Open ChatGPT, type “best [your category] tool,” and watch what comes back. If your brand isn’t in that five-line answer, you’ve already lost the prospect before they ever hit your homepage. Most marketing teams figured this out in 2025, when AI Overviews started cutting Position 1 organic clicks by more than half. The instinct is to throw more SEO content at the problem. That’s the wrong move. AEO runs on a different ruleset, and the brands winning right now started by tearing up the old playbook.
Why AEO Has Become Non-Optional in 2026
The numbers don’t leave much room for debate. ChatGPT now sees 900 million weekly active users and processes 2.5 billion prompts per day. Google’s AI Overviews reach roughly 2 billion users a month. For high-income households, AI has already replaced traditional search as the starting point for local discovery.
The CTR data is uglier. When an AI Overview shows up on a search result page, organic CTR drops from 1.76% to 0.61%, a 61% decline. Paid CTR on informational keywords falls 68% in the same conditions. Position 1 organic CTRloses 58% of its historical value when an AIO is present.
But here’s the part most people miss: brands cited inside the AI answer get 35% more organic clicks and 91% more paid clicks than non-cited brands appearing on the same query. The penalty isn’t for AI search itself. It’s for not being selected.
That’s the gap an AEO strategy is built to close.
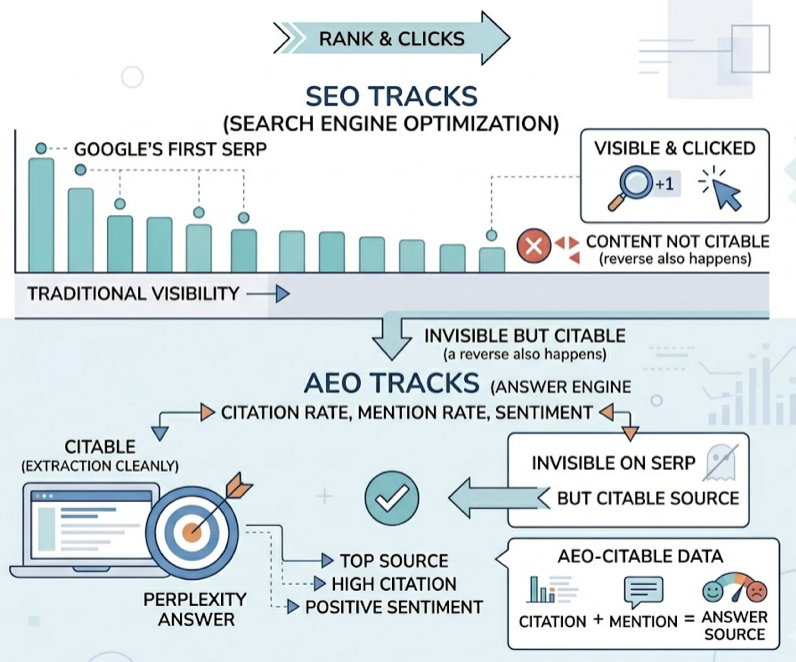
AEO vs SEO vs GEO: What’s Actually Different
AEO, SEO, and GEO get used interchangeably, and the confusion is costing teams real budget. Each one optimizes for a different mechanic.
SEO is still about ranking pages in a list of links. The metric is rank position and click-through rate. It’s the foundation that gets your content crawled and indexed in the first place.
Answer Engine Optimization is narrower and more aggressive. It targets the direct-answer real estate: featured snippets, voice responses, and the synthesized blocks inside ChatGPT or AI Overviews. The goal isn’t a click. It’s being the source the AI quotes.
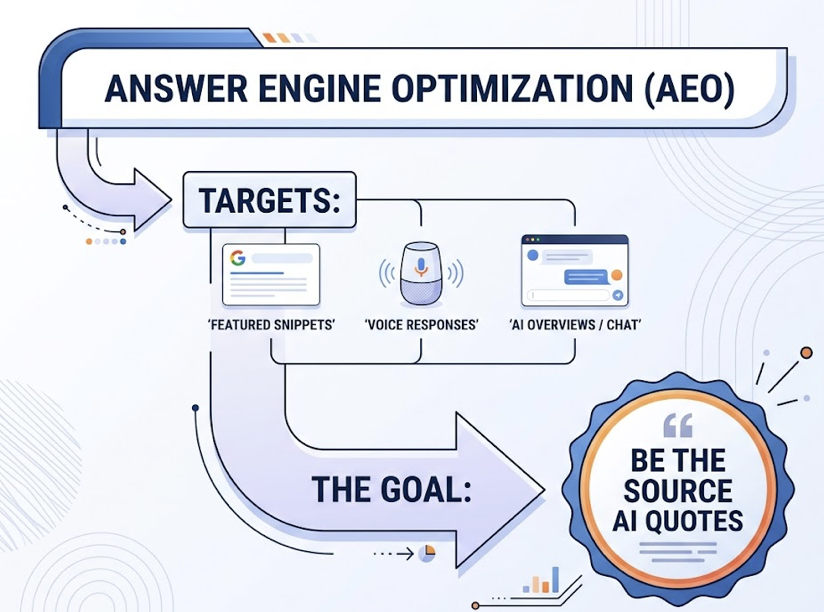
GEO sits on top. It shapes how an LLM understands your brand as an entity, who you are, what category you own, and which competitors you sit beside. GEO works across the dataset and retrieval layer, not just on individual pages.
Bottom line: SEO gets your content in. AEO gets it selected. GEO makes sure the AI’s mental model of your brand stays accurate and positive. You need all three. AEO is the fastest one to move on right now.
Step 1: Audit Your Baseline and Open the Door for AI Crawlers
Before you optimize anything, find out where you actually stand. Most teams skip this step and run blind for six months.
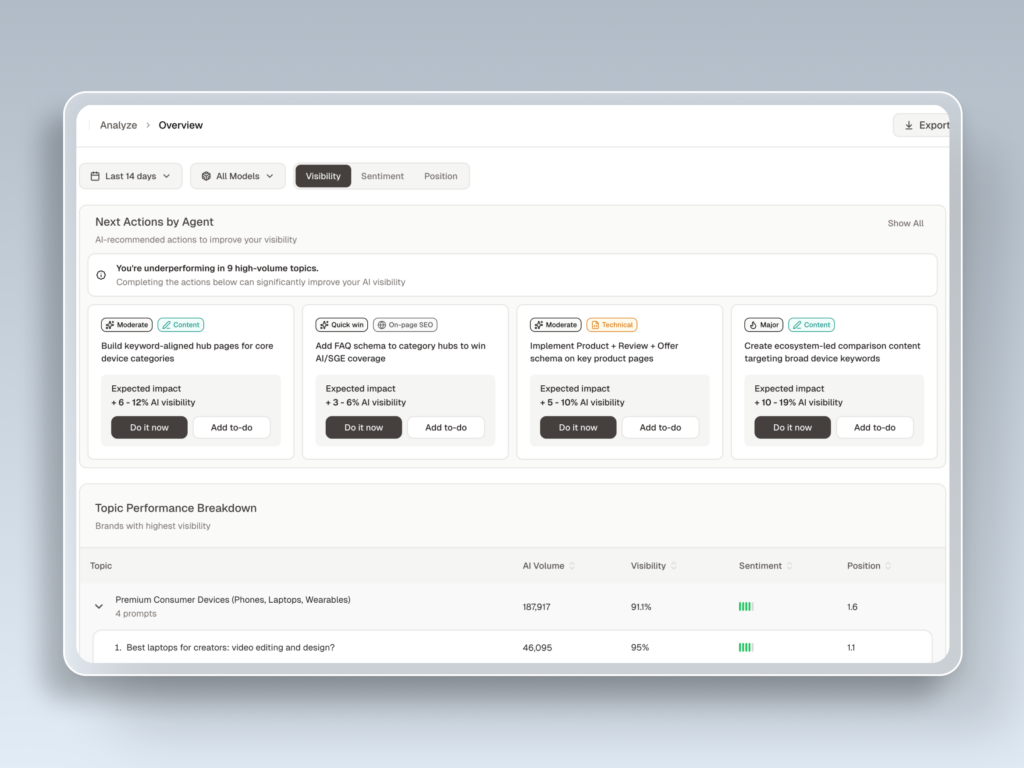
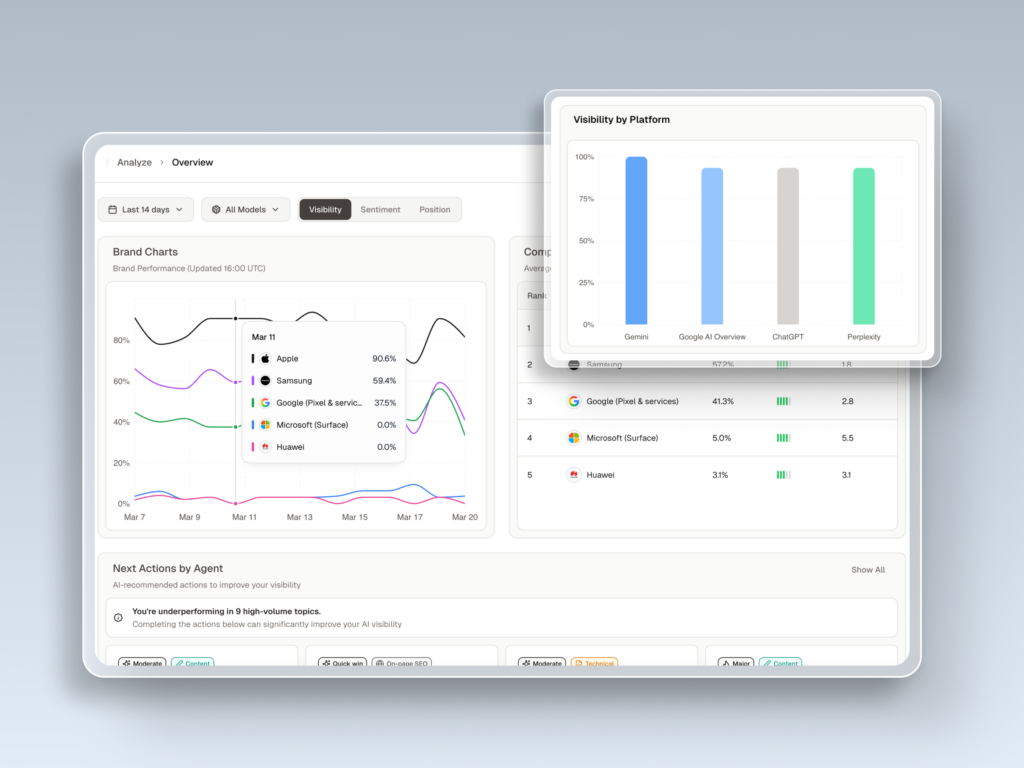
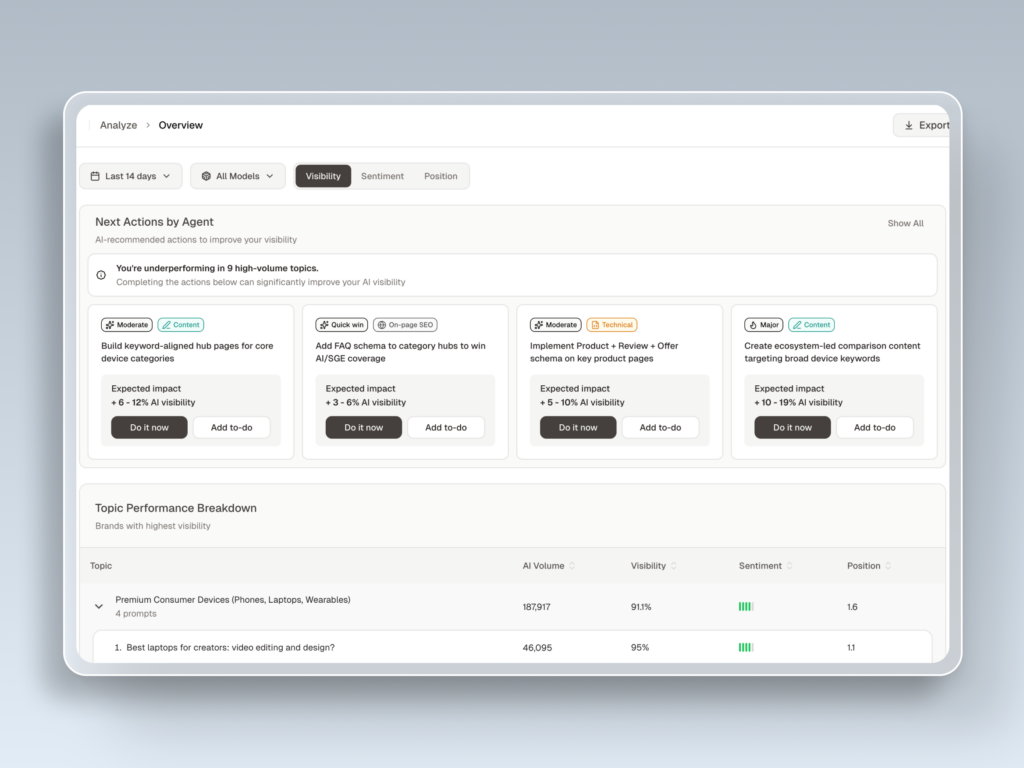
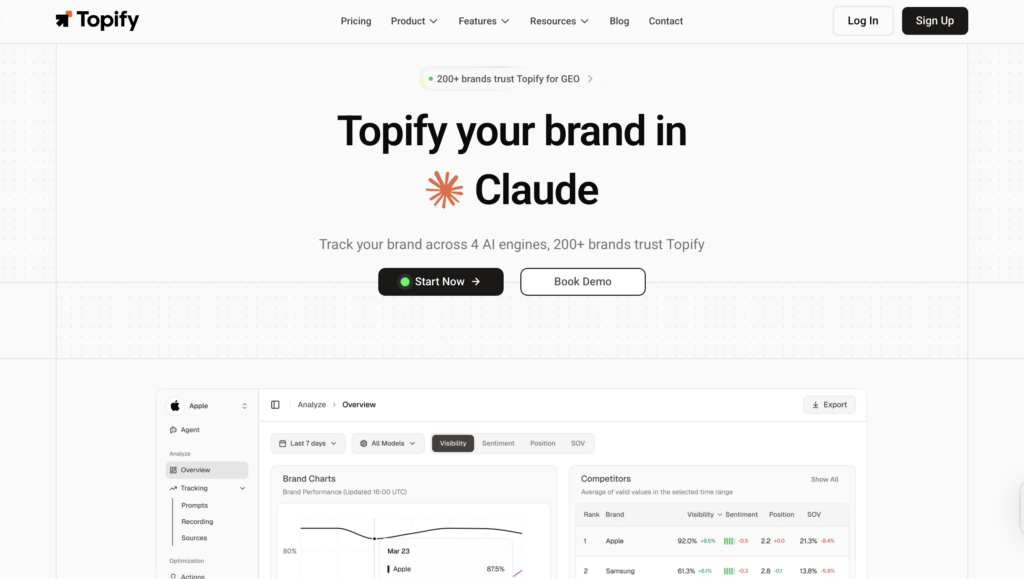
Start with a baseline measurement across the four engines that matter: ChatGPT, Perplexity, Gemini, and Google AI Overviews. Track three things per engine: are you mentioned, are you cited with a link, and where do you sit relative to competitors. This is what Topify‘s Visibility Tracking was built for. Pick a fixed list of 50 to 100 buyer prompts and re-run them weekly so you have a moving baseline, not a one-time snapshot.
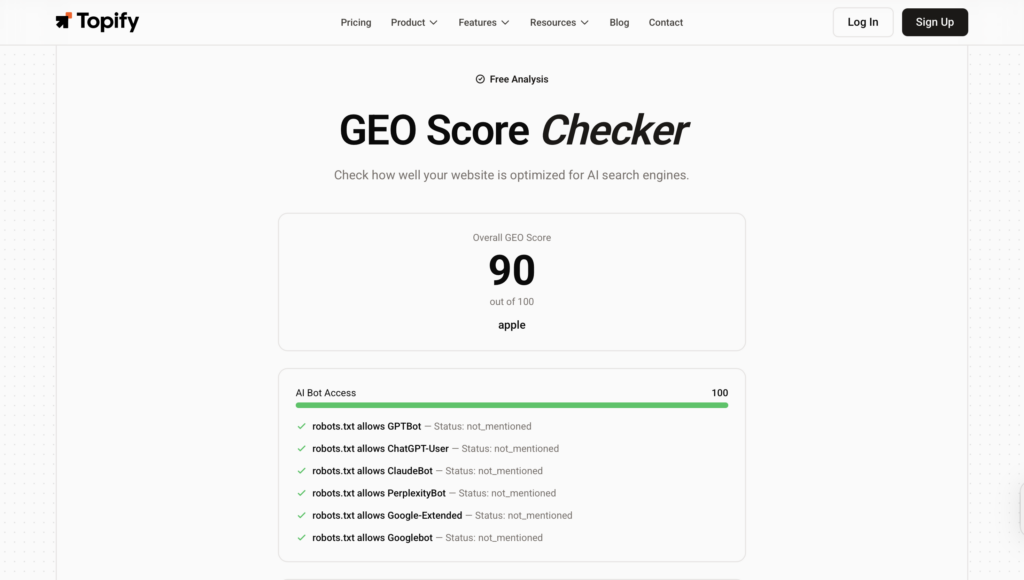
Then check the door is unlocked. Audit your robots.txt for GPTBot, ClaudeBot, PerplexityBot, and Google-Extended. Plenty of brands are technically invisible to AI engines because someone copied a default block-list two years ago.
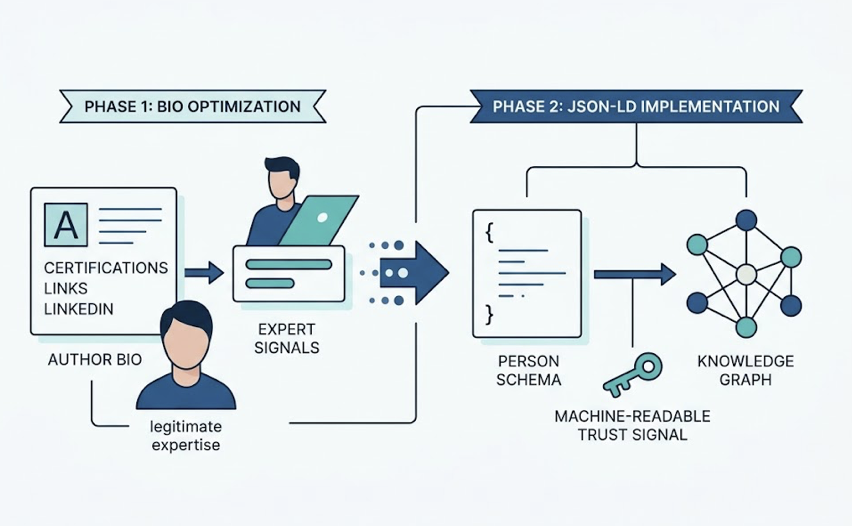
Add an llms.txt file at the root of your domain. It’s a 2026 standard that tells AI systems how to attribute your content, which datasets are approved, and where to find author bios. Think of it as a robots.txt for the answer era.
Finally, validate your schema. FAQPage, HowTo, and Article markup should match the on-page content exactly. AI models flag inconsistency as a low-trust signal and skip the page when synthesizing.
Step 2: Find the Prompts Your Buyers Actually Ask
AEO doesn’t run on keywords. It runs on prompts, the actual phrasing buyers use when they ask an AI for a recommendation.
The shape is different. A keyword like “crm software” becomes a prompt like “what’s the best CRM for a 10-person sales team that already uses HubSpot.” The intent is denser, the context is richer, and the answer the AI gives is shorter.
Map your prompts across three intent layers:
Informational: “what is AEO” / “how do I track AI search visibility.” These build mind share. Low conversion, high authority compound.
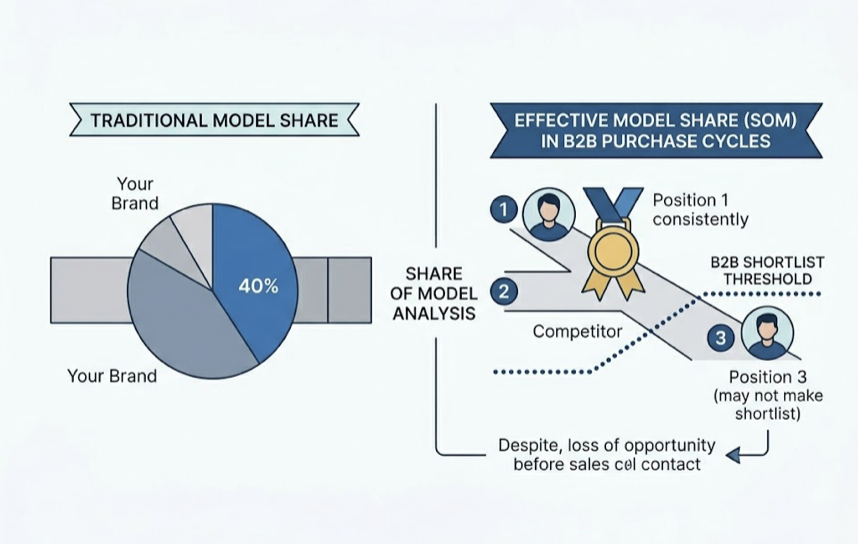
Comparison: “best AEO tools” / “Topify vs Profound.” This is the consideration set. If you’re not on the AI’s shortlist here, the deal is already lost.
Transactional: “cheapest annual plan for [category]” / “how to sign up for [product].” This is where revenue lands.
Use AI Volume Analytics to surface high-volume prompts you’re not currently visible on. Manually guessing prompts is the most common mistake in this step. AI prompt distribution doesn’t mirror Google keyword data, and the gap is wider than most teams expect.
Step 3: Reverse-Engineer the Sources AI Already Cites
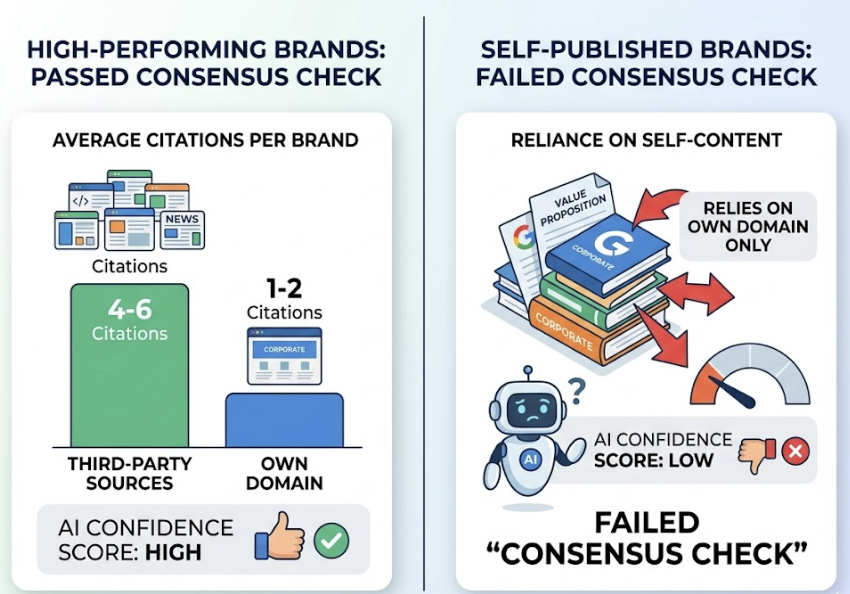
Here’s the part that breaks most brand strategies: 95% of AI citations come from sites you don’t own.
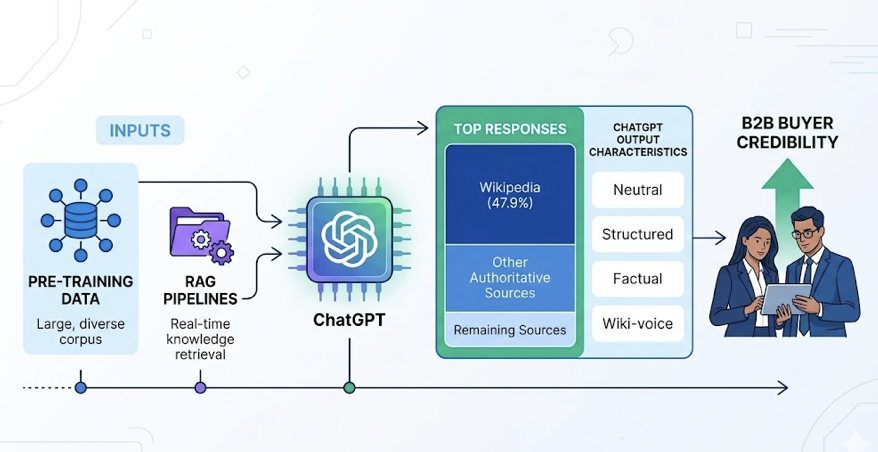
The data is brutal on the question of where AI looks. Reddit accounts for 46.7% of Perplexity citations and 21% of Google AI Overview citations. Wikipedia drives 47.9% of ChatGPT citations. YouTube sits at roughly 18.8% on AIO. Brand websites collectively pull about 9%.
That doesn’t mean your site is irrelevant. It means your site can’t carry the AEO load alone. AI engines need consensus across independent voices before they’ll quote you. If the only place you’re discussed is your own marketing copy, the model treats that as biased and skips it.
Run a source audit. Use Source Analysis to pull every domain currently cited for your top 50 buyer prompts. You’ll usually find three patterns:
Competitors dominating Reddit threads where your category gets discussed. Wikipedia entries for adjacent topics that don’t mention your brand. Industry media and listicles that reference everyone except you.
Each gap is a fixable surface. Reddit isn’t a place to advertise. It’s a place to participate as an expert contributor in threads your buyers already read. Wikipedia entries get built from authoritative third-party citations, not from your blog. Listicles get refreshed when someone reaches out to the author with sharper data.
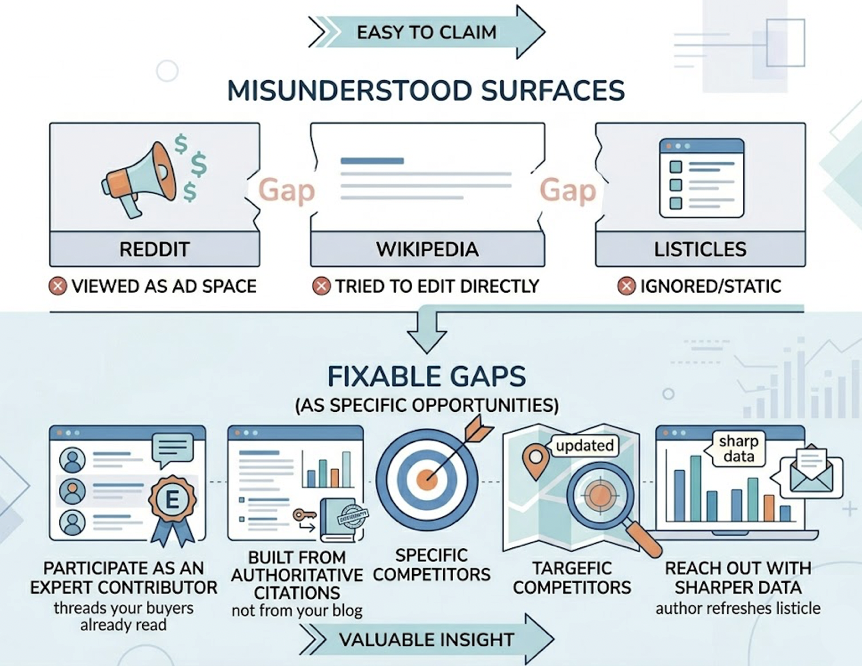
That’s the actual off-page AEO playbook. Most teams skip straight from auditing to writing more blog posts. They write into a vacuum because nobody told them where AI was looking.
Step 4: Build Content Designed to Be Quoted, Not Just Ranked
AI engines don’t read pages the way humans do. They scan for modular chunks they can lift and synthesize. The structural rules are unforgiving once you see them.
55% of Google AI Overview citations come from the top 30% of a page. ChatGPT pulls 44.2% of its citations from that same zone. If your direct answer isn’t in the first 150 words, you’re outside the citation window before the AI even reaches the rest of your content.
The format that wins is what some teams call the Answer Capsule: a definitive, fact-dense summary in the opening section that contains the core answer plus original data. Pages built this way achieve a 72.4% citation rate. That’s roughly six times the rate of pages relying on traditional SEO intros.
A few writing rules that move the needle:
Put the literal answer to the H1 question in the first 50 words. No throat-clearing.
Phrase H2 and H3 headings as direct buyer questions. AI treats headings as prompts and the next paragraph as the response, which is why 78.4% of question-based citations come from headings.
Replace adjectives with numbers. “Significantly improved performance” gets ignored. “Cut response time by 47%” gets quoted.
Update content within the last 90 days where possible. Recently refreshed content is twice as likely to be cited.
The goal isn’t to write longer. It’s to write more extractable.
Step 5: Track Citations, Sentiment, and Close the Loop
AEO isn’t a launch project. It’s a monitoring system, and the brands that treat it as one-and-done lose ground fast because AI citation patterns shift every few weeks.
Three metrics need to be on your dashboard:
Share of Model: Your visibility share across ChatGPT, Gemini, Perplexity, and AI Overviews. Track it weekly. A drop that lasts more than two weeks is signal, not noise.
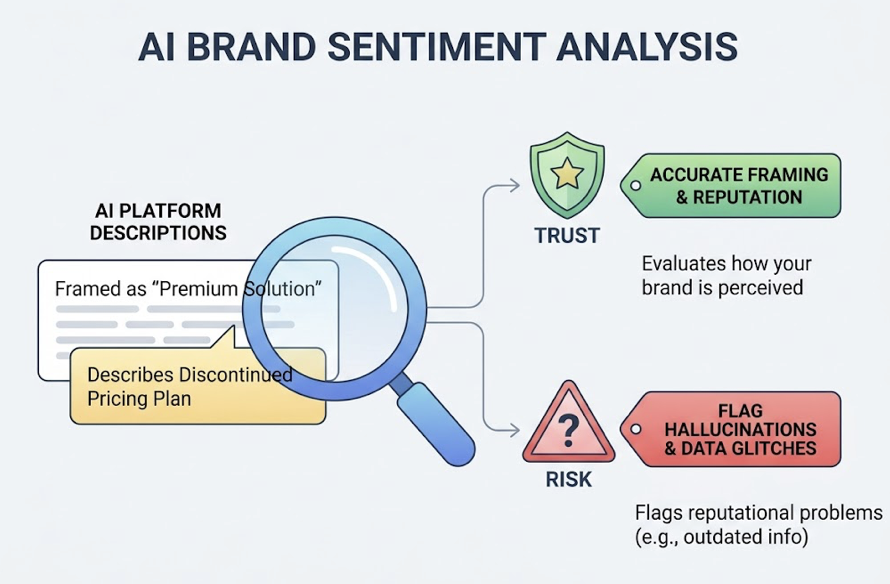
Sentiment Velocity: Not just whether AI mentions you, but how. Sentiment shifts are leading indicators of pricing perception, support quality, or messaging drift. Sentiment Analysis scores brand mentions on a 0 to 100 scale and flags directional changes before they show up in revenue.
Hallucination Alerts: AI sometimes states confident, wrong things about your brand: outdated pricing, deprecated features, or competitor confusion. Catching these early lets you target the source URL the AI is pulling from for a correction.
Wire this into your existing analytics stack. AEO data isn’t a separate workflow. It’s another layer on the same dashboard your SEO team already checks. The teams that close this loop weekly tend to compound visibility gains. The ones that report quarterly tend to discover problems three months too late.
Where Most AEO Strategies Fall Apart
Most AEO failures look the same. Four patterns show up over and over:
Treating AEO as a content problem. The fix is infrastructure first—crawlers, schema, llms.txt—then content. Skipping infrastructure means AI engines can’t read what you wrote.
Tracking only one AI engine. ChatGPT alone is 60 to 65% of generative search volume, but Perplexity, Gemini, and AIO behave differently and cite different sources. Single-engine monitoring misses 35% of the picture by definition.
Keyword stuffing into AI-era content. Repetition adds noise. AI models reward clarity and definitive language, not density.
Promotional tone. Content that sounds like an investor deck gets filtered as low-confidence. Brands that sound like teachers, showing data, naming sources, walking through process, dominate citations.
Spot any of these in your current approach and fix the infrastructure layer before writing another article.
The AEO Tooling You’ll Need to Run This Playbook
You can run this playbook with a stack of separate tools. Most teams that try end up with five dashboards, three logins, and no single view of what’s actually changing.
Topify was built to consolidate the AEO measurement layer into one platform. Visibility Tracking covers ChatGPT, Gemini, Perplexity, AI Overviews, and adjacent engines like DeepSeek and Doubao for global brands. Source Analysis maps every domain cited for your priority prompts. Position Tracking shows where you sit in the AI’s ordered recommendation. Sentiment Analysis monitors directional shifts in how AI describes your brand. AI Volume Analytics surfaces high-value prompts before competitors notice them.
In practice, that means a marketing lead can spot a drop in ChatGPT mentions and trace it back to a specific Reddit thread that stopped recommending the brand, inside one dashboard, not five.
Pricing starts at $99/month for the Basic plan, which covers 100 prompts and four projects. Most mid-market teams land on the Pro tier at $199/month. You can get started on a 7-day trial without committing to annual billing.
The point isn’t that Topify is the only way to execute AEO. It’s that the brands moving fastest in 2026 aren’t pasting together five tools. They’re working off a single source of truth and acting on it weekly.
Conclusion
Open ChatGPT again. Type the same prompt. The brand sitting in the answer slot didn’t get there by ranking harder. It got there by mapping the right prompts, restructuring its content for extraction, building third-party signals on Reddit and Wikipedia, and tracking citations weekly.
The five steps in this playbook compound. Most teams see meaningful citation lift within 60 to 90 days once infrastructure and content are aligned. The cost of waiting another quarter is harder to calculate, but the CTR data suggests it’s not zero. In the answer era, if you’re not the source the AI quotes, you’re not in the consideration set.
FAQ
Q: How long does it take to see results from an AEO strategy?
A: Most teams see initial citation lift within 60 to 90 days after fixing infrastructure issues and publishing answer-first content on priority prompts. Sentiment changes and consistent Share of Model gains usually take 4 to 6 months. The biggest variable is how much off-page work (Reddit, Wikipedia, industry media) the team is willing to do alongside the on-site changes.
Q: Is AEO replacing SEO, or do I still need both?
A: You need both. SEO ensures your content gets crawled and indexed in the first place, which is the precondition for AEO. AEO then determines whether AI engines select your content for direct answers. Treating them as competing strategies is one of the main reasons AEO programs fail.
Q: Do small brands have any chance against big brands in AI search?
A: Yes, often more than in traditional SEO. AI engines favor specific, authoritative content over domain authority alone. A focused brand with answer-first content and strong Reddit presence in its niche can outrank larger competitors who rely on broad, promotional copy.
Q: How is AEO different from GEO (Generative Engine Optimization)?
A: AEO targets specific direct-answer placements like featured snippets, AI Overviews, and voice responses. GEO is broader and shapes how an LLM understands your brand as an entity across its entire knowledge base. AEO is tactical and faster to execute. GEO is strategic and compounds over longer timeframes. Most mature programs run both in parallel.