A SaaS brand spent three months rewriting every product page. Sharper copy. More data. Better structure. Then someone asked ChatGPT to recommend tools in their category, and the brand wasn’t mentioned once.
The problem wasn’t the content. It was that GPTBot, OpenAI’s retrieval crawler, had been blocked by a single line in their robots.txt file. The AI never saw the page.
That’s what a GEO score is designed to catch. It’s not a single number measuring how “good” your content is. It’s a four-dimensional diagnostic that measures whether an AI can access your pages, understand them, trust them, and actually recommend you. Miss any one dimension and the others don’t matter.
As traditional search volume is projected to decline by 25% by late 2026, and 93% of AI sessions already end without a click to any external site, your brand’s presence inside AI-generated answers is no longer optional. It’s the only impression you might get.
What a GEO Score Actually Measures
GEO stands for Generative Engine Optimization. A GEO score quantifies how well a brand is positioned to be cited by AI platforms like ChatGPT, Perplexity, and Gemini.
Unlike an SEO score, which optimizes for “the click,” a GEO score optimizes for “the citation.” And the stakes are different: GEO-driven visitors convert at up to 12.9x higher rates than standard organic traffic. Each citation carries more weight than a standard impression ever did.
The four dimensions of a GEO score follow a strict causal sequence:
| Dimension | Analogy | What It Controls |
|---|---|---|
| AI Crawler Access | The Gatekeeper | Can AI find and fetch your pages? |
| Structured Data | The Translator | Can AI parse what your content means? |
| Content Signals | The Recommender | Does AI consider your content worth citing? |
| AI Visibility | The Screen Presence | How often does AI actually mention you? |
Each dimension is independent enough to diagnose separately. Together, they form a chain: a failure in Dimension 1 makes Dimensions 2, 3, and 4 irrelevant.
Dimension 1 — AI Crawler Access: Can AI Even Find Your Pages?
This is where most brands lose before they even start.
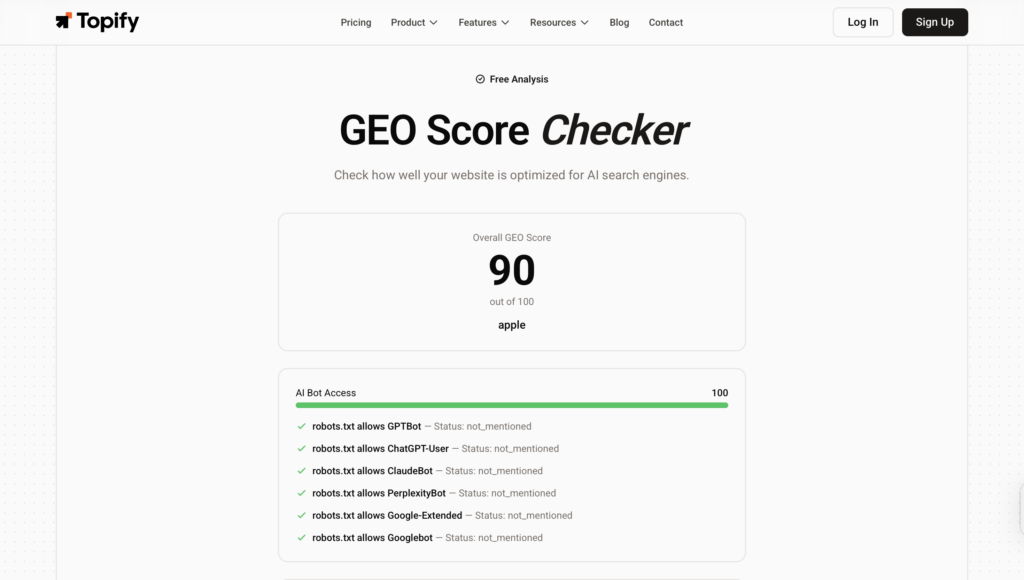
Modern AI platforms use dedicated crawlers to index content in real time. OpenAI alone runs three: GPTBot for model training, OAI-SearchBot for search indexing, and ChatGPT-User for live retrieval during conversations. Perplexity uses PerplexityBot. Anthropic uses ClaudeBot.
The problem is that many websites, particularly publishers and enterprise sites, have deployed blanket “Disallow” rules in their robots.txt files. According to data from Cloudflare and Buzzstream, 79% of top news sites block at least one AI training bot. Many are also unknowingly blocking retrieval bots in the same sweep — the bots that would actually drive citations and referral traffic.
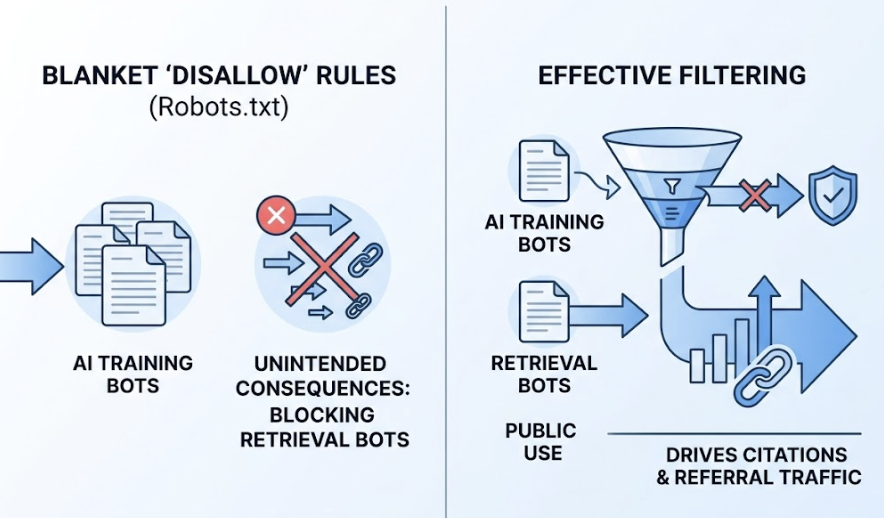
The distinction matters enormously. Blocking GPTBot (training) might be a reasonable business decision. Blocking OAI-SearchBot or ChatGPT-User is effectively opting out of appearing in ChatGPT responses entirely.
There’s a second technical layer: JavaScript rendering. Many AI retrieval pipelines cannot execute client-side JavaScript. They see a “ghost page” with none of the content that renders in a browser. Server-Side Rendering (SSR) or pre-rendering for bot traffic ensures that your actual content is visible during the initial fetch.
A brand can rank on page one of Google and remain completely invisible to a user asking ChatGPT the same question. Crawler access is the prerequisite for everything else.
Dimension 2 — Structured Data: Does AI Understand What You’re Saying?
Getting crawled is the baseline. Getting understood is the next gate.
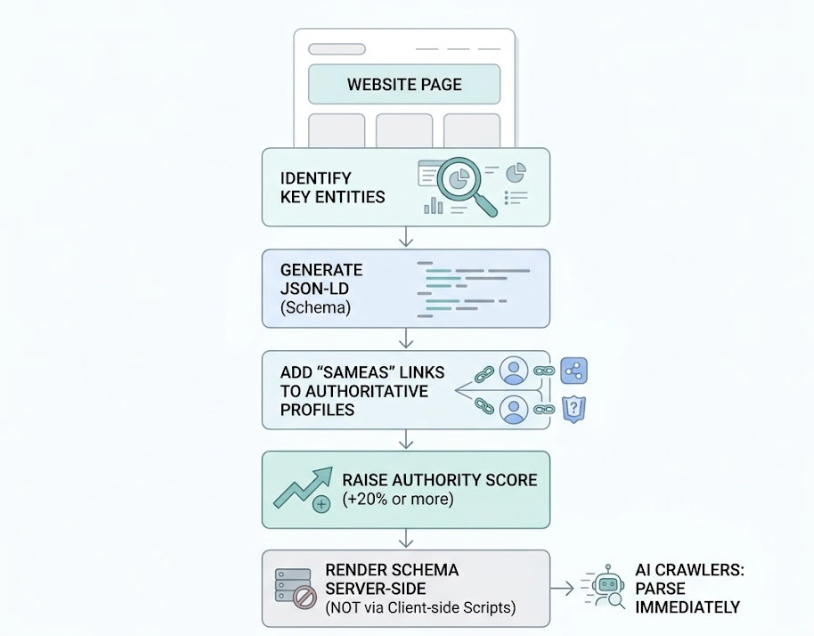
AI systems don’t read pages the way humans do. They use Named Entity Recognition and relationship mapping to build an internal knowledge graph of a topic. Structured data, specifically Schema.org markup in JSON-LD format, acts as a translator that removes the ambiguity from that process.
The most direct application is entity disambiguation. An Organization schema, linked via the sameAs property to verified profiles on Wikipedia, Wikidata, or LinkedIn, tells an AI model exactly who created the content and whether they’re credible. Without this layer, the AI is guessing.
Pages with well-implemented structured data are 36% more likely to appear in AI-generated summaries.
Among all schema types, FAQPage markup has the highest leverage for GEO. Google pulled back FAQ rich results from traditional SERPs in 2023, but AI platforms have moved in the opposite direction — they treat FAQ schema as a preferred extraction format. Because the question-answer structure is already pre-packaged, the AI can cite the content with high confidence without needing to interpret narrative prose.
The numbers bear this out: FAQ schema increases citation rates by 28% to 89%, and pages with FAQ schema are 3.2x more likely to appear in Google AI Overviews.
One important ceiling to understand: schema doesn’t substitute for authority. Research into ChatGPT’s citation patterns shows an “Authority-to-Schema” ratio of roughly 3.5:1. Perfect schema implementation adds around 10% weight to the citation evaluation. It’s a last-mile optimizer — it ensures strong content gets extracted accurately rather than skipped due to parsing errors. It can’t rescue weak content.
Dimension 3 — Content Signals: Is Your Content Worth Citing?
Assuming a crawler can access the page and the AI can parse its structure, the third question is whether the content itself earns a citation.
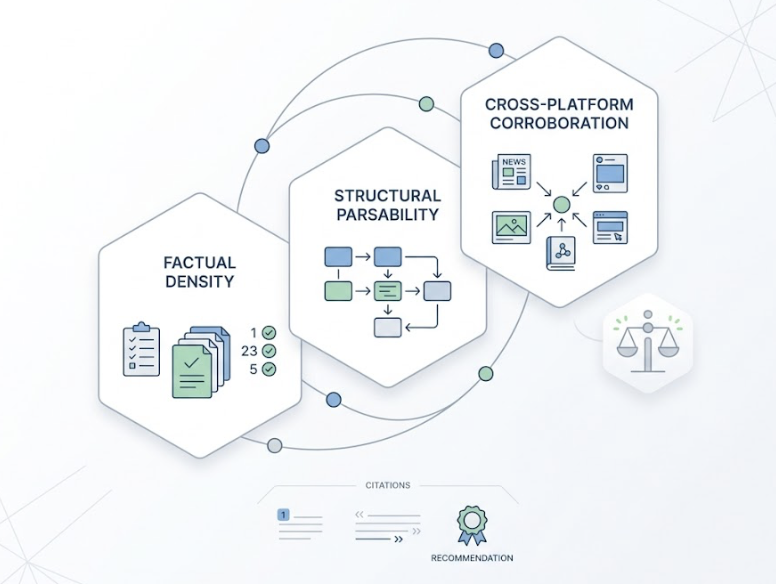
Generative engines are calibrated to provide accurate, specific answers. That shifts the content strategy away from keyword presence toward what researchers call “information gain” — data, claims, or findings that aren’t already present in the model’s training data.
Content format matters significantly. Comprehensive guides with supporting data have a 67% citation rate. Comparison matrices and review content come in at 61%. Opinion pieces and general thought leadership without supporting data average only 18%. AI systems value objective, extractable facts over subjective narrative.
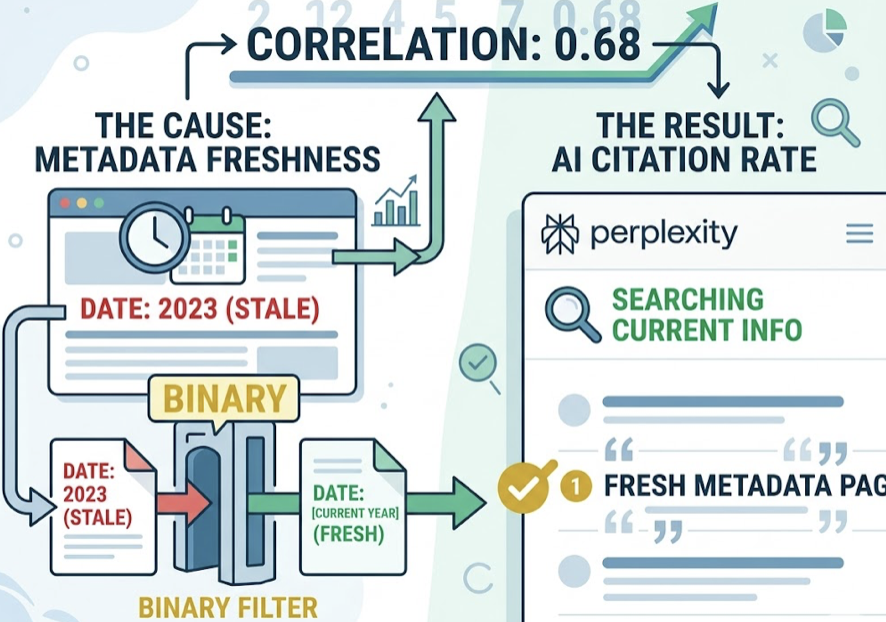
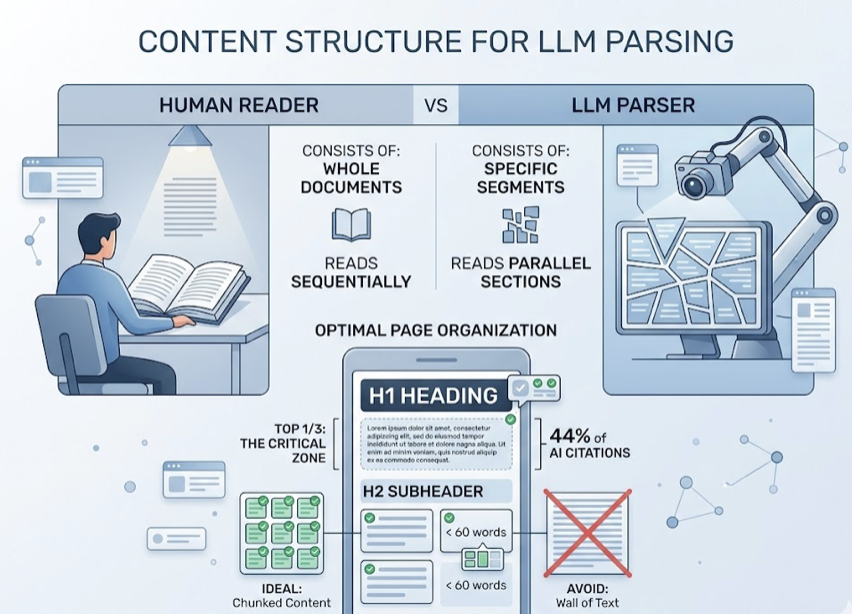
The placement of information on the page is equally important. An analysis of 1.2 million ChatGPT responses found that 44.2% of citations originate from the first 30% of a webpage. Burying the answer in a long narrative introduction is one of the most common and costly GEO mistakes. Pages that place a concise 40-60 word direct answer immediately after an H2 tag are cited 2.4x more often than those that don’t.
Quantitative specificity is also a consistent signal. AI systems show a 40% higher citation rate for content containing specific numbers and percentages compared to qualitative statements. The difference between “our software is fast” and “our software reduces latency by 40% according to the 2025 Benchmarking Report” is the difference between being invisible and being cited.
Semantic HTML tables and structured lists push that advantage further: structured formats produce 2.5x to 2.8x higher citation rates than plain text equivalents covering the same information.
Dimension 4 — AI Visibility: How Often Does AI Actually Mention You?
The first three dimensions are inputs. AI Visibility is the output. It measures how frequently and how favorably your brand appears inside AI-generated responses.
The key metric here is Share of Model (SoM), the GEO-era equivalent of Share of Voice. It’s calculated as the percentage of AI responses in a defined prompt set that mention your brand, relative to all brand mentions in that category.
$$\text{Share of Model} = \frac{\text{Responses Mentioning Your Brand}}{\text{Total Responses Mentioning Any Brand in Category}}$$
An AI mention rate of 10-15% across relevant prompts is considered healthy. Above 30% signals category leadership. But raw frequency isn’t the whole picture.
Position within a response carries significant weight. Brands named first in a recommendation list signal “primary entity” status and receive disproportionate user attention. Position tracking uses a weighted formula where the first mention carries 5x more value than the fifth.
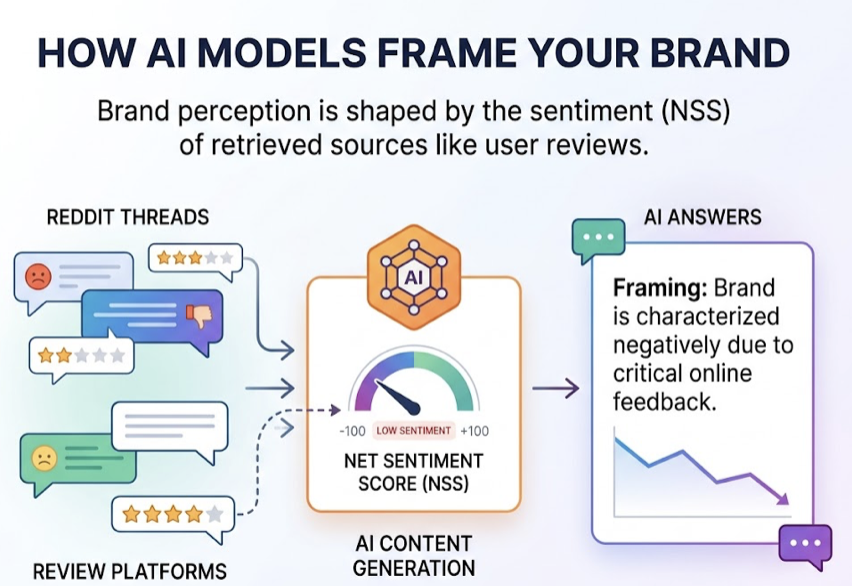
Sentiment is the other variable that raw visibility hides. A brand with 25% visibility and an 80/100 sentiment score will consistently outperform a brand with 40% visibility and a 50/100 sentiment score in actual conversion outcomes. Being mentioned frequently as “expensive and complex” is worse than being mentioned less often in a favorable context.
You can’t optimize what you can’t see.
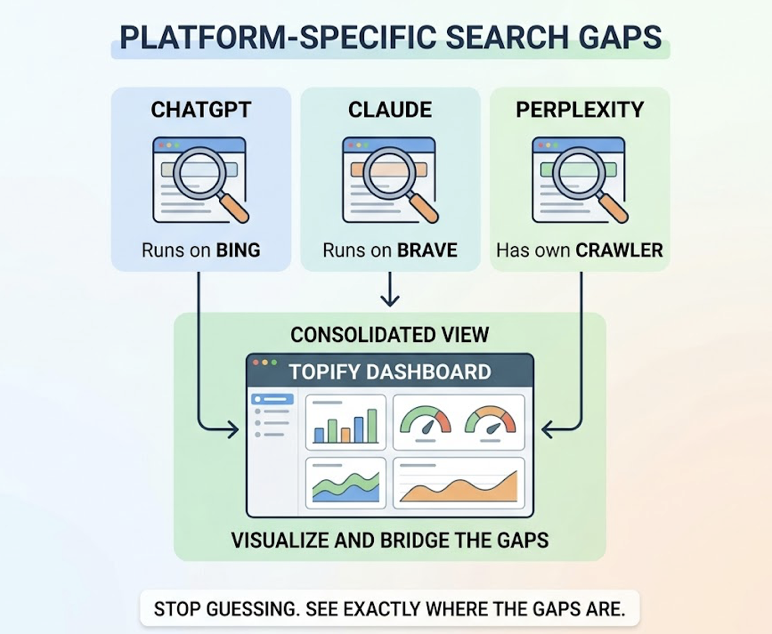
That’s why AI Visibility requires systematic, cross-platform monitoring across ChatGPT, Perplexity, Gemini, and others — not manual spot checks. The data changes fast: 40-60% of cited sources rotate monthly.
Why Your GEO Score Won’t Move If You Only Fix One Dimension
The most expensive GEO mistake is siloed optimization.
A brand invests in high-quality, well-structured content (Dimension 3) while their robots.txt blocks the crawlers that would retrieve it (Dimension 1). Result: zero improvement in AI visibility despite significant content investment. Researchers call this the “Invisibility Paradox.”
The four dimensions aren’t parallel tracks. They’re a sequence. Crawler access determines whether content can be ingested. Structured data determines whether ingested content can be understood. Content signals determine whether understood content is worth citing. AI visibility shows whether cited content is building brand presence.
The correct optimization order is:
- Verify crawler access for GPTBot, OAI-SearchBot, and PerplexityBot
- Implement Organization, Product, and FAQ schema with sameAs entity anchoring
- Restructure key pages for Answer Capsule format and quantitative density
- Monitor Share of Model, sentiment, and position across platforms
Research from Princeton and IIT Delhi confirms that applying these strategies systematically can boost brand visibility in generative responses by up to 40%. Sites in lower positions see even larger gains: pages ranking fifth see a 115% visibility increase after systematic GEO optimization. Quality of information can override historical domain authority in this environment.
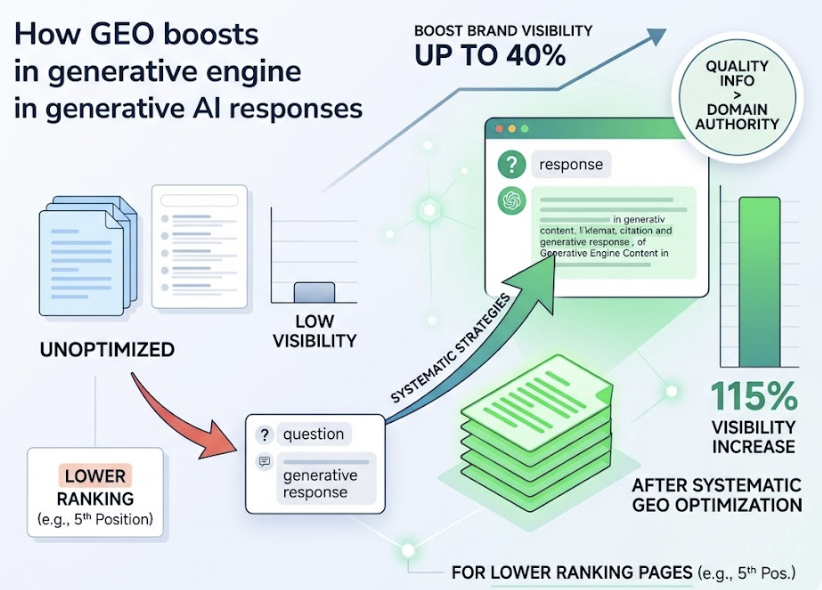
Prioritizing Dimension 1 before Dimension 3 isn’t just logical. It’s the difference between content investment that compounds and content investment that disappears.
Check Your 4-Dimension GEO Score Before You Optimize Anything
Before rewriting a single page or adding schema markup, you need a baseline. Otherwise, you’re optimizing blind.
Manually auditing all four dimensions requires technical crawl testing, cross-platform AI sampling, schema validation, and content analysis — running them together across multiple AI platforms takes significant time and specialized tooling most marketing teams don’t have in-house.
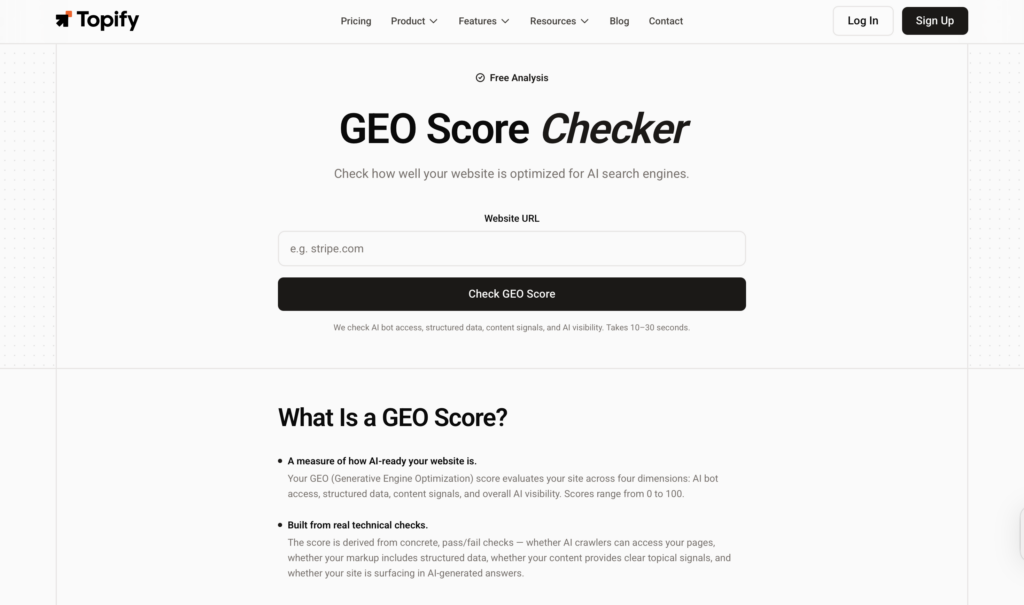
The Topify GEO Score Checker automates that diagnostic. It queries AI platforms directly in real time and returns a four-dimensional scorecard showing exactly where your scores stand across Crawler Access, Structured Data, Content Signals, and AI Visibility. It’s free to run, and it takes minutes rather than days.
One particularly useful output: the tool identifies “high-traffic, zero-citation” pages by correlating your existing traffic data with AI mention rates. These pages have the authority to rank but lack the formatting to be cited. They’re the highest-priority targets for structural optimization because the underlying authority is already there.
Once you know where each dimension stands, the next step is watching how they move. Topify’s continuous tracking feature monitors changes across all four dimensions over time, surfacing shifts in AI citation patterns and competitor positioning as they happen. When 40-60% of cited sources rotate monthly, point-in-time scores aren’t enough. Trend data is where the real strategic signal lives.
Conclusion
A GEO score isn’t a vanity metric. It’s a diagnostic framework for a search environment where 83% of AI-influenced queries produce no referral traffic and the only impression you may get is a mention inside someone else’s answer.
Each of the four dimensions does a specific job. Crawler access determines whether you exist in the AI’s retrieval window. Structured data determines whether the AI can accurately interpret what you’re saying. Content signals determine whether the AI considers your information worth recommending. AI visibility tells you whether all of that is actually working.
Fix one without the others and the chain breaks. Fix all four in sequence and you build the kind of citable authority that compounds — the type where being recommended once makes the next recommendation more likely.
The brands winning in AI search right now aren’t necessarily the biggest or the oldest. They’re the ones whose information is the most accessible, interpretable, and factually specific to the models making recommendations.
FAQ
What is a good GEO score?
A score above 85/100 is generally considered excellent, but aggregate scores can hide critical gaps. A brand might score 88/100 overall while scoring 9/100 on schema markup alone. That’s a fixable problem that aggregate visibility conceals.
How often should I check my GEO score?
AI citation data is volatile: 40-60% of cited sources rotate monthly. For competitive categories, weekly re-sampling is recommended. Citation data for informational queries typically decays to 40% of its initial level within 90 days without content refreshes.
Does a high GEO score affect Google rankings?
Indirectly, yes. 76% of AI Overview citations come from the top 10 organic results. Optimizing for entity clarity and structured data (Dimension 2) strengthens your representation in Google’s Knowledge Graph, which lifts organic rankings and increases AI Overview selection probability.
Can I improve all 4 dimensions at the same time?
Technically yes, but it’s inefficient. Brands should fix Dimension 1 (Crawler Access) before investing in content rewrites. Without confirmed crawler access, content improvements produce zero ROI in the AI ecosystem.
What’s the difference between an SEO score and a GEO score?
SEO scores optimize for the click — getting a user to visit your site. GEO scores optimize for the citation — getting an AI to recommend your brand inside its answer. GEO-driven visitors convert at up to 12.9x higher rates than traditional organic visitors, which changes the math on what a single citation is worth.