Your domain authority is 75. You’re ranking on page one for your top 20 keywords. Your content calendar is humming along. Then someone asks ChatGPT, “What’s the best tool for [your category]?” and your brand doesn’t make the list. Five competitors do. Your SEO dashboard has no metric that explains why.
That’s the gap. Traditional search metrics measure discovery through blue links. AI search engines don’t work that way. They synthesize answers, cite sources, and recommend brands, often without sending a single click to your site. And if you’re not tracking what AI is saying about you, you’re optimizing for a search experience that’s already being replaced.
Your Google Rankings Don’t Tell You What AI Is Saying About Your Brand
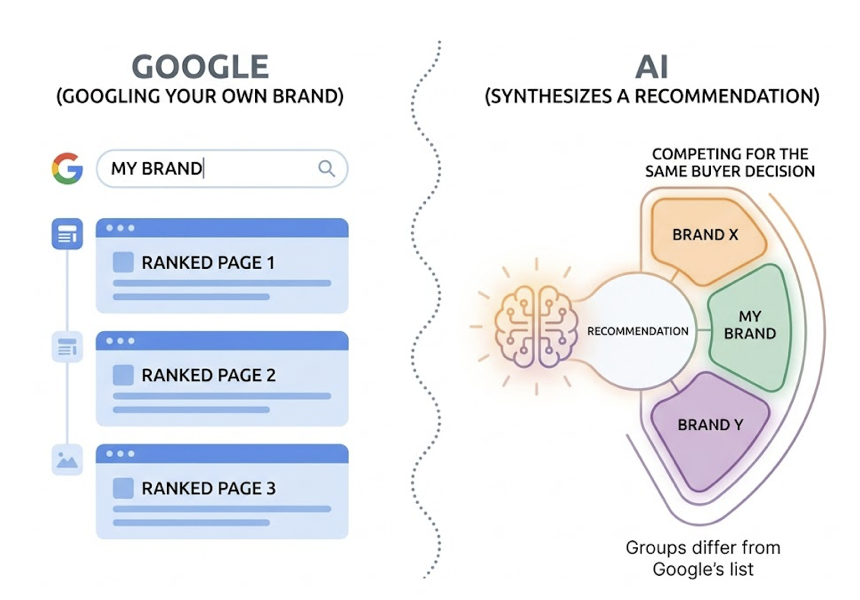
AI search visibility is the frequency, quality, and accuracy with which a brand gets mentioned, recommended, or cited in AI-generated responses. It’s a fundamentally different signal from ranking position or organic traffic.
Here’s the conflict: a brand can have top-tier Google rankings and a high domain authority score, yet remain completely invisible in an AI answer. The model may not consider that site a trusted source. Or the content may fail to meet the structured requirements that RAG architectures depend on to pull and synthesize information.
The distinction matters because the two systems optimize for different outcomes. Traditional SEO is optimized for discovery: ranking for keywords to earn a click. AI SEO, sometimes called AI search optimization, is optimized for influence: becoming the trusted data source the AI uses to build its answer. A brand that’s great at the first and ignoring the second is leaving an entire channel unmeasured.
The Metrics That Define AI Search Visibility
Because users increasingly get answers without clicking, traditional traffic metrics only capture a fraction of what’s happening. Measuring AI search visibility requires a different set of KPIs.
Brand Presence tracks the percentage of relevant prompts where your brand is mentioned. Think of it as market share for the AI era. If there are 50 prompts that matter to your category and you show up in 12 of them, that’s your baseline.
Citation Share measures how often your URLs are cited compared to competitors. This is the clearest indicator of source authority in the eyes of the LLM. If a competitor’s blog post is being cited 3x more than yours for the same topic, that’s a content gap you can act on.
Sentiment Score tracks whether AI describes your brand positively, neutrally, or negatively. This is where hallucination risk lives. An AI engine might describe your enterprise product as “budget-friendly” or your premium service as “basic.” Without tracking sentiment, you won’t catch the mismatch.
AI Volume measures how frequently a topic gets queried through AI-integrated tools. Not every keyword matters equally in AI search. Some prompts get asked thousands of times a month across ChatGPT and Perplexity. Others barely register. AI volume data helps you prioritize which content topics need AI search optimization focus.
Why AI Search Optimization Needs Its Own Playbook
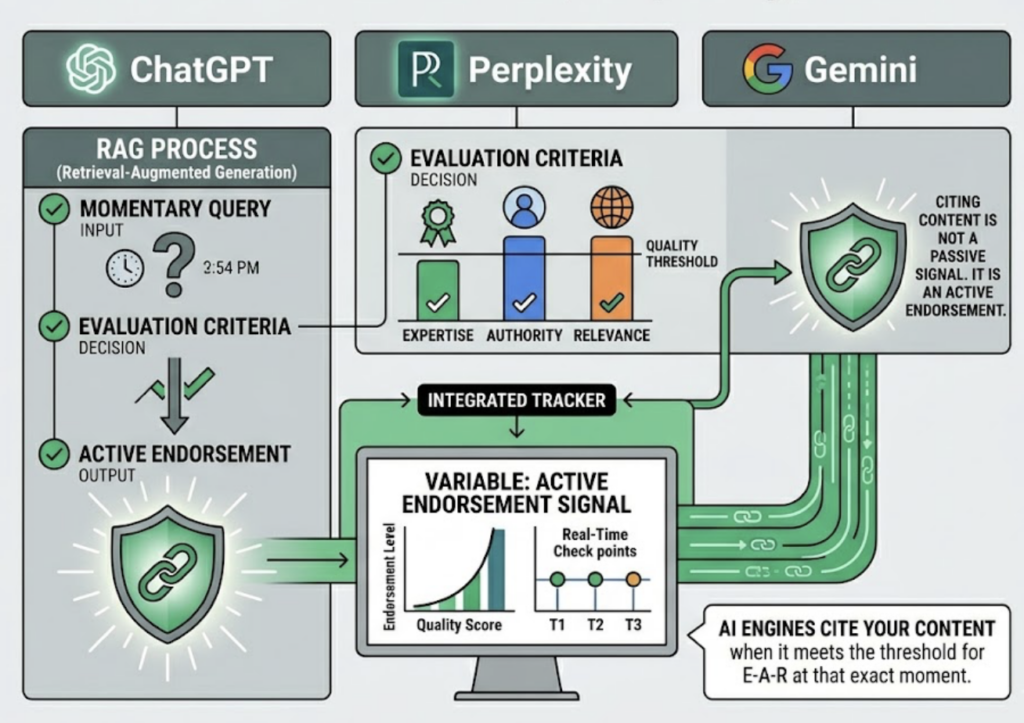
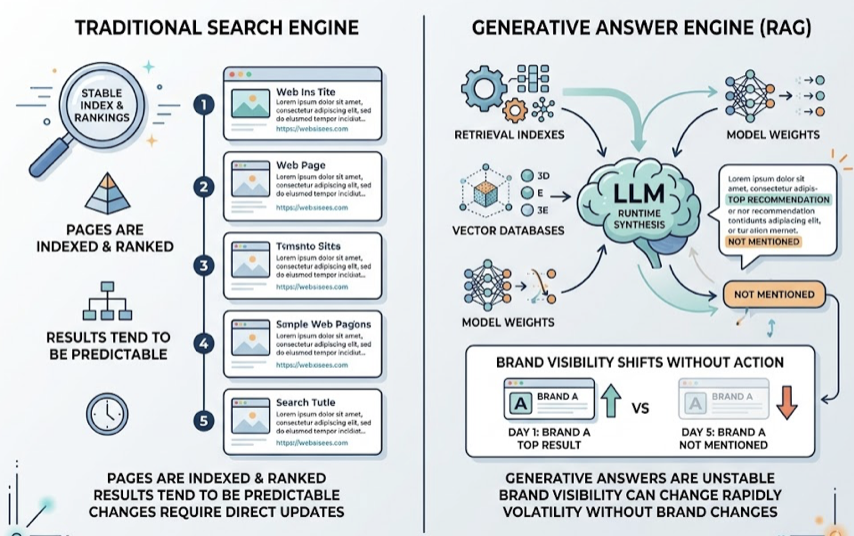
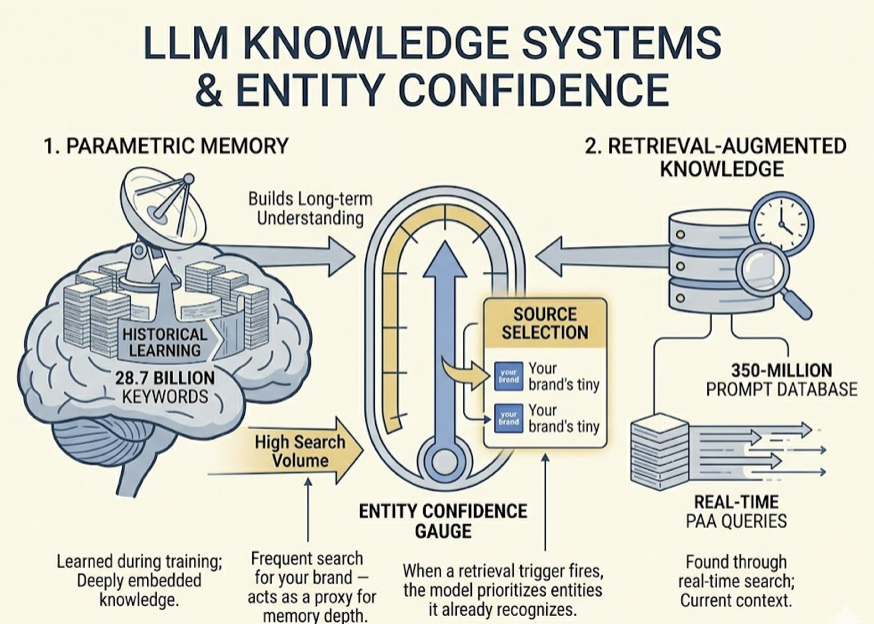
Modern AI search engines run on a Retrieval-Augmented Generation (RAG) pipeline, and the logic is fundamentally different from traditional keyword indexing.
The pipeline works in four stages: query intent parsing (turning user input into a vector representation), hybrid retrieval (combining semantic search with lexical matching), L3 re-ranking (where content quality is assessed), and LLM synthesis (where the model generates an answer with citations). Most content gets filtered out at the re-ranking stage due to poor structure or shallow topical depth.
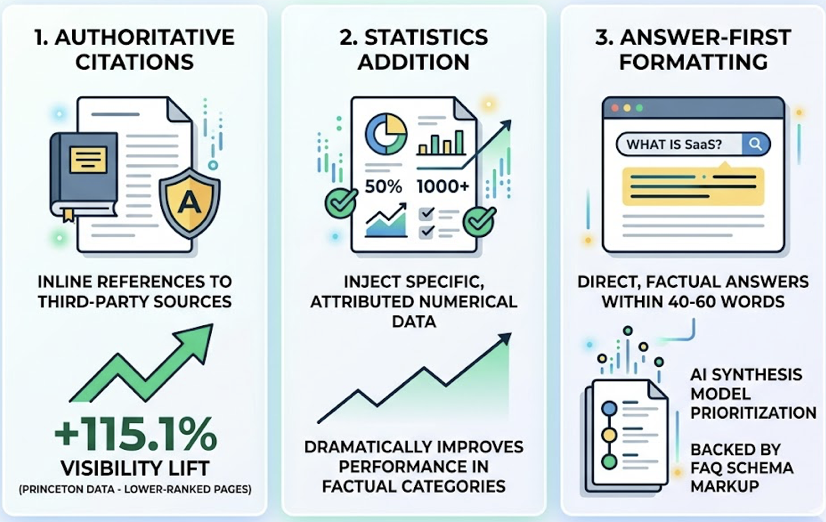
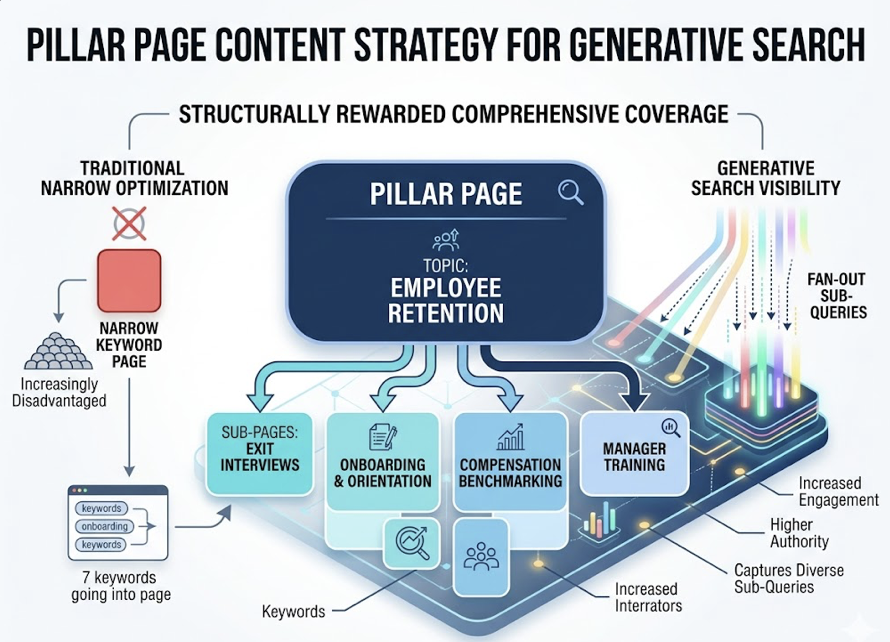
That re-ranking stage is where traditional SEO assumptions break down. RAG re-rankers tend to penalize heavy keyword density. They favor concise, answer-focused content chunks over long narrative introductions. Content with schema markup and clear FAQ-style formatting is roughly 2.3x more likely to be cited than unstructured content. AI models also prefer content that leads with a direct, definitive answer within the first 80 tokens rather than building up to it.
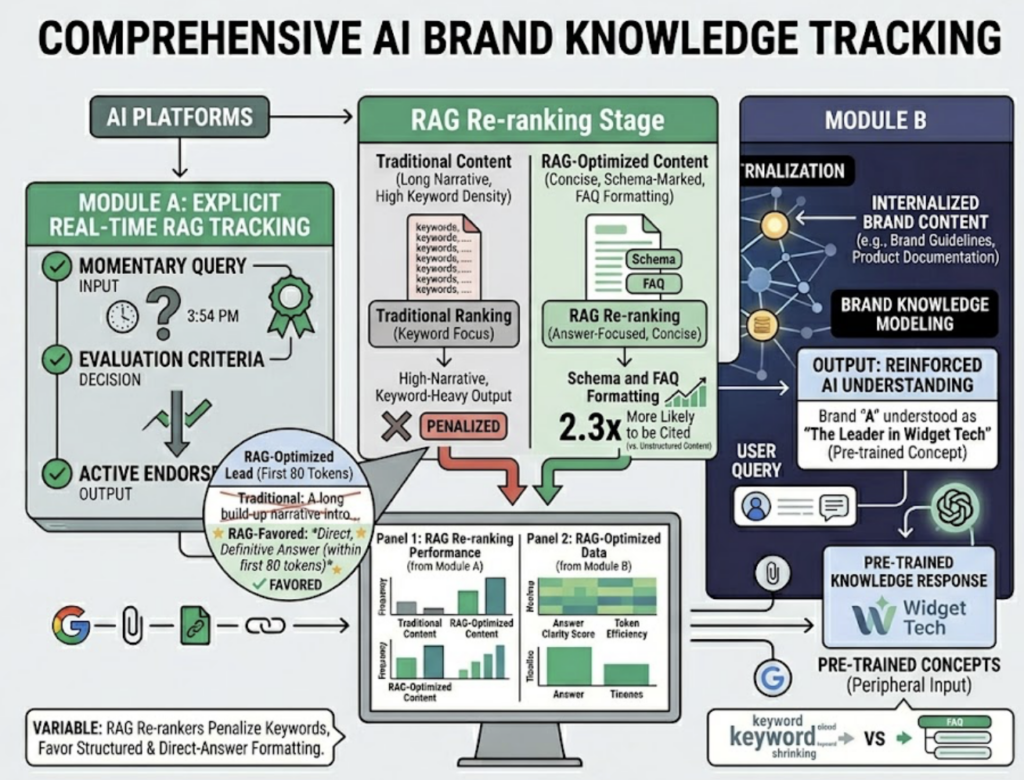
The playbook for AI search intelligence is different: structure your content for parsing, not just reading. Lead with answers. Build entity authority through proprietary data and unique frameworks. And track which sources AI is actually citing, because that’s where your content strategy should aim.
How to Track AI Brand Visibility Across ChatGPT, Perplexity, and Gemini
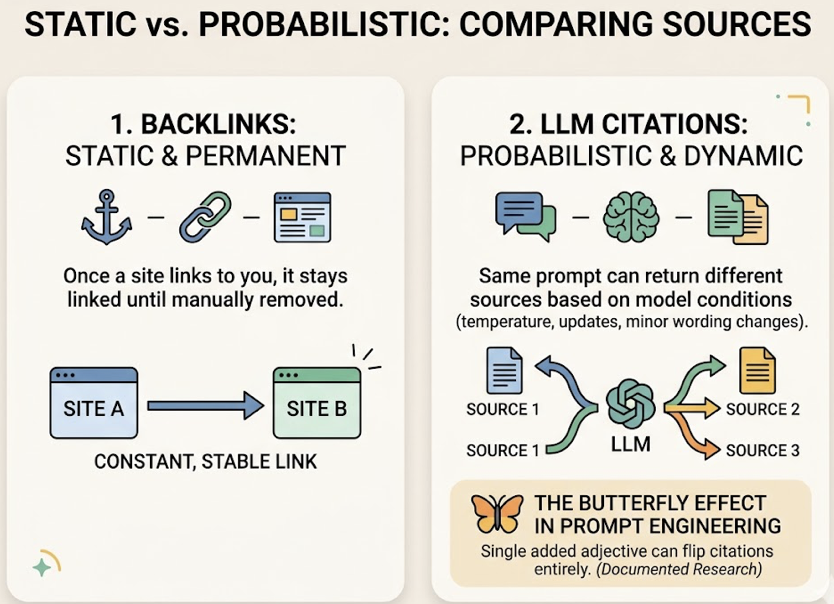
Manual spot-checking doesn’t scale. LLMs are probabilistic: fewer than 1 in 1,000 queries produce identical results. Asking ChatGPT about your brand once and treating that as data is like checking your stock price once a year and calling it a trend.
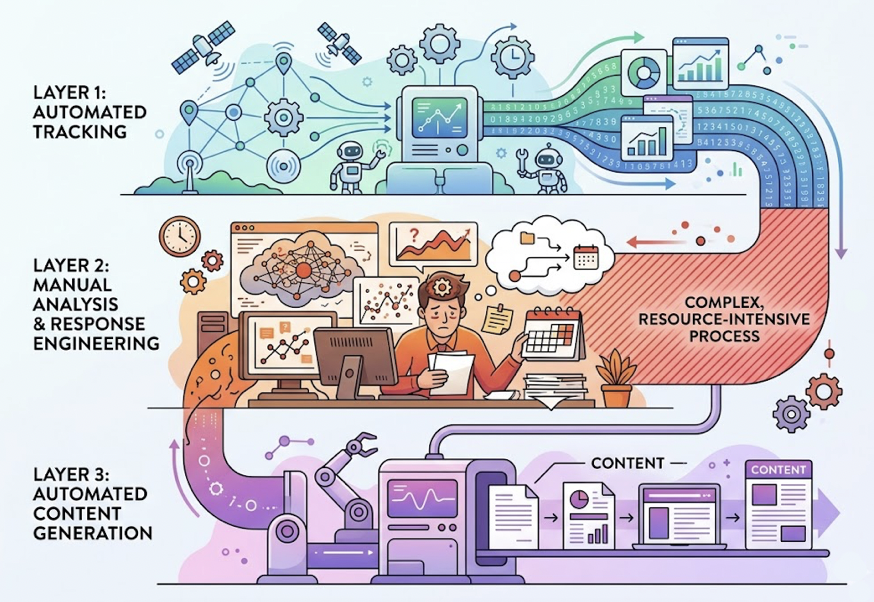
A professional AI search analytics framework has three layers.
Layer 1: Prompt-Level Mapping. Define a “golden set” of prompts based on customer pain points, sales conversations, and support tickets, not just keywords. These are the questions your buyers are actually asking AI. “What’s the best CRM for mid-market SaaS?” matters more than ranking for “CRM software.”
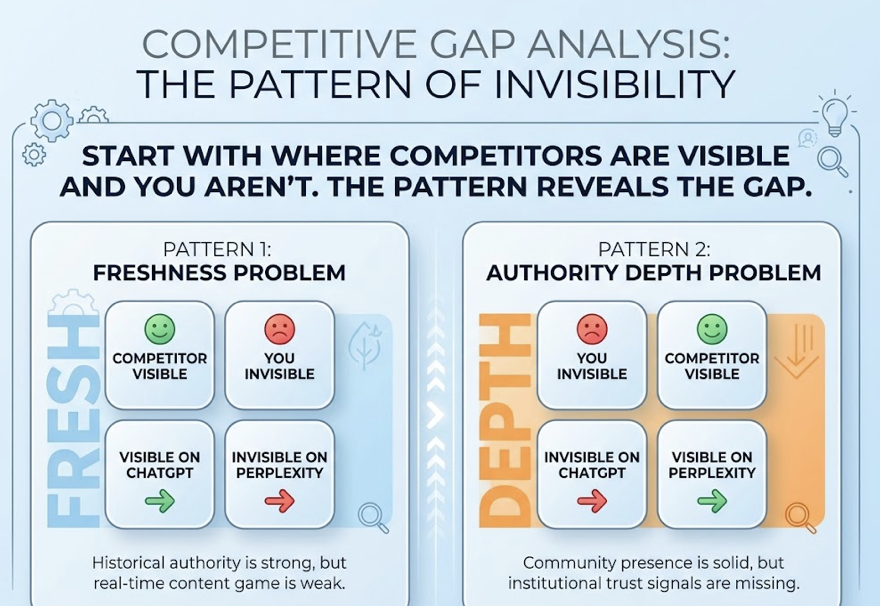
Layer 2: Cross-Platform Benchmarking. Run the same prompts across ChatGPT, Perplexity, and Google AI Overviews systematically. Different models perceive brands differently. ChatGPT tends to be more conservative, prioritizing established authority and fewer high-confidence sources. Perplexity favors real-time freshness, often surfacing content published within the last 30 days for trending topics. If your brand shows up on one platform but not another, the fix is platform-specific.
Layer 3: Source Gap Analysis. Identify which third-party domains the AI consistently cites for your category. If a competitor is being referenced through a specific industry publication, the strategy isn’t more blog posts. It’s targeted PR coverage in that publication.
For teams tracking AI brand visibility across multiple platforms, Topify combines all three layers into a single workflow. Its High-Value Prompt Discovery tool surfaces the prompts that matter most for your category. The cross-platform tracking covers ChatGPT, Perplexity, Gemini, DeepSeek, and others. And its Source Analysis feature shows exactly which domains AI is citing, so you can see whether your content or a competitor’s is getting the reference.
What an AI Visibility Platform Actually Shows You
The difference between manually querying ChatGPT and using an AI visibility platform is the difference between checking your email once a week and having a real-time inbox.
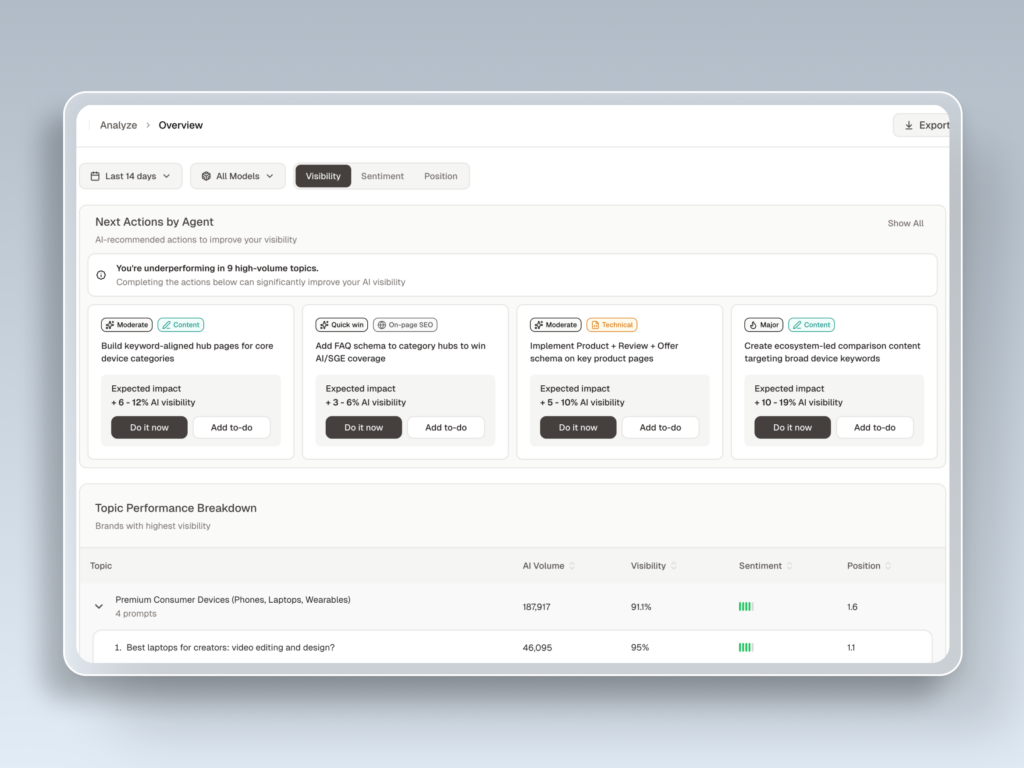
A dedicated AI search analytics dashboard answers questions that manual checks can’t: Which competitors are being recommended more than you this month? Which of your pages are being cited, and which are being ignored? Has the AI’s description of your product changed since your last content update? Are there new prompts in your category that you’re not tracking yet?
There’s also a downstream effect worth noting. Data suggests that traffic coming from AI brand mentions tends to show higher engagement and faster conversion rates. The user has already received a summarized value proposition before they arrive on your site. They’re not browsing. They’re validating a decision.
In practice, this means your AI search visibility data isn’t just a brand metric. It feeds directly into content strategy, PR planning, and competitive positioning. Topify’s dashboard, for example, lets you spot a drop in ChatGPT mentions and trace it back to a specific source that stopped citing your brand, all within the same view. Its Sentiment Analysis tracks whether AI descriptions match your brand positioning, and Position Tracking monitors where you rank relative to competitors in AI-generated recommendation lists.
That’s the shift from guessing to measuring.
Tools for Analyzing Website AI Search Visibility
When evaluating tools for analyzing website AI search visibility, four dimensions matter most: platform coverage (how many AI engines does it track?), metric depth (does it go beyond simple mention counts?), update frequency (daily? weekly?), and actionability (can you act on the data, or just look at it?).
Most approaches fall into three categories. Manual querying gives you a snapshot but no trend data and no scale. API-based scraping tools can collect data but typically require engineering resources to build dashboards around. And dedicated AI visibility platforms like Topify offer end-to-end workflows: from prompt discovery to tracking to competitive benchmarking to execution.
Topify stands out for teams that need breadth and depth. It tracks visibility across ChatGPT, Gemini, Perplexity, DeepSeek, Doubao, Qwen, and others. Its seven core metrics (visibility, sentiment, position, volume, mentions, intent, and CVR) go well beyond simple “are we mentioned?” tracking. The one-click execution feature lets you state optimization goals in plain English and deploy a strategy without manual workflows. Pricing starts at $99/month for the Basic plan, which includes 100 prompts and 9,000 AI answer analyses, enough for most teams to get a clear baseline.
For teams exploring AI search visibility for the first time, Topify also maintains a free tools reference to help you get started before committing to a platform.
Ready to see where your brand stands in AI search? Get started with Topify and run your first visibility audit.
Conclusion
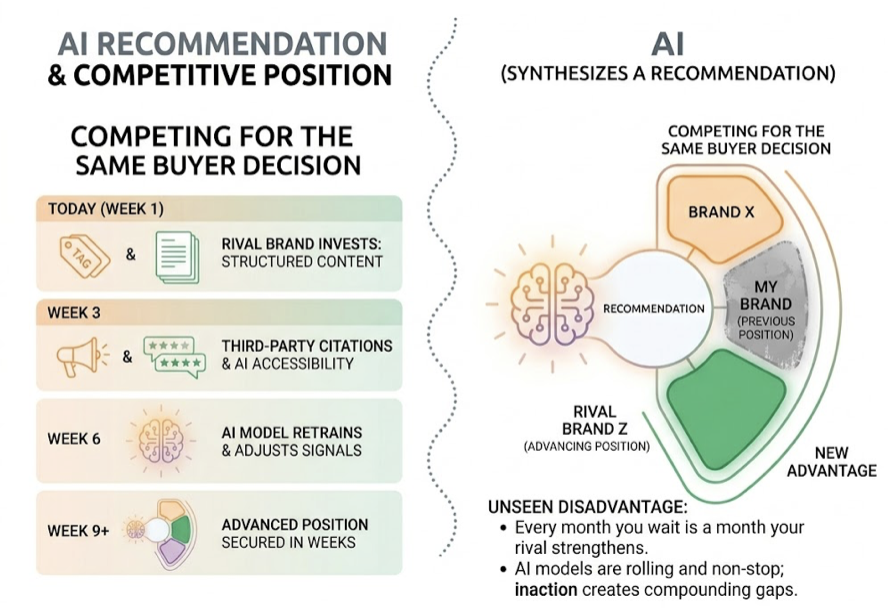
The gap between traditional search performance and AI search visibility isn’t going to close on its own. Every month that passes without tracking what AI is saying about your brand is a month your competitors may be building citation authority you can’t see in your SEO dashboard.
The fix isn’t complicated, but it does require a new lens. Start by identifying the prompts your buyers are actually asking. Track your brand’s presence, citations, sentiment, and position across the AI platforms that matter. And use the data to make content and PR decisions that are grounded in what AI engines are actually doing, not what you assume they’re doing.
FAQ
Q: What is AI search visibility?
A: AI search visibility refers to how often, how accurately, and how favorably your brand appears in AI-generated search responses across platforms like ChatGPT, Perplexity, and Google AI Overviews. It’s measured through metrics like brand presence, citation share, sentiment score, and AI query volume.
Q: How is AI search visibility different from traditional SEO rankings?
A: Traditional SEO measures your position in a list of blue links, optimized for clicks. AI search visibility measures whether your brand is mentioned, cited, or recommended inside a synthesized AI answer. A site can rank #1 on Google and still be absent from ChatGPT’s recommendations because the two systems evaluate content authority differently.
Q: What tools can I use to track my brand’s AI search visibility?
A: Dedicated AI visibility platforms like Topify offer cross-platform tracking, sentiment analysis, citation monitoring, and competitive benchmarking. For teams just starting out, manual prompt-based audits and free tools can provide an initial baseline, though they lack the scale and trend data of a purpose-built platform.
Q: How often should I monitor AI search visibility metrics?
A: Weekly at minimum for active campaigns, monthly for baseline monitoring. AI search results change frequently due to the probabilistic nature of LLMs and regular model updates. Brands in competitive categories often track daily to catch shifts in competitor positioning or citation patterns early.