You search your own brand name on ChatGPT. Then you try the category question your customers actually ask: “What’s the best tool for [your space]?” A competitor shows up. You don’t. You try it again with slightly different phrasing. Same result.
That’s not a glitch. Nearly 26% of leading global brands are entirely absent from AI-generated recommendations, even when they dominate traditional search results. The gap isn’t closing on its own. And the longer a competitor holds that position, the harder it becomes to take it back.
AI brand visibility isn’t accidental. Here’s what’s actually blocking you, and what fixes it.
ChatGPT Doesn’t Work Like Google. That’s the Whole Problem.
Most brands assume AI search works the way web search does: publish content, get indexed, get found. It doesn’t.
ChatGPT generates answers from two sources. The first is its parametric knowledge, which is information baked into the model’s weights during training. This is the AI’s long-term memory, a static snapshot of the internet built from hundreds of gigabytes of text data. If your brand didn’t have a meaningful digital footprint before the model’s training cutoff, you effectively don’t exist in this layer.
The second source is real-time retrieval, often called RAG (Retrieval-Augmented Generation), where ChatGPT Search pulls live web results via Bing to supplement its base knowledge. But even here, the model doesn’t cite everything it finds. Research shows ChatGPT only cites roughly 15% of the pages it pulls into its context window. The other 85% of retrieved content is processed and discarded without attribution.
The result is a “winner-take-all” model. While Google serves ten organic results per page, a typical AI response names 3 to 7 brands at most. Getting into that shortlist is significantly harder, and once a competitor claims a spot, they benefit from a self-reinforcing cycle: more citations build more authority in the model’s internal weights, which leads to more citations.
5 Reasons Your Brand Isn’t Showing Up in ChatGPT
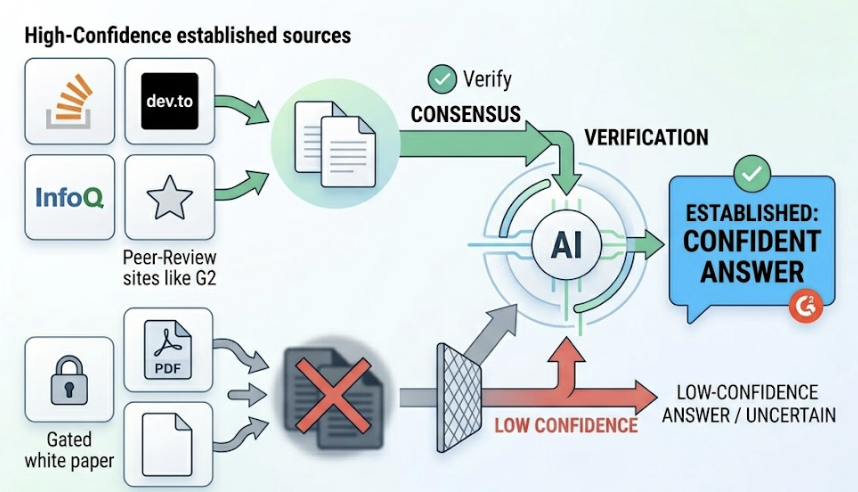
You Don’t Have Enough Third-Party Validation
AI models are trained to recognize consensus. A brand’s own website claiming it’s the industry leader carries almost no weight. What matters is whether credible third parties are saying it.
A striking 85% of non-paid AI citations come from earned media, not brand-owned content. Sources like Wikipedia (which accounts for approximately 27% of citations across major AI platforms), Forbes, TechCrunch, G2, and industry review sites act as “trust anchors.” They tell the model that the brand has been verified by sources it already trusts. Without that coverage, the AI has no credible chain of evidence to draw from.
Your Content Is Structured for Google, Not for AI
Traditional SEO encourages narrative storytelling, long introductions, and building toward a conclusion, strategies designed to keep humans engaged and reduce bounce rate. AI crawlers work differently. They’re scanning for the most direct answer as efficiently as possible.
Content that buries its key claims in long paragraphs, lacks semantic structure, or doesn’t implement Schema markup (FAQPage, HowTo, Product) creates extraction friction. The AI moves on to a competitor’s page where the answer appears cleanly in the first 200 words after a heading. The structure of your content is not a UX concern; it’s a visibility decision.
Competitors Have Claimed the High-Authority Nodes
AI search citations aren’t distributed evenly across the web. Just 50 domains supply 28.9% of all AI Overview citations, and competitors who have secured placements on those domains, through “best of” lists, Reddit threads, or analyst roundups, occupy the nodes that the model returns to repeatedly.
This is what makes the gap compound over time. Every citation a competitor earns reinforces their position in the model’s training signal. You’re not just behind; you’re watching the distance increase.
Your Content Doesn’t Match What People Actually Ask AI
There’s a significant gap between traditional keyword research and real AI prompt behavior. The average AI query is 23 words long, far more specific and conversational than a typical Google search.
Someone asking ChatGPT isn’t typing “CRM software.” They’re asking something like, “What CRM works best for a 40-person B2B sales team that needs Salesforce integration and GDPR compliance?” If your content addresses the broad category but not the specific constraints, use cases, and persona-level details embedded in those prompts, the AI won’t surface you as a relevant match.
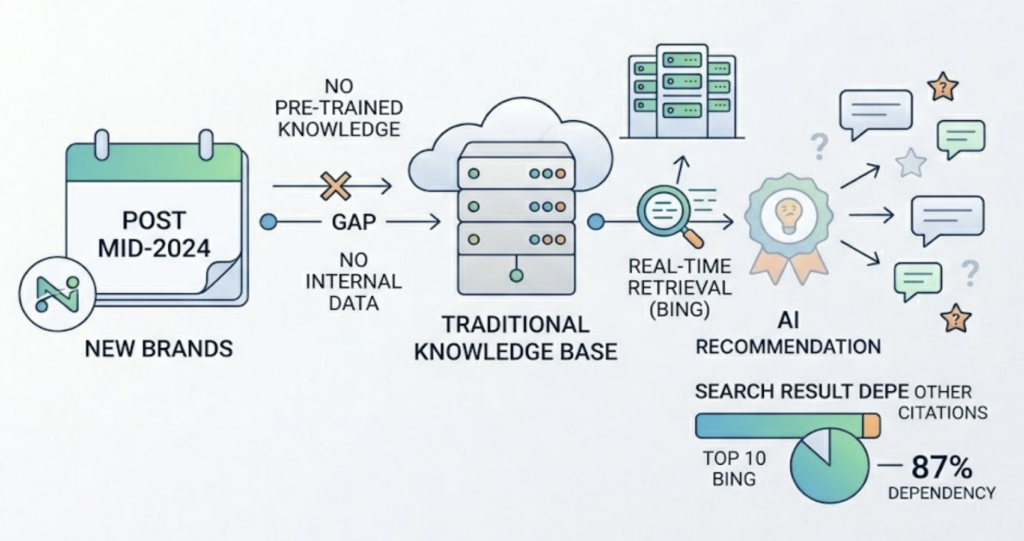
Your Brand Postdates the Model’s Training
New brands, recently renamed companies, or products that pivoted significantly after mid-2024 face a structural disadvantage. The AI’s internal knowledge layer simply hasn’t been trained on them. These brands must rely entirely on real-time retrieval, which is more volatile and closely tied to current Bing rankings. Research indicates that 87% of ChatGPT Search citations match the top 10 Bing results, making traditional search authority still relevant, but insufficient on its own.
What “AI Brand Visibility” Actually Measures
The instinct is to ask: “Does ChatGPT mention us?” That’s the wrong question, or at least an incomplete one.
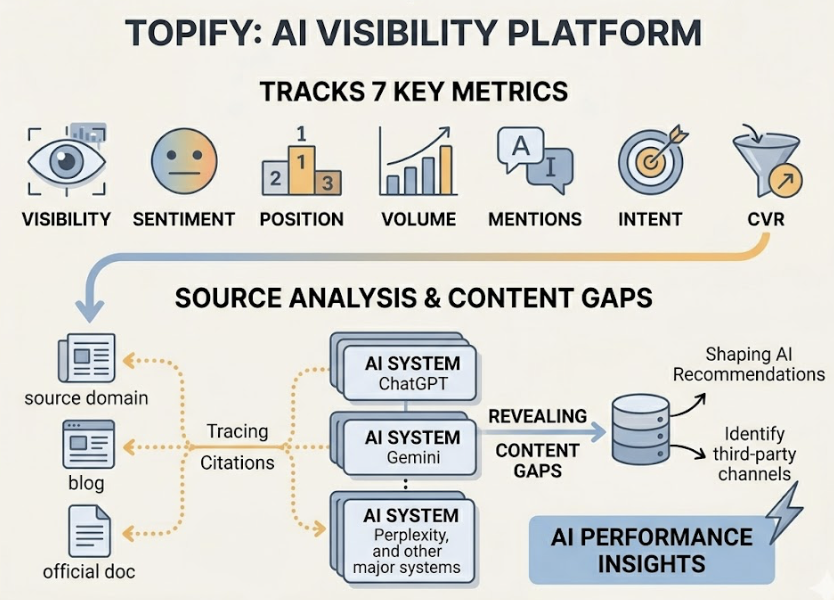
AI brand visibility is a measurable system of performance indicators that go well beyond a binary yes/no. The key metrics are:
| Metric | What It Measures |
|---|---|
| Brand Mention Rate | % of relevant prompts where the brand appears |
| Recommendation Rate | % of prompts where the AI actively endorses the brand |
| Share of Model (SOM) | Brand mentions vs. total competitor mentions in the category |
| Citation Position | Average rank in the AI’s citation list (1st vs. 5th matters) |
| Sentiment Score | Whether the AI frames the brand positively, neutrally, or negatively |
These metrics matter because the clicks that come from AI citations are worth significantly more than average. An AI-referred visitor is reportedly worth 4.4x more than a traditional organic visitor, with session durations averaging over 5 minutes compared to roughly 1 minute 24 seconds for standard search traffic. The AI is pre-qualifying users before they ever reach your site.
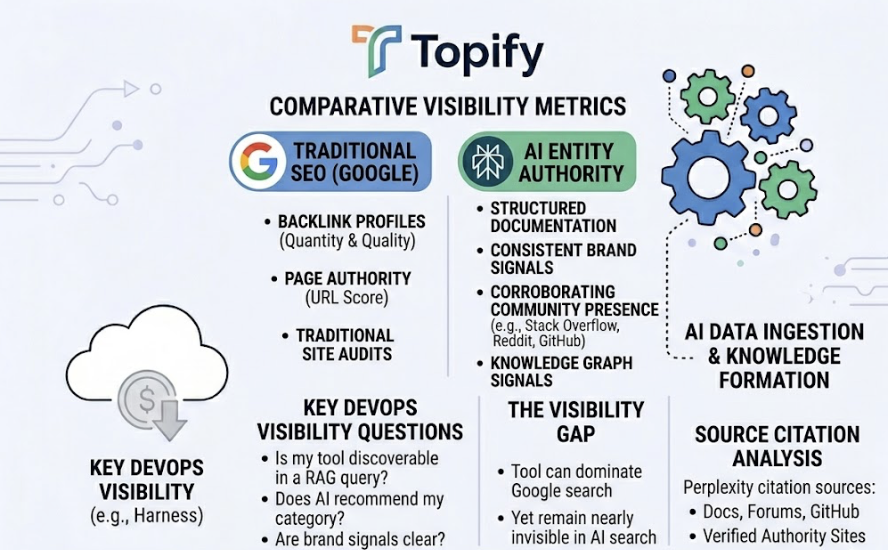
Platforms like Topify surface all of these metrics in a single dashboard, tracking brand performance across ChatGPT, Gemini, Perplexity, and other major AI engines simultaneously. The point isn’t just to know the number; it’s to have enough data granularity to know why it changed.
The Prompts That Actually Drive Decisions for Your Brand
Not every AI query is worth optimizing for. The highest-value prompts are the ones that reflect genuine purchase intent, the questions users ask when they’re already narrowing down their options.
For B2B SaaS brands, these tend to be integration-specific and use-case-specific: “Which supply chain tools support SAP integration for mid-sized manufacturers?” For consumer products, community consensus matters: “What do people on Reddit recommend for [category] under $100?” For professional services, it’s about methodology and reputation.
The challenge is that these high-value prompts aren’t always obvious from traditional keyword tools, which are built around short-form search queries, not 23-word conversational questions.
Topify’s High-Value Prompt Discovery surfaces the actual prompts driving AI-category conversations in your space, including emerging patterns that haven’t yet appeared in keyword databases. In practice, a supply chain analytics company using this feature might discover that the queries generating the most AI citations aren’t about “supply chain visibility” at all, but about tier-2 supplier risk during regional disruptions, a specific topic their content had never addressed.
The goal is to map your content to the prompts that actually exist, not the prompts you assumed people were asking.
How to Actually Get ChatGPT to Mention Your Brand
There are two tracks to improving AI brand visibility, and both need to run in parallel.
Track 1: Structural optimization (on-site)
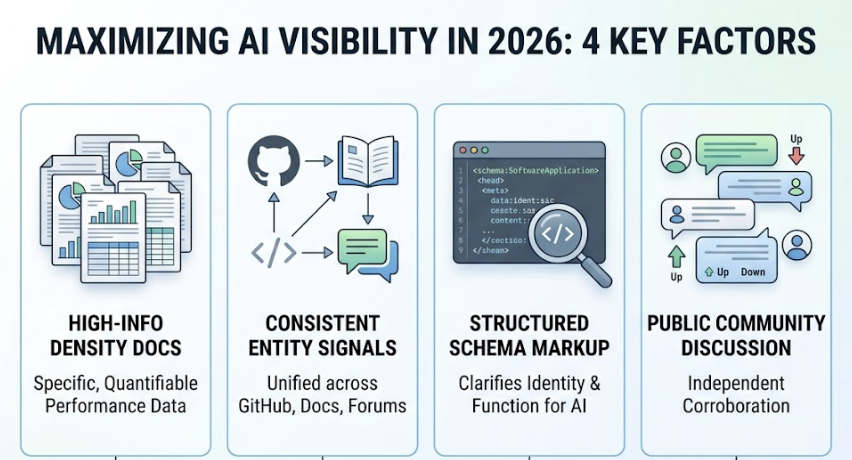
The Princeton and Georgia Tech GEO research found that targeted on-page edits can increase AI visibility by up to 40%. The changes aren’t cosmetic. They’re structural:
Place a 30-to-40-word direct answer immediately after every H2 heading. Use the “Bottom Line Up Front” principle: state the conclusion before the explanation. Add specific statistics where you have them. Research shows that incorporating concrete data points increases citation probability by 37%, and citing authoritative third-party experts increases it by 40%. LLMs are trained heavily on academic and journalistic text, so content that mirrors that density signals higher information value.
Also use tables and bulleted lists for comparative data. AI systems extract structured formats more efficiently than prose. A table comparing your product to the category standard is far more likely to be pulled into a response verbatim than a paragraph saying the same thing.
Track 2: Authority seeding (off-site)
Since AI models weight third-party sources heavily, off-site authority matters as much as on-site structure.
Prioritize editorial placements on domains with high authority ratings: Forbes, TechCrunch, industry-specific publications, and review platforms like G2 or Capterra. A single editorial placement on a domain the AI trusts outweighs hundreds of low-quality backlinks.
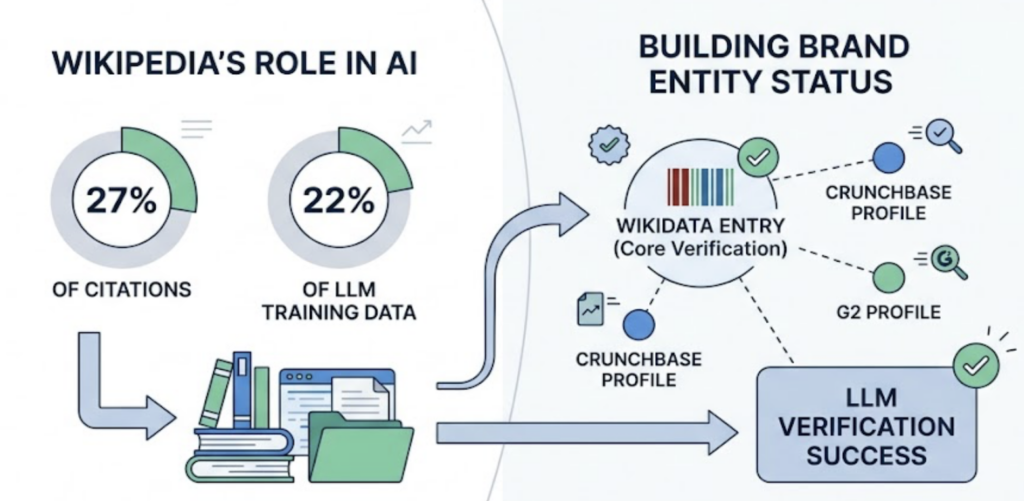
Wikipedia and Wikidata are worth separate attention. Wikipedia alone appears in roughly 27% of citations across major AI platforms and represents approximately 22% of LLM training data. Not every brand qualifies for a Wikipedia page, but maintaining accurate Wikidata entries and profiles on Crunchbase or G2 helps the model verify your brand’s entity status.
Community platforms count too. Perplexity and Google AI Overviews cite Reddit threads extensively. Authentic participation in relevant communities creates the social-proof signal that models use to nuance their recommendations.
Topify’s Source Analysis function shows exactly which domains and URLs your category’s AI responses are currently pulling from, and at what rate. One marketing team tracking visibility in the “AI rank trackers” category discovered Perplexity was citing Reddit threads 46% of the time, while ChatGPT was citing specialized industry publications. That’s not information you can reverse-engineer from a general SEO audit. Knowing the precise sources gives your team a concrete list of where to invest.
How Long Does It Take to Show Up in ChatGPT?
The timeline depends heavily on which part of ChatGPT you’re targeting.
| Platform | Pathway | Typical Timeframe |
|---|---|---|
| Perplexity AI | Real-time retrieval | 48 hours to 1 week |
| ChatGPT Search | Bing index + RAG | 2 to 4 weeks |
| Google AI Overview | Google Search index | 4 to 8 weeks |
| ChatGPT (base model) | Model retraining | 6 months to 1 year |
Perplexity responds to content changes fastest because it relies primarily on real-time retrieval. The base ChatGPT model, which forms most users’ default experience, only reflects new information when OpenAI runs a new training cycle, which is measured in months, not days.
That said, speed also varies by starting point. Brands with an established Wikipedia presence or editorial footprint on high-authority domains see measurable results 3.2x faster than newer brands building from scratch. The prior work isn’t wasted; it’s the head start.
The other lever is technical. Ensuring your site is crawlable by AI scrapers (not just Googlebot) and using IndexNow to notify Bing immediately after publishing can meaningfully compress the 2-to-4-week window for ChatGPT Search. Publishing 8 to 12 structured, data-dense pieces per month builds visibility faster than occasional long-form content.
Visibility tracking across these different platforms requires watching separate signals simultaneously. Topify’s dashboard monitors brand performance across ChatGPT, Gemini, Perplexity, and others in a single view, so a drop in one platform’s mention rate doesn’t go unnoticed for weeks. If you want to get started, the Basic plan covers ChatGPT, Perplexity, and AI Overviews tracking across 100 prompts per month.
Conclusion
The visibility gap between brands that appear in AI recommendations and those that don’t is structural, not random. It’s driven by how AI models retrieve information, which sources they trust, and whether your content is formatted for machine extraction. None of those factors change on their own.
The brands closing that gap aren’t guessing at what ChatGPT wants. They’re tracking exactly which prompts mention competitors, which sources the AI is citing in their category, and where the specific holes in their content are. That’s not a manual audit you run once. It’s a continuous monitoring loop. The brands that build that loop now are the ones competitors will be trying to catch up to next year.
FAQ
Q: Does ChatGPT show different brands to different users?
A: To a degree. The base model produces relatively consistent answers for standard prompts, but when users include persona-specific context, such as their company size, budget, or region, the AI pulls different subsets of its knowledge. ChatGPT’s “Memory” feature also allows it to personalize recommendations based on prior conversations over time, making early visibility in standard queries increasingly important.
Q: Does having a Wikipedia page help with AI brand visibility?
A: Significantly. Wikipedia appears in roughly 27% of citations across major AI platforms and represents a primary source for LLM training data. Brands that don’t meet Wikipedia’s notability standards should focus on Wikidata entries and high-authority industry publications such as G2, Crunchbase, and trade-specific review sites as the next-best alternatives.
Q: Can I pay to get mentioned in ChatGPT?
A: Not in the organic answer. OpenAI has begun testing labeled sponsored placements in ChatGPT for free-tier users, but these are distinct from the AI’s generated responses and don’t influence organic citations. On Perplexity, there are currently no ad placements at all, meaning organic visibility is the only path on that platform.
Q: What’s the difference between SEO and GEO for brand visibility?
A: Traditional SEO focuses on driving clicks from ranked URLs. GEO (Generative Engine Optimization) focuses on being part of the AI’s synthesized answer, regardless of whether the user ever clicks. The metrics are different: SEO tracks rankings and CTR, while GEO tracks mention rate, share of model, and citation position. Both matter, but they require different strategies and different types of content.