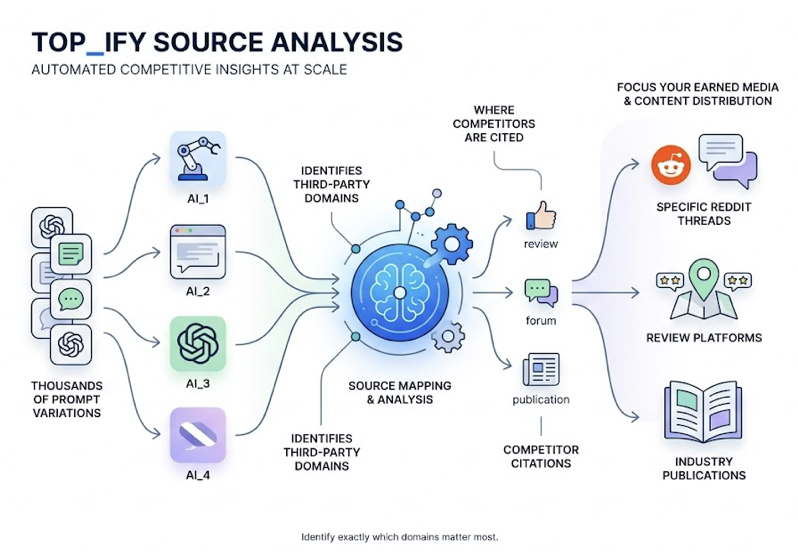
Your SEO dashboard says keyword rankings are at an all-time high. But the sales pipeline tells a different story: qualified leads are decelerating, and a growing chunk of direct traffic can’t be traced back to any campaign. The disconnect isn’t a reporting bug. It’s a measurement gap.
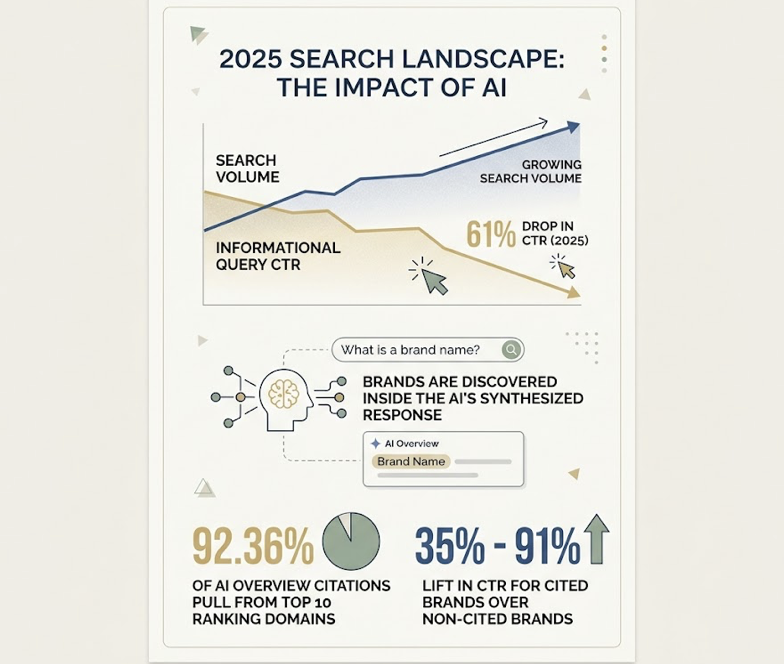
In early 2026, 73% of B2B buyers use conversational AI assistants during vendor research and shortlisting. Meanwhile, zero-click searches have climbed past 65% overall, with informational queries hitting a 74% zero-click threshold. The buyers are still searching. They’re just getting their answers, comparisons, and recommendations inside ChatGPT, Perplexity, and Gemini before they ever reach your site.
Traditional Share of Voice metrics, built on ad impression shares, organic rankings, and media mentions, can’t see any of this. What follows is a framework for measuring the metric that can.
Why Traditional Share of Voice Fails in AI Search
Traditional SOV models assume a multi-link environment. Ten or more organic results compete for clicks on a standard search page, and a brand ranking fifth still captures a predictable share of attention. Generative search collapses that model into a single, synthesized narrative. The AI typically mentions three to five brands, and frequently delivers just one primary recommendation.
That makes AI search visibility binary. You’re either woven into the response, or you’re absent.
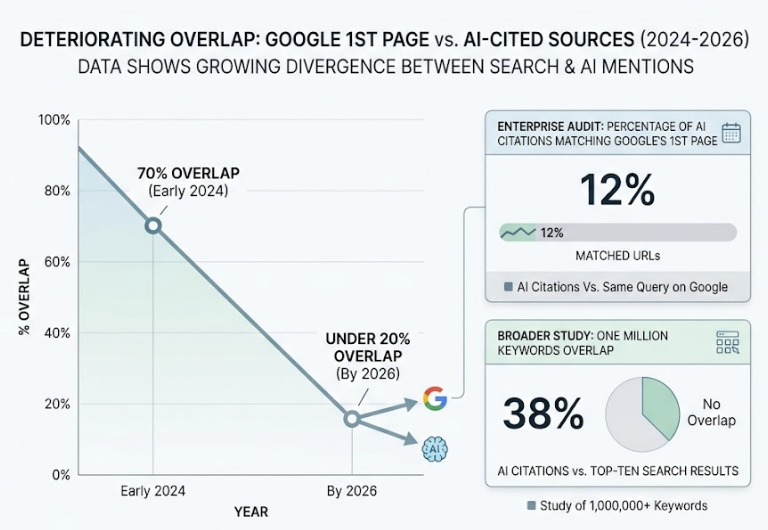
The overlap between Google’s first page and AI-cited sources has deteriorated fast. By 2026, that correlation has dropped from roughly 70% in early 2024 to under 20%. A separate enterprise audit found that only 12% of AI citations matched URLs ranking on Google’s first page for the same query. A broader study of one million keywords showed just 38% overlap between AI citations and top-ten search results.
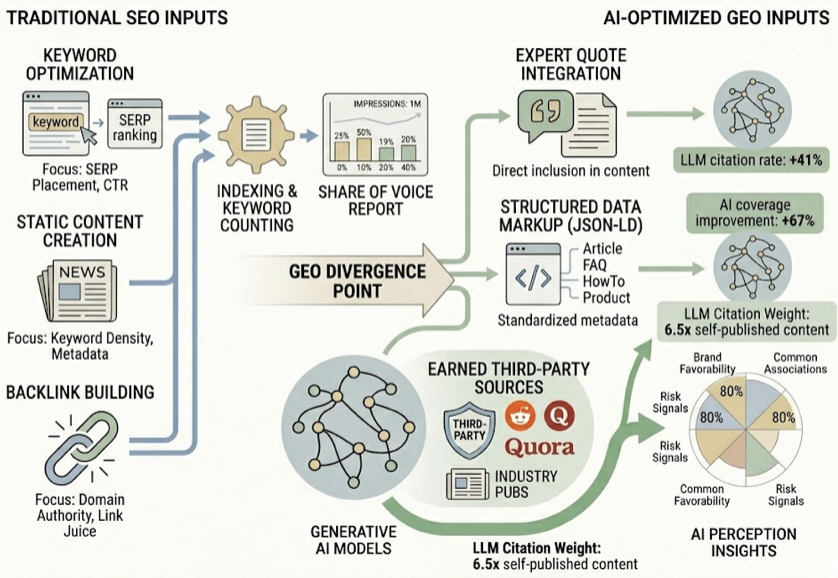
The reason is architectural. Google ranks pages using domain authority and backlink velocity. Generative engines run Retrieval-Augmented Generation (RAG), decomposing queries into semantic vectors and extracting self-contained, high-density factual passages. The content that earns a top Google ranking and the content that earns an AI citation are selected by fundamentally different systems.
Here’s the thing: because an AI response doesn’t expand to accommodate lower-tier results, every gain in a competitor’s visibility is a direct, zero-sum loss for everyone else. And with a projected 25% drop in traditional search volume by late 2026, the stakes are accelerating.
What AI Search Visibility Actually Measures
AI search visibility quantifies how frequently, accurately, and favorably large language models cite, mention, or recommend a brand when synthesizing answers to natural language prompts. It’s not a replacement for traditional search metrics. It’s a distinct, downstream layer.
Legacy SEO acts as the initial filter, placing content within the indexable web pool. Generative engine optimization (GEO) then determines whether the model selects, extracts, and trusts that content during real-time synthesis. The two work in sequence, not in competition.
The mechanism driving this selection is entity grounding. Generative engines don’t evaluate websites as isolated URL collections. They interpret the digital ecosystem as a web of interconnected entities: brands, products, individuals, and concepts. The model evaluates its “Entity Confidence,” the statistical certainty that a specific brand is the correct solution to recommend, by analyzing how consistently that brand is represented across independent surfaces. If your positioning is identical on your corporate blog, LinkedIn, third-party review directories, and industry forums, the model’s confidence increases.
If it detects structural inconsistencies, your brand gets bypassed in favor of competitors with more corroborated footprints.
This shift from link-based authority to entity-based consensus explains what analysts call the “Page 2 Anomaly.” In approximately 40% of analyzed conversational answers, platforms like ChatGPT bypass top-ten Google results to cite sources from pages two or three. The model prioritizes “information gain,” original research, proprietary statistics, or tightly structured comparison data, over raw backlink authority.
The Five Metrics That Define AI Share of Voice
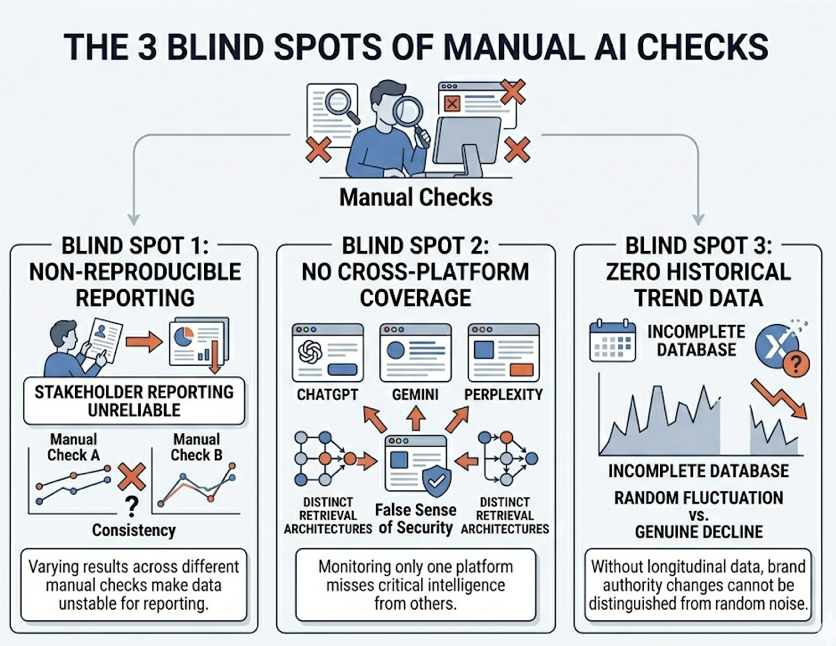
Measuring brand representation inside probabilistic models requires a framework that distinguishes between simple presence and competitive ownership. Many legacy tools conflate presence rate (how often your brand appears) with actual Share of Voice. A presence rate ignores the other brands in those same responses.
Open-Denominator vs. Closed-Denominator SOV
A closed-denominator metric restricts the competitive pool to a preselected list of rivals. The problem: it’s gameable. Remove a dominant competitor from your tracking list and your reported SOV inflates instantly, even if the model’s real-world recommendations haven’t changed.
The industry standard relies on an open-denominator framework. Here, the competitive pool is defined entirely by the model’s actual outputs. Every brand the AI names across all responses goes into the denominator. The formula:
Open AI SOV = (Target Brand Mentions / Total Brand Mentions Across All Responses) x 100
This must be calculated across multiple runs of a standardized prompt set. Single-prompt evaluations are too volatile to be useful.
The Five Core Metrics
The open-denominator SOV is evaluated alongside four secondary dimensions:
Mention Rate. The percentage of priority prompts where your brand appears. If you’re named in 400 out of 1,000 tracked category prompts, your baseline mention rate is 40%. This is the initial gauge of whether the AI associates your brand with the category at all.
Response Position Index. Conversational systems display a pronounced bias toward the first-named entity. Being placed as the primary recommendation is structurally distinct from an “also consider” mention at the end. The Position Index weighs mentions by placement order, assigning higher value to leading recommendations.
Sentiment Score. A mention isn’t inherently valuable if it’s qualified negatively. If a model notes that your software is popular but “legacy, expensive, and difficult to integrate,” you’ve achieved high visibility with toxic sentiment. Advanced measurement uses NLP to score mentions on a polarity scale, turning sentiment into a multiplier that adjusts your absolute SOV score.
Source Citation Coverage. This tracks the diversity of external domains the AI cites to validate its mention of your brand. If the model only cites your own website, that authority is shallow and prone to disruption. High-performing brands maintain citation coverage across industry publications, user forums like Reddit, and review directories like G2 and Capterra.
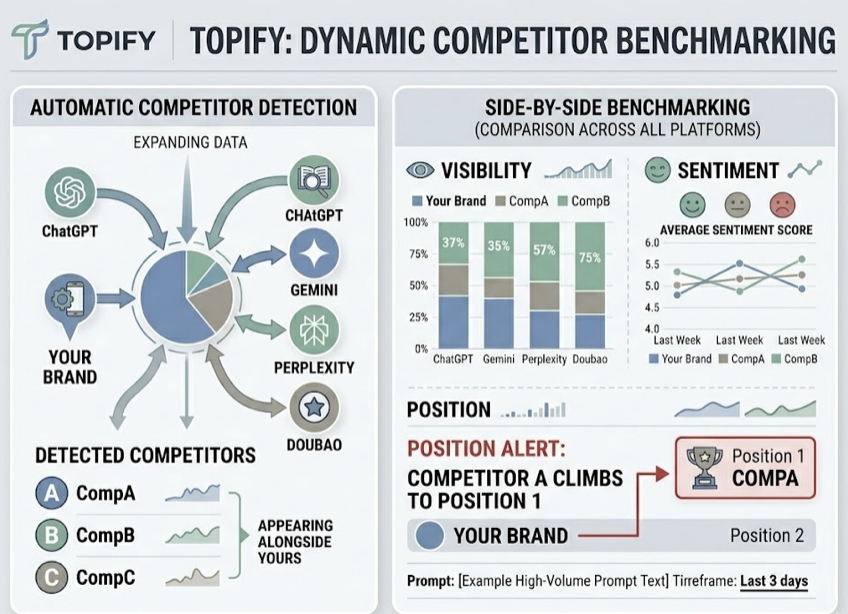
Competitor Gap Analysis. This compares your performance across the previous four dimensions directly against your closest rivals. It reveals the “white space” in the AI’s consideration set: specific prompts where competitors are absent, giving you an opening to capture category real estate.
How to Map These Metrics to a Tracking Dashboard
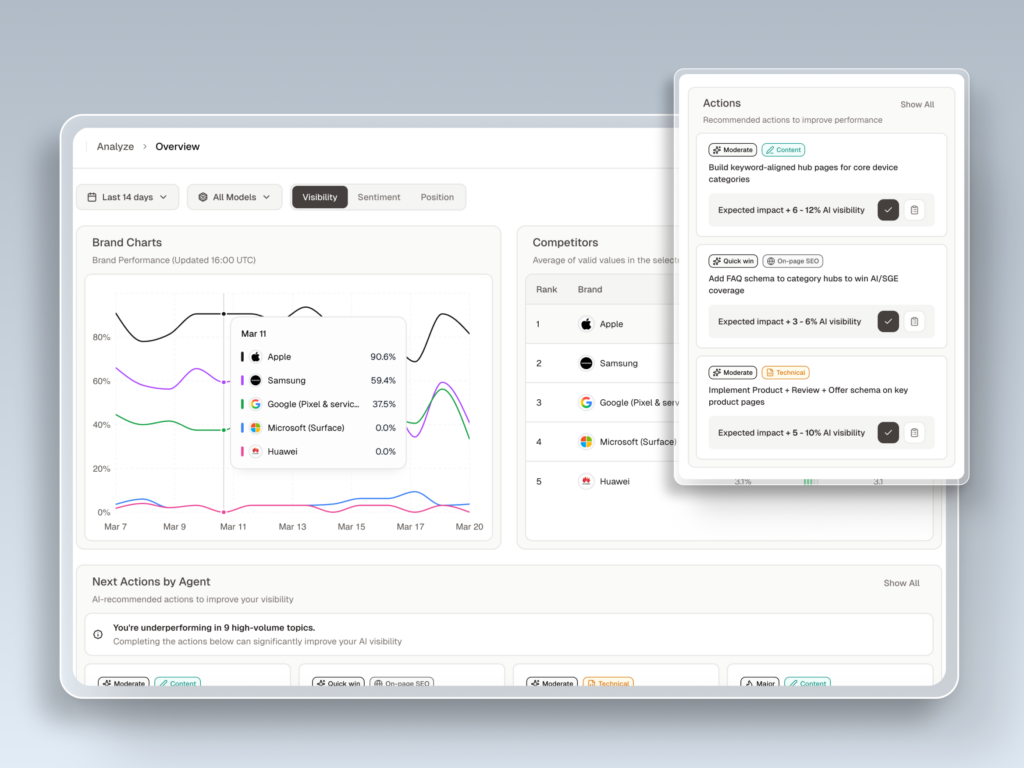
Specialized platforms consolidate these five dimensions into unified diagnostic matrices. Topify, for example, maps them across a seven-metric system that adds two layers most frameworks miss.
| Abstract SOV Metric | Topify Indicator | What It Measures |
|---|---|---|
| Mention Rate | Visibility Score | Percentage of unbranded queries where the brand is named |
| Response Position | Position Tracking | First-tier vs. trailing mention placement |
| Sentiment Score | Sentiment (RankScale) | NLP-driven rating from -100 to +100 |
| Source Coverage | Source Analysis | Diversity of external domains cited to validate the brand |
| Competitor Gap | Share of Model | Citation density compared against competitors on identical prompts |
| Search Demand | AI Volume Analytics | Estimated search demand inside generative engines specifically |
| Bottom-Line Impact | CVR (Conversion Visibility Rate) | Revenue attribution from AI citations via GA4/Shopify integration |
The last two rows matter more than most teams realize. AI Volume Analytics reveals high-intent queries that traditional SEO tools miss entirely, because the queries are phrased as natural language sentences averaging 23 words in length and containing constraints around budget, company size, and integration requirements. CVR closes the attribution loop: it connects the upstream AI mention to a downstream conversion event.
How to Track AI Share of Voice Across Platforms
A major challenge is platform fragmentation. Brand representation varies dramatically across engines due to unique training datasets, indexing speeds, and citation architectures.
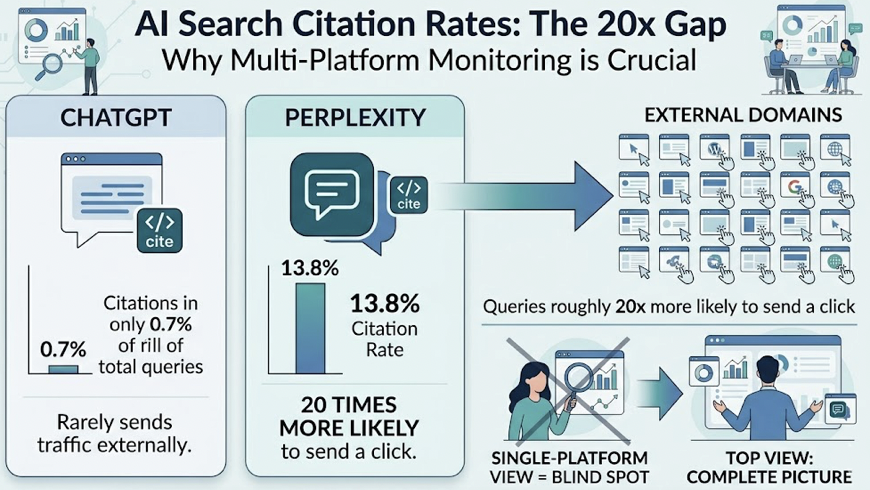
ChatGPT dominates general discovery, processing over 2 billion queries daily across 800 million weekly active users. It embeds external links in roughly 31% of its responses, making citation tracking essential but incomplete.
Perplexity serves research-intensive audiences with over 45 million monthly active users. It cites external sources in more than 77% of outputs, making it the primary driver of immediate referral traffic.
Google Gemini and AI Overviews appear in approximately 18% of US desktop searches, with Gemini surpassing 750 million monthly active users and AI Overviews reaching over 2 billion users globally.
Claude holds the highest average session value of $4.56 among conversational assistants, indicating a highly qualified audience of senior decision-makers.
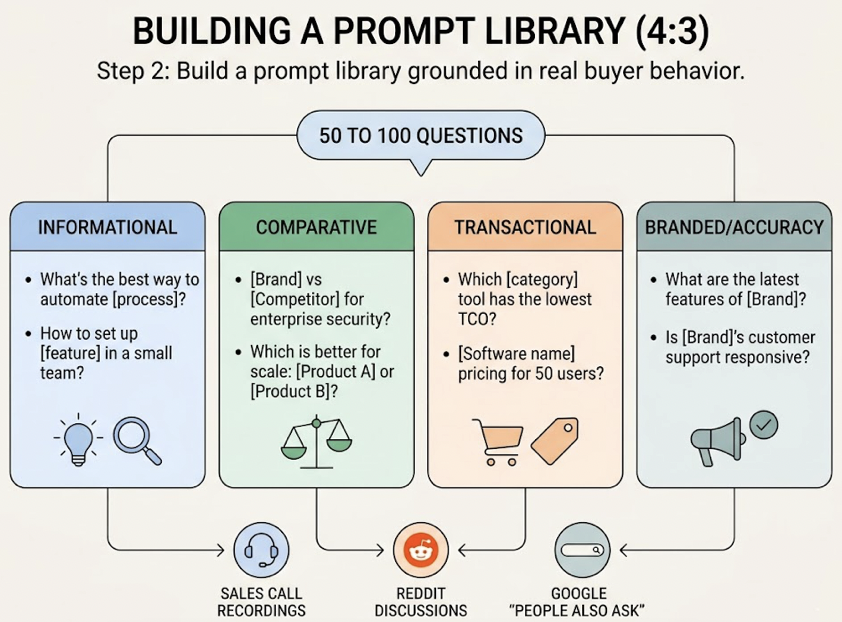
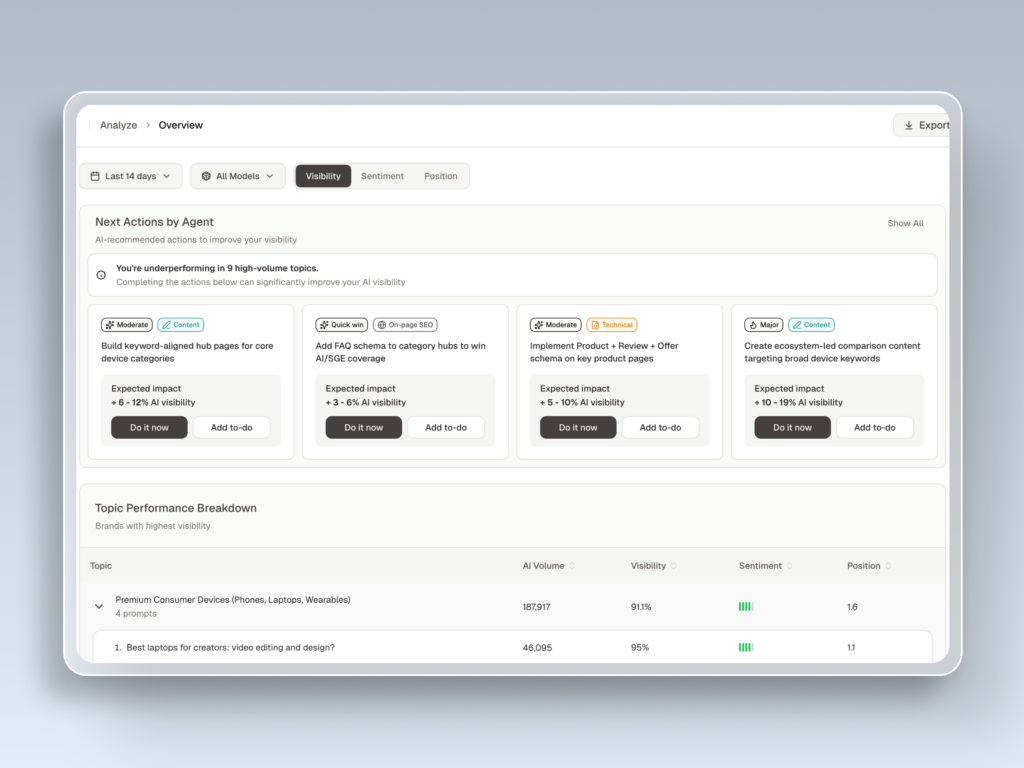
Because these systems are probabilistic, manual tracking is functionally impossible at scale. A single prompt yields slightly different answers across different users, locations, and timeframes. Platforms like Topify automate this by executing browser-rendered simulations across multiple engines, capturing what real users see rather than sanitized API outputs. The workflow follows four steps: construct a prompt playbook from sales call data and community forums, measure a multi-model baseline across 7+ engines with 3-5 regenerations per prompt, diagnose citational gaps, then surgically optimize and re-evaluate.
For teams tracking 100+ prompts across multiple platforms, this loop needs to run continuously. Topify’s Basic plancovers 100 prompts with roughly 9,000 AI answer analyses per month. The Pro plan expands to 250 prompts and 22,500 analyses for teams managing multiple brands or competitive categories.
From Data to Action: Turning AI SOV Into Strategy
Once you’ve mapped your Share of Voice, the remediation playbook differs fundamentally from traditional SEO. Three scenarios cover most situations.
When Your Mention Rate Is Below 10%
If you have strong Google rankings but remain invisible across AI engines, the issue is typically structural. JavaScript-heavy sites that rely on client-side rendering suffer a 60% reduction in AI citations because AI bots prioritize the initial server-side HTML return. Security configurations like Cloudflare may accidentally block crawlers like GPTBot.
Once technical access is secured, content needs restructuring using the Bottom Line Up Front (BLUF) rule. Research shows that 44.2% of all AI citations are extracted from the first 30% of an article. Place direct, sentence-level answers within the first 100 words of every major heading section.
Landmark research from Princeton University quantified the content transformations that drive AI citability: expert quotations lift visibility by 41%, factual statistics by 30%, inline citations by 30%, and technical terminology by 28%. Keyword stuffing, on the other hand, reduces visibility by 9%.
When Your Position Is Low and Sources Are Thin
If you’re mentioned but routinely buried at the bottom of recommendation lists, the model lacks sufficient third-party corroboration. The fix lives off your owned website.
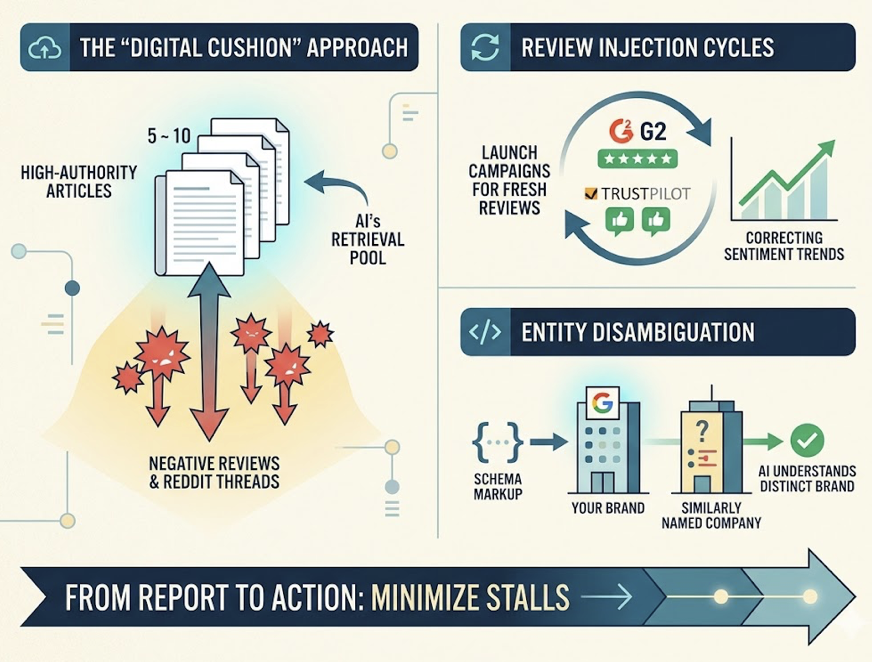
Average AI citation distributions trace to established sources: industry publications and news (34%), YouTube video transcripts (23.3%), Wikipedia (18.4%), and Google ecosystem domains (16.4%). User forums like Reddit and Quora carry heavy weight with models like ChatGPT. Maintaining an active, highly reviewed profile on directories like G2 or Capterra increases a brand’s probability of being cited in ChatGPT by 3x.
When Sentiment Is Negative or Drifting
A negative sentiment score anchors your SOV. Conversational systems synthesize public opinion, aggregating negative reviews and unresolved issues into authoritative summaries. Brands must also watch for “Semantic Drift,” where the AI’s internal representation diverges from reality: outdated pricing, discontinued features, or misclassified positioning. A drop in embedding similarity below 0.95 indicates the AI’s portrayal has diverged from your actual offerings.
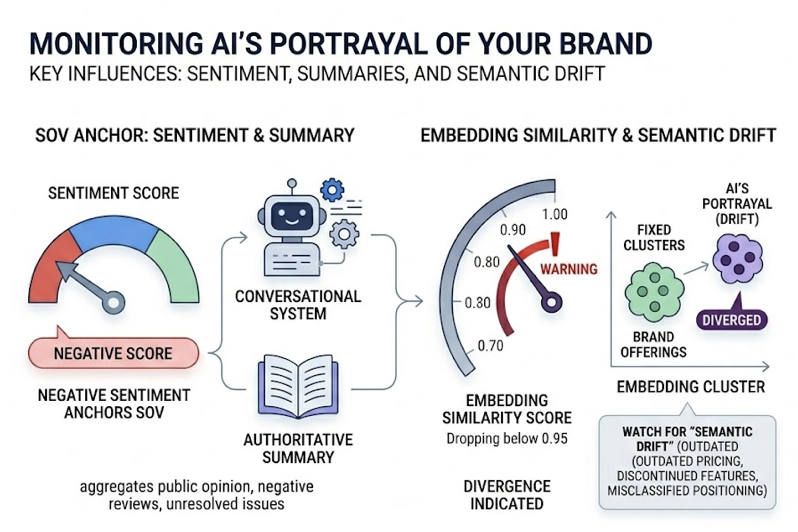
The fix: audit the citations behind the negative summaries, refresh old product pages (content updated within the last 90 days increases selection likelihood by 2.3x), and launch targeted review generation on the cited platforms to dilute negative semantic signals.
By deploying automated suites like Topify, teams can run this optimization loop continuously: monitoring mentions, diagnosing citational gaps, and using one-click execution to restructure pages before competitor-driven divergence erodes market share.
Conclusion
Traditional metrics like keyword rankings and organic impressions no longer capture the true path to revenue. Conversational search operates on a zero-sum, binary model: your brand is either integrated directly into the synthesized output as a trusted recommendation, or it’s invisible.
Measuring AI Share of Voice isn’t a peripheral experiment. It’s a board-level indicator of future market share. By establishing an open-denominator measurement framework, tracking the five core metrics across multiple AI platforms, and connecting upstream visibility to downstream conversions, marketing teams can replace guesswork with precision. The brands that build this measurement layer now will be the ones AI systems recommend six months from now.
FAQ
Q: What is share of voice in AI search?
A: Share of Voice in AI search represents the percentage of brand mentions and recommendations a company receives compared to all competitors across synthesized AI responses. Unlike traditional search metrics that track ad spend or link-based rankings, AI SOV measures how often a brand is included when conversational assistants like ChatGPT, Perplexity, and Gemini recommend solutions within a given category.
Q: How is AI search visibility different from traditional SEO?
A: Traditional SEO focuses on optimizing URLs to rank on search engine results pages through link building and keyword optimization. AI search visibility focuses on being cited, referenced, and recommended directly within AI-generated answers. While traditional SEO relies on domain-level backlink profiles, AI visibility is driven by semantic clarity, structural extractability (clean tables, data lists), factual corroboration across third-party sites, and overall entity authority.
Q: Which AI platforms should I track for share of voice?
A: A reliable strategy should cover at least three to four platforms: ChatGPT for general search behavior, Gemini for performance within Google’s ecosystem and AI Overviews, Perplexity for technical and research-oriented queries, and Microsoft Copilot for enterprise audiences. For global brands, adding engines like DeepSeek, Doubao, or Qwen provides critical visibility in non-English markets.
Q: How often should I measure AI share of voice?
A: Because LLMs update frequently and competitors continuously push fresh content, monthly or bi-weekly tracking is the baseline standard. Enterprises should use automated tracking systems for continuous monitoring, since citation drift rates of 40-60% per month mean manual audits are always looking at stale data.