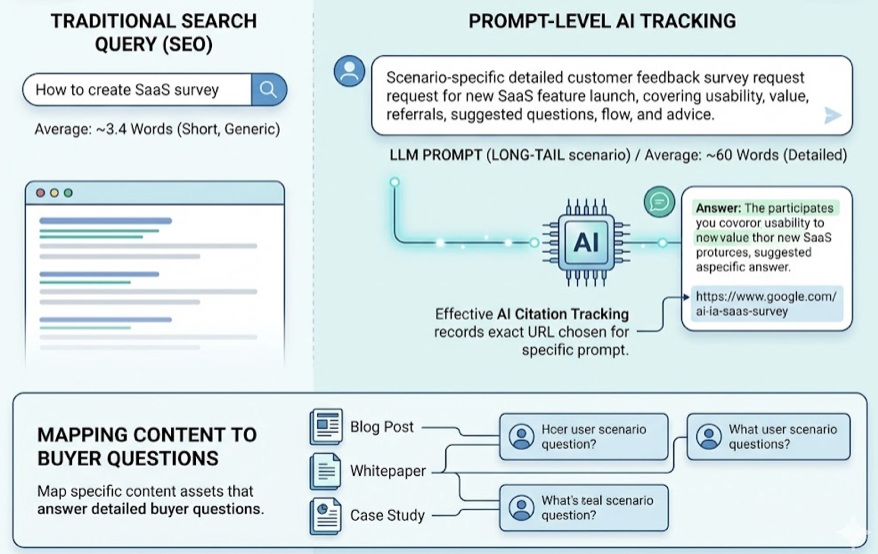
Most AI search engines today run on a framework called Retrieval-Augmented Generation, or RAG. The workflow breaks into four stages:
- Query. A user submits a question or prompt.
- Retrieval. The system searches a live index (typically powered by Bing, Google Search API, or a proprietary crawler) to pull relevant, real-time documents.
- Generation. The LLM synthesizes the retrieved content into a coherent answer.
- Citation. The model maps portions of its generated text back to source URLs and surfaces them as references.
This is a different game from traditional search as a service. Google ranks pages. AI search engines cite them. The distinction reshapes what “winning” looks like.
| Metric | Traditional SEO | LLM Citation Tracking |
|---|---|---|
| Primary Goal | High organic rank | High citation frequency |
| Trust Signal | Backlinks and DA | Content relevance and entity authority |
| Visibility Format | Blue links on a SERP | Inline references in AI answers |
| Optimization Lever | Keywords and link building | Structured data, entity clarity, citation-ready content |
A page with a DA of 40 can outperform a DA-80 competitor in AI citations if its content is more concise, more specific, and better structured for LLM retrieval.
What LLM Citation Tracking Measures (and What It Misses)
Four metrics form the core of any LLM citation tracking framework:
Citation Share is the percentage of AI-generated responses, for a given keyword set, that cite your domain versus competitors. If ChatGPT answers a question about your category 100 times and cites your brand 12 times, your citation share is 12%. This is the closest equivalent to “share of voice” in AI search.
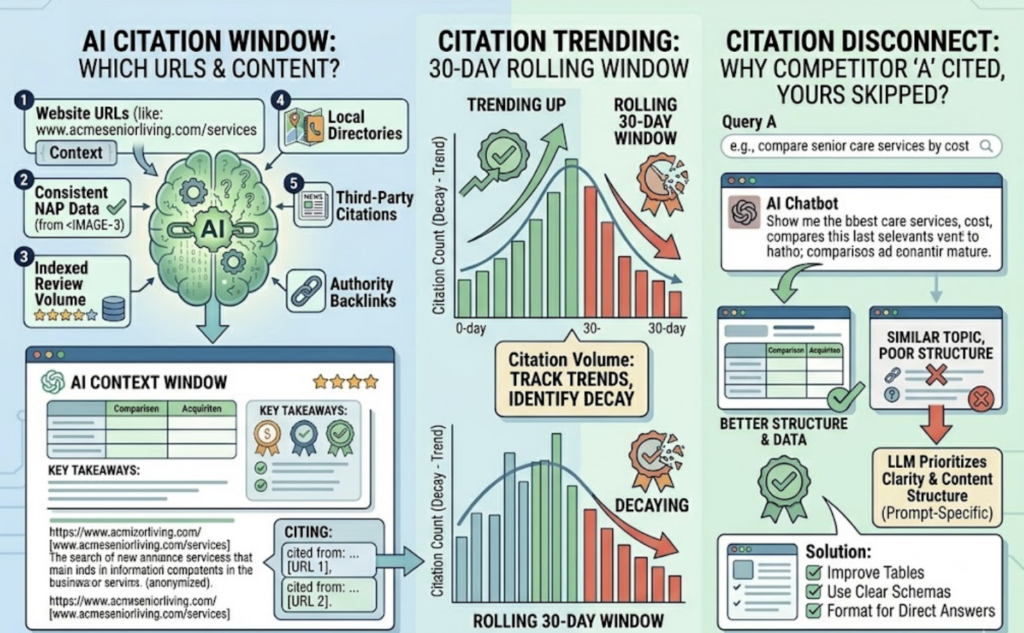
Citation Frequency tracks how often your domain appears across response sets over time. A single snapshot means nothing. What matters is the trendline: are you gaining or losing citations week over week?
Citation Position measures where you fall in the citation list. Being the first source cited (the “primary source”) carries significantly more weight than being the fifth. Users scan AI answers the same way they scan SERPs: top-down.
Source Context evaluates whether the citation is favorable, neutral, or comparative. Getting cited in a “top alternatives to [your competitor]” answer is different from getting cited as the recommended solution.
That said, LLM citation tracking has limits. Not every AI answer exposes its sources. Model updates can shift citation patterns overnight. And the implicit influence of training data remains difficult to quantify. Treating these metrics as directional signals rather than absolute truth is the right approach.
5 Common Mistakes That Break Your LLM Citation Tracking
Most teams that attempt LLM citation tracking make at least one of these errors:
1. Platform monoculture. Monitoring only ChatGPT while ignoring Perplexity, Gemini, and DeepSeek. Each platform has different retrieval behaviors, different source preferences, and different citation formats. A brand that’s cited heavily by Perplexity might be completely absent from Gemini’s answers for the same query.
2. Metric confusion. Treating backlink count or domain authority as a proxy for AI citations. An LLM’s retrieval system often favors concise, fact-dense pages with clear entity markup over high-DA pages loaded with boilerplate. The signals are different.
3. Ignoring citation context. Volume without sentiment is a vanity metric. Getting cited 50 times means nothing if 30 of those citations appear in “alternatives to [your brand]” comparisons or in negative review summaries.
4. Sampling bias. Spot-checking a handful of prompts manually and calling it “tracking.” AI responses vary by model version, user history, and even time of day. Without systematic, automated monitoring across hundreds of prompts, your data is unreliable.
5. No competitive baseline. Tracking your own citations without comparing them to competitors is like measuring your page speed without knowing the industry benchmark. You need relative data to know whether 12% citation share is strong or weak.
How to Build an LLM Citation Tracking Strategy That Scales
Moving from occasional spot-checks to a repeatable, scalable system requires five steps.
Start with a baseline audit. Identify the prompts and topics where your brand should be cited. Run those prompts across ChatGPT, Perplexity, Gemini, and other relevant platforms. Record which domains appear, how often, and in what position. This is your starting point.
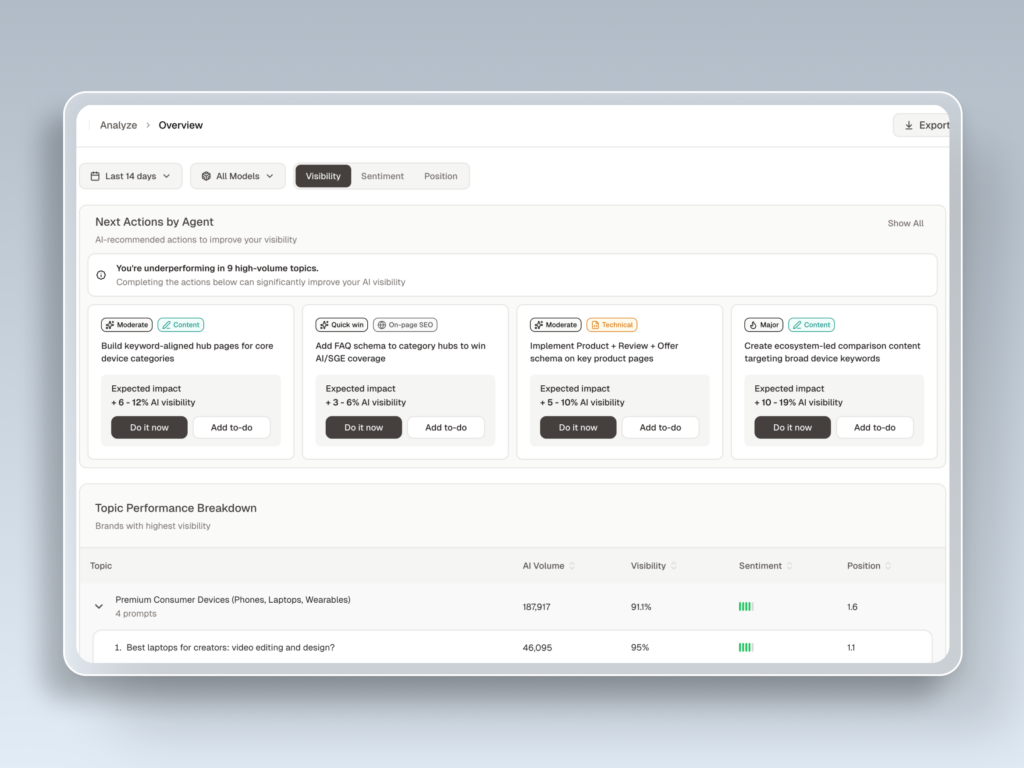
Topify‘s Source Analysis feature handles this at scale. It tracks exactly which domains and URLs each AI platform cites for your target prompts, so you don’t have to run queries manually. The output is a citation map: who’s getting cited, how often, and where your gaps are.
Run a citation gap analysis. Compare your citation profile against competitors. Where are they consistently cited and you’re not? These gaps typically point to content you haven’t published, entities you haven’t defined, or sources you haven’t earned.
Topify’s Competitor Monitoring automates this. It detects competitors, benchmarks Visibility, Sentiment, and Position side by side, and flags the specific prompts where you’re losing citation share.
Optimize content for citation-readiness. AI retrieval systems prefer content that’s granular, well-structured, and rich in verifiable facts. That means schema markup for brand entities, concise answer-format paragraphs, and authoritative sourcing. The goal is to make your content easy for a RAG pipeline to parse, extract, and cite.
Set up automated monitoring. Citation patterns shift as models update, new competitors publish content, and AI platforms refine their retrieval logic. A monthly manual check won’t catch these changes. Topify’s dashboard integrates citation metrics into your regular reporting cycle, with alerts when citation share drops or a new competitor enters the picture.
Iterate based on data. Use Topify’s AI agent to identify which content changes drove citation gains, which prompts shifted, and where to invest next. Define your goals in plain English, review the proposed strategy, and deploy with a single click.
The Tools That Make LLM Citation Tracking Possible
Effective LLM citation tracking requires capabilities that traditional rank trackers don’t offer. Three features separate useful tools from noise:
Multi-platform coverage. Any tool worth using must track citations across ChatGPT, Perplexity, Gemini, and other major AI engines simultaneously. Tracking a single platform gives you a partial, often misleading picture.
Domain and URL granularity. You need to see which specific pages are being cited, not just which domains. A competitor might be winning citations with one well-structured landing page while the rest of their site is ignored.
Competitive benchmarking. Real-time visibility into why a competitor is winning citation share for a specific query. Is it their content structure? Their entity authority? A specific source they’ve earned that you haven’t?
Topify covers all three. Its Source Analysis reverse-engineers exactly which domains and URLs AI platforms cite. Visibility, Sentiment, and Position tracking provide the full picture. And the platform covers every major market: ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and others.
For teams exploring LLM citation tracking before committing to a paid platform, Topify also offers a set of free AI visibility tools that provide an initial read on where your brand stands.
Pricing starts at $99/month for the Basic plan (100 prompts, 9,000 AI answer analyses, ChatGPT/Perplexity/AI Overviews tracking). The Pro plan at $199/month scales to 250 prompts and 22,500 analyses. Enterprise plans start at $499/month with a dedicated account manager.
Conclusion
The SEO playbook that got your brand to page one of Google doesn’t tell you whether AI is recommending you or your competitor. LLM citation tracking fills that gap. It measures what backlinks and DA can’t: whether your content is being retrieved, synthesized, and cited by the AI engines that are rapidly becoming the default way people search.
Start with one category keyword. Run it across three AI platforms. See who gets cited and who doesn’t. That 10-minute exercise will tell you more about your AI visibility than a month of traditional SEO reporting. And when you’re ready to scale it, the tooling exists to make it automatic.
FAQ
Q: What is LLM citation tracking?
A: LLM citation tracking is the process of monitoring which URLs and domains large language models (like ChatGPT, Perplexity, and Gemini) cite as sources in their AI-generated answers. It measures how often, how prominently, and in what context your brand appears as a reference when AI answers questions related to your industry.
Q: How does LLM citation tracking work?
A: It works by systematically querying AI search engines with relevant prompts, then recording which sources the AI cites in its responses. Specialized platforms automate this across multiple AI engines, tracking citation share, frequency, position, and sentiment over time. The underlying mechanism relies on RAG (Retrieval-Augmented Generation), where AI models pull from live web indexes and cite the sources they used.
Q: How do you measure LLM citation tracking?
A: The four core metrics are Citation Share (your percentage of citations vs. competitors for a keyword set), Citation Frequency (how often you appear over time), Citation Position (where you rank in the citation list), and Source Context (whether the citation is favorable, neutral, or comparative). Tools like Topify track these automatically across platforms.
Q: How much does LLM citation tracking cost?
A: Costs depend on scope. Manual tracking is free but unreliable at scale. Dedicated platforms like Topify start at $99/month (Basic), $199/month (Pro), and $499+/month (Enterprise). The investment typically pays for itself when teams can identify and close citation gaps that were previously invisible.