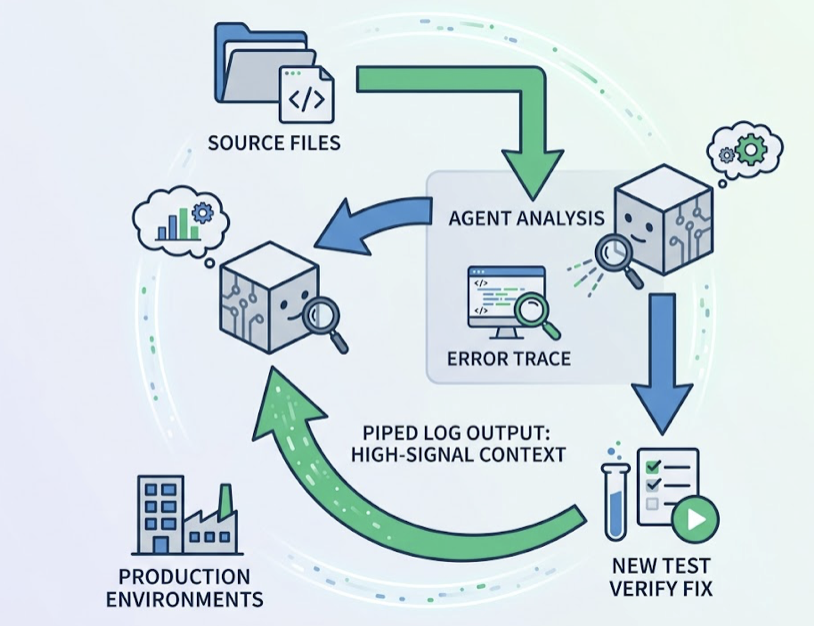
The average pull request waits more than four days before a single human looks at it. That’s not a people problem. It’s a systems problem, and it’s quietly draining millions of dollars from engineering teams that think they’re moving fast.
The good news: agentic tools like Claude Code are changing the math on review automation. Here’s exactly how to set it up.
The Real Cost of Manual Code Review
Four days of PR idle time sounds frustrating. The actual cost is worse than it sounds.
When a pull request stagnates, the author doesn’t just wait. They context-switch to other tasks to stay productive. By the time feedback arrives, re-acquiring the original mental model takes about 30 minutes of re-orientation per developer. That tax is paid twice: once to switch away, once to switch back.
Scale that across a team. For an 80-person engineering organization, a suboptimal review process costs roughly $3.6 million annually, based on a fully-loaded engineering rate of $172/hour. In teams where PRs sit idle more than half their total lifespan, wasted time averages 5.8 hours per developer per week.
The gap between elite teams and the rest is stark. Google maintains a median review turnaround under four hours. The broader industry average sits near 4.4 days. That delta represents competitive advantage, not just comfort.
| Team Tier | PR Pickup Time | PR Cycle Time |
|---|---|---|
| Elite (e.g., Google) | < 7 hours | < 26 hours |
| Mid-tier | 6–50 hours | 2–5 days |
| Lagging | 50–137+ hours | > 7 days |
| Industry Average | 4+ days | ~5 days |
Closing that gap from 48-hour pickup to 8-hour pickup saves an estimated $15,580 per developer annually. For a ten-person team, that’s over $150,000 in reclaimed productivity.
What Senior Engineers Are Actually Doing All Day
Here’s the uncomfortable data point: only 15% of code review comments address actual logic defects or architectural flaws. The remaining 85% are nitpicks about naming conventions, spacing, and stylistic preferences.
Microsoft research found that up to 75% of human review comments relate to “maintainability” rather than technical correctness. That’s three-quarters of a senior engineer’s review time spent on tasks that automation handles better, faster, and without the interpersonal friction.
The rise of AI-generated code hasn’t helped. AI-authored pull requests contain roughly 1.7x more issues than human-authored ones, with a 3x increase in readability issues and a 2.74x increase in security vulnerabilities. Without a corresponding agentic review layer, the speed gains from AI coding tools just relocate the bottleneck downstream.
What Claude Code Actually Does in a Code Review
Claude Code isn’t a linter with a chat interface. It’s a reasoning agent.
Unlike IDE autocomplete tools, Claude Code navigates entire codebases, plans multi-step tasks, and verifies results through actual terminal interaction. It follows a task loop: gather context, take action, verify outcome. The agent uses models like Claude Sonnet 4.6 with a context window ranging from 200,000 to 1,000,000 tokens, meaning it can hold your source code, test suite, and configuration files in memory at the same time.
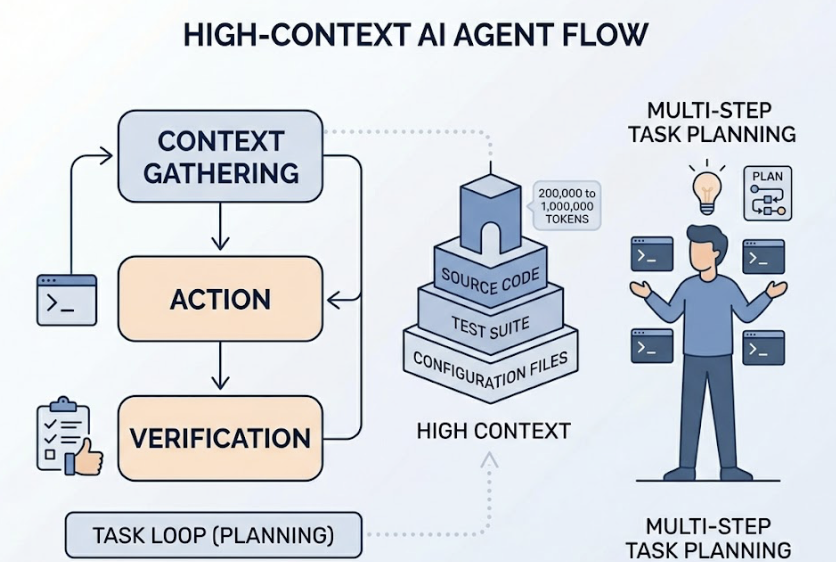
| Capability | Traditional AI Assistants | Claude Code |
|---|---|---|
| Operating Mode | User-driven | Agent-driven |
| File Scope | Single file or limited context | Repository-wide |
| Tool Integration | IDE only | Terminal, Git, MCP, CI/CD |
| Verification | Manual (developer runs tests) | Automated (AI runs and fixes tests) |
| Memory | Stateless | Cross-session via CLAUDE.md |
What It Catches That Human Reviewers Miss
Human reviewers suffer from attention thinning. Defect detection peaks at pull requests of 200 to 400 lines of code, requiring roughly 60 minutes of focused attention. Beyond 500 lines per hour, the ability to spot critical defects collapses. PRs under 100 lines enjoy an 87% defect detection rate. PRs over 1,000 lines drop to 28%.
Claude Code maintains consistent analytical depth regardless of change set size. Specifically, it reliably catches:
- Branch and multi-step logic errors in conditional routing and complex coordination flows
- Concurrency and race conditions in asynchronous code, across languages
- Cross-file dependency breaks where a utility change causes a silent failure in an unrelated service
- Security vulnerabilities from the OWASP Top 10, including SQL injection in interpolated strings and broken JWT verification
- Incomplete patches that fix a bug but leave similar vulnerabilities in adjacent code paths
That last category is where human review most commonly fails. Fixing a bug is easy. Verifying that the same bug doesn’t exist in five similar patterns elsewhere in the codebase requires the kind of whole-repo traversal that’s trivially easy for an agent and genuinely tedious for a person.
Setting Up Claude Code for Code Review
Claude Code is terminal-first. The setup is straightforward, but getting the configuration right determines whether it works like a sharp tool or an expensive toy.
Prerequisites and Installation
System requirements:
- macOS 10.15+, Ubuntu 20.04+, or Windows 10+ (via WSL 2)
- Node.js 18+ and Git 2.23+
- Minimum 4GB RAM (8GB recommended for larger repos)
| Installation Method | Command | Best For |
|---|---|---|
| Native installer | curl -fsSL https://claude.ai/install.sh | bash | macOS/Linux |
| NPM global | npm install -g @anthropic-ai/claude-code | Node-centric teams |
| Pinned version | curl... | bash -s 1.0.58 | Production consistency |
Authenticate via the Claude Console or set an ANTHROPIC_API_KEY environment variable. Enterprise teams can route through Amazon Bedrock or Google Vertex AI for data residency and zero-data retention modes.
Connecting Claude Code to Your Repo with CLAUDE.md
The single most important configuration step is the CLAUDE.md file. Place it at the project root. It’s Claude Code’s persistent memory: the document that tells the agent what your team values, what commands to run, and what patterns to avoid.
Keep it under 200 lines. The “Golden Rule” here is signal density. A bloated CLAUDE.md loses its effectiveness fast.
A well-structured CLAUDE.md follows this hierarchy:
| Section | Example Content | Why It Matters |
|---|---|---|
| Tech Stack | React, Go, Postgres | Eliminates 90% of framework errors |
| Commands | make test, pnpm build | Agent can verify its own work |
| Style Rules | “Use interfaces over types” | Improves consistency by 70% |
| Anti-Patterns | “NEVER use any“ | Hard constraints stick better than preferences |
Use the @ syntax to link to external documentation files rather than inlining everything. This keeps CLAUDE.md lean while giving the agent access to deep context on demand. For monorepos, add directory-level CLAUDE.md files in subdirectories to scope rules by module.
Run /init to let Claude Code analyze your repository automatically. It’ll detect build systems and frameworks, giving you a working baseline.
3 Claude Code Automation Patterns That Actually Work
Pattern 1: Automated PR Summaries on Every Push
Most PR descriptions are useless. “Fix bug.” “Update auth.” These tell reviewers nothing and slow down triage.
Pipe a git diff into the Claude Code CLI and get a PR summary that includes which modules are affected, what tests were run, and what edge cases the reviewer should watch. At Rakuten, this level of automation contributed to reducing average feature delivery time from 24 working days to 5 days.
You can generate these summaries pre-push as a git hook or as a CI step immediately after a PR opens. Either way, the reviewer arrives with context instead of having to build it from scratch.
Pattern 2: Style Enforcement Without the Arguments
Nitpick comments create friction, damage morale, and consume senior engineer time on tasks a machine can handle better. Claude Code addresses this through custom Skills, stored in .claude/skills/, that act as automated style guardians.
A code-review skill can enforce your TypeScript conventions before any human sees the PR: prohibiting the any type, requiring props interfaces to follow component name prefixes, enforcing arrow functions for React components. The “bikeshedding” comments get resolved silently.
In practice, this reduces a senior engineer’s initial review pass from 30–60 minutes to under 5 minutes. That’s not a small number when multiplied across 20 PRs a week.
Pattern 3: Logic and Edge Case Flagging Before Human Review
This is where Claude Code earns its keep over any linter. Its reasoning capability lets it catch runtime issues that static analysis misses entirely: division by zero in numeric flows, unhandled empty strings in form processing, field mapping errors between serializers and DTOs, race conditions in async event handlers.

The pattern is simple: Claude Code runs a logic pass before the PR enters the human review queue. By the time a senior engineer looks at the code, the question isn’t “Does this work?” It’s “Is this the right architecture for what we’re building?” That shift in question is the entire point.
Plugging Claude Code Into Your CI/CD Pipeline
The full automation payoff comes when Claude Code runs on every push without manual invocation. The primary mechanism is the Claude Code GitHub Action (anthropics/claude-code-action@v1).
GitHub Actions Integration
name: Claude AI Review
on:
pull_request:
types: [opened, synchronize]
jobs:
claude-review:
runs-on: ubuntu-latest
permissions:
contents: write
pull-requests: write
issues: read
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: "Review the git diff for this PR. Focus on logic errors and security. Use project guidelines in CLAUDE.md."
claude_args: "--model claude-sonnet-4-6 --max-turns 20"
For AWS Bedrock or Google Vertex AI deployments, use OpenID Connect (OIDC) instead of static secret keys. This lets the agent operate in regulated environments without credential exposure.
When to Trigger Automated Review vs. Human Escalation
The most effective teams use a tiered approach:
| Trigger | Who Runs | Focus |
|---|---|---|
| Every push | Claude Code | Style, logic, edge cases, security |
@claude mention | Claude Code | Feature implementation, targeted refactors |
| Post-AI-pass | Senior Engineer | Architecture, intent, product context |
Use --max-turns to cap token consumption and prevent runaway jobs. Trigger the full review only on opened and synchronizeevents, not on label changes or comment edits. For cost optimization, lightweight models like Haiku handle extraction and summarization while Sonnet or Opus handles final architectural critique.
What You Still Need a Human For
Claude Code is not a replacement for engineering judgment.
The agent executes within constraints humans define. Someone has to write the CLAUDE.md. Someone has to design the Skills. Someone has to decide what “good architecture” means for this product in this market at this stage.
Humans remain responsible for:
- Defining the constitution: CLAUDE.md and Skills encode team culture and risk tolerance. That’s not something an agent can invent on its own.
- High-level planning: Claude can execute multi-file refactors, but the architectural vision behind them requires human reasoning about product direction.
- Final merge approval: Every automated change should flow through a PR where a human provides the final merge. The agent is a verifier, not a decision-maker.
- Handling ambiguity: When requirements are unclear, a human must define success before the agentic loop begins.
Stripe deployed Claude Code to 1,370 engineers, freeing them from manual 10,000-line migrations. The engineers didn’t disappear. They moved upstream.
That’s the actual value proposition: shifting senior engineering time from “human linter” to “human architect.”
Conclusion
Manual code review isn’t slow because engineers are slow. It’s slow because the process isn’t designed for the volume of code modern teams ship. PR queues, context loss, nitpick cycles, and rubber-stamping large changes are structural problems that structural tools can fix.
Claude Code handles the mechanical 85% of review work: style, logic, edge cases, security, dependency tracing. What’s left for humans is the 15% that actually requires judgment. That’s a better use of everyone’s time, and the numbers, $150K+ in reclaimed productivity per 10-person team, make the ROI clear.
Start with a CLAUDE.md, one automation pattern, and a GitHub Action. You’ll see the return before the end of the sprint.
FAQ
Q: How does Claude Code affect CI/CD costs?
A: Claude Code runs on GitHub-hosted runners using standard Actions minutes. AI costs are token-based. Use --max-turnsto prevent runaway jobs, and trigger reviews only on opened and synchronize events. For larger teams, hybrid model strategies (Haiku for extraction, Sonnet for orchestration) keep costs manageable.
Q: Can Claude Code access sensitive internal libraries?
A: Yes. Through the Model Context Protocol (MCP), Claude Code connects to internal documentation and proprietary libraries while keeping execution local. For environments with strict data residency requirements, AWS Bedrock and Google Vertex AI integrations support zero-data retention mode.
Q: How do we prevent Claude from making too many autonomous changes?
A: Claude Code uses a permission-based architecture. By default, it’s read-only and requires explicit approval for every write or bash command. In CI/CD, all changes flow through pull requests requiring human merge approval. The agent is structurally prevented from merging its own changes.
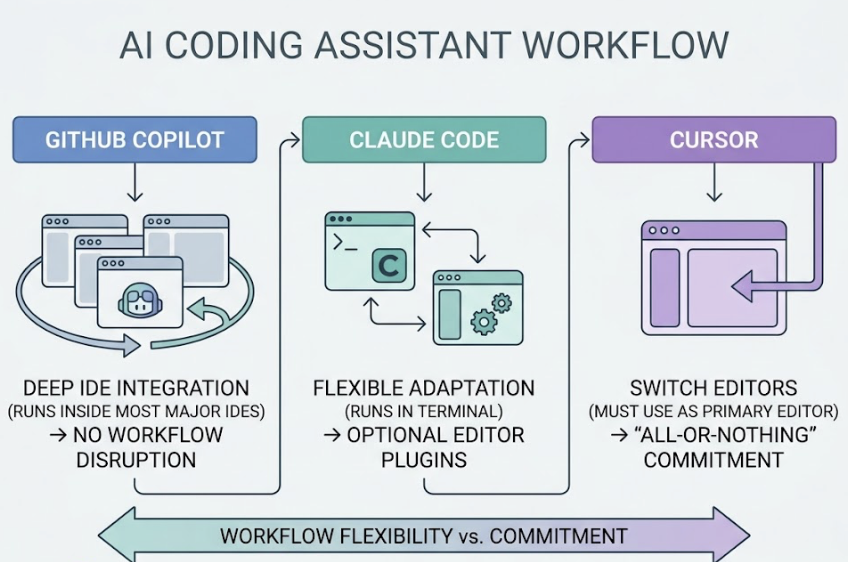
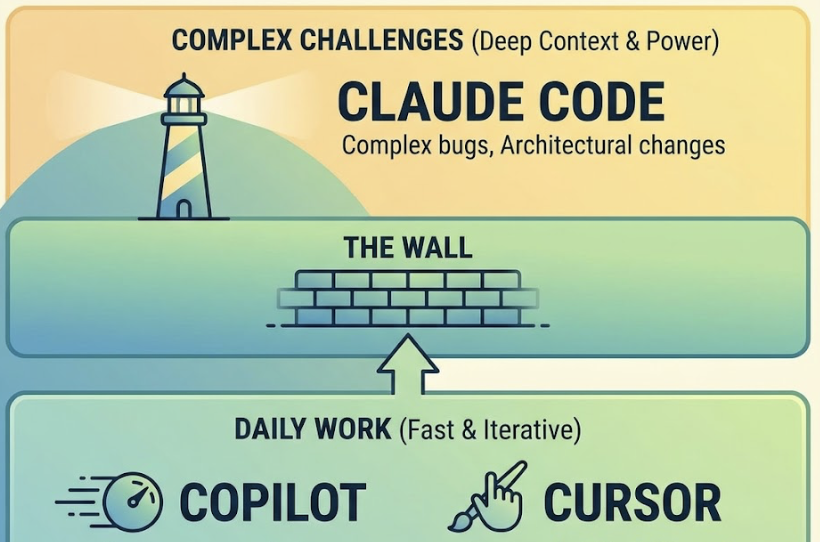
Q: What’s the difference between Claude Code and Cursor?
A: Cursor is an AI-enhanced IDE built for interactive coding: you drive, the AI assists. Claude Code is a terminal-first agent built for autonomous multi-file orchestration: the AI drives, you supervise. They’re not direct competitors. Many teams use both, Cursor for active development, Claude Code for verification and CI automation.