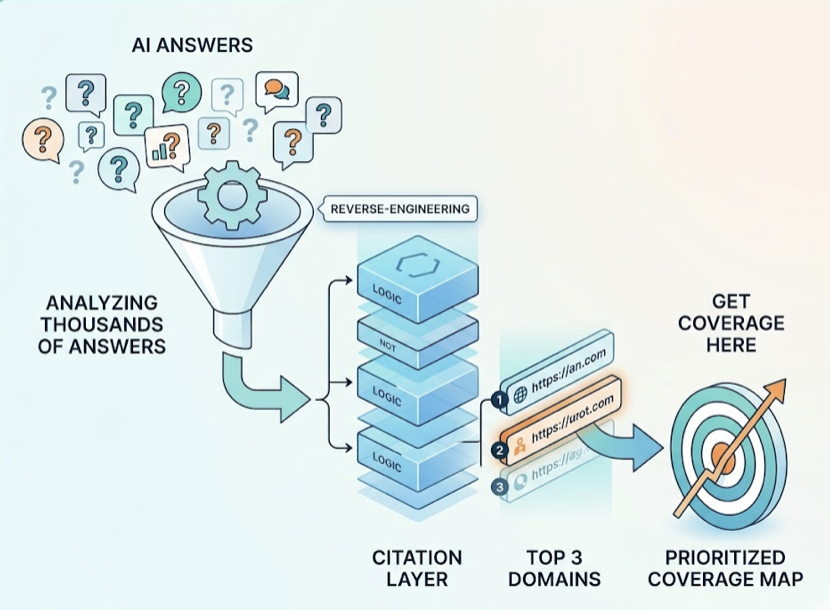
A practical guide to tracking your brand’s AI visibility, analyzing sentiment, and acting on the insights Claude surfaces.
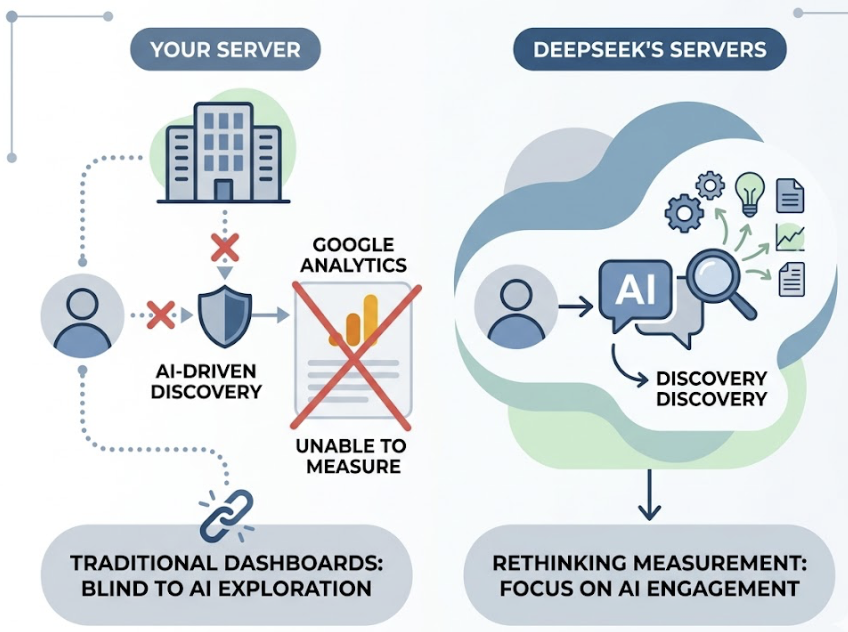
Your brand might be ranking well on Google and still be completely invisible to the people who matter most. As of early 2026, roughly 25% of Google searches trigger an AI Overview, and in certain high-intent categories, the zero-click rate inside Google’s AI Mode has reached 93%. That means a significant share of your potential buyers is getting their answers — and their recommendations — without ever clicking a link.
That’s not a traffic problem. It’s a visibility problem at a structural level.
Claude 4.7, released April 16, 2026, brings something most AI models lack for brand intelligence work: genuinely precise instruction-following and upgraded vision that lets it reason through complex, multi-source inputs. But it can’t crawl the web in real time, and it won’t automatically track what ChatGPT said about your brand last Tuesday.
This guide breaks down exactly what Claude 4.7 can do for brand monitoring, where it hits a wall, and how pairing it with a platform like Topify turns spot checks into a continuous optimization system.
Brand Monitoring Isn’t About Mentions Anymore
Traditional brand monitoring tracked hashtags on LinkedIn or X, set Google Alerts, and flagged press mentions. That’s still worth doing for PR response time. But it misses the channel that’s increasingly driving buying decisions.
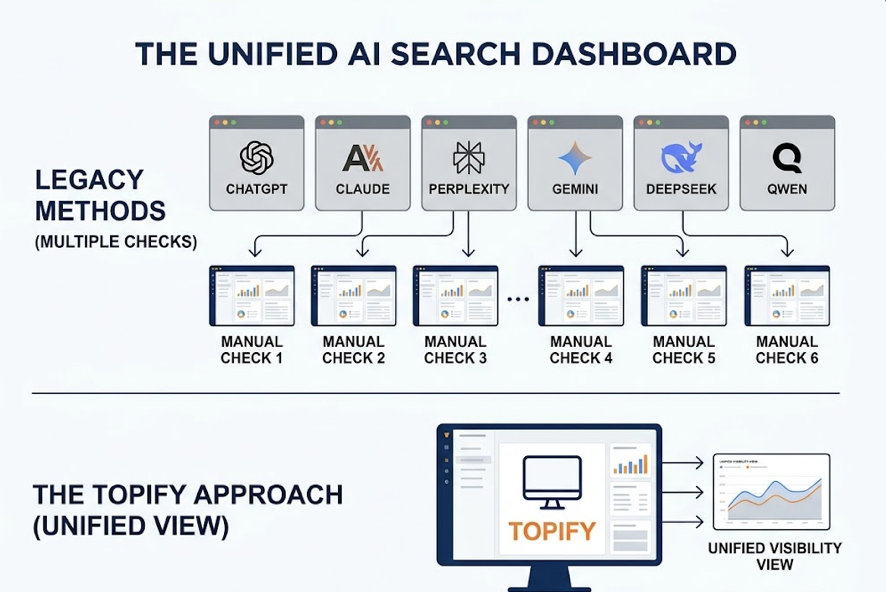
AI monitoring asks a different question: what does ChatGPT, Gemini, or Perplexity say when someone asks about your product category?
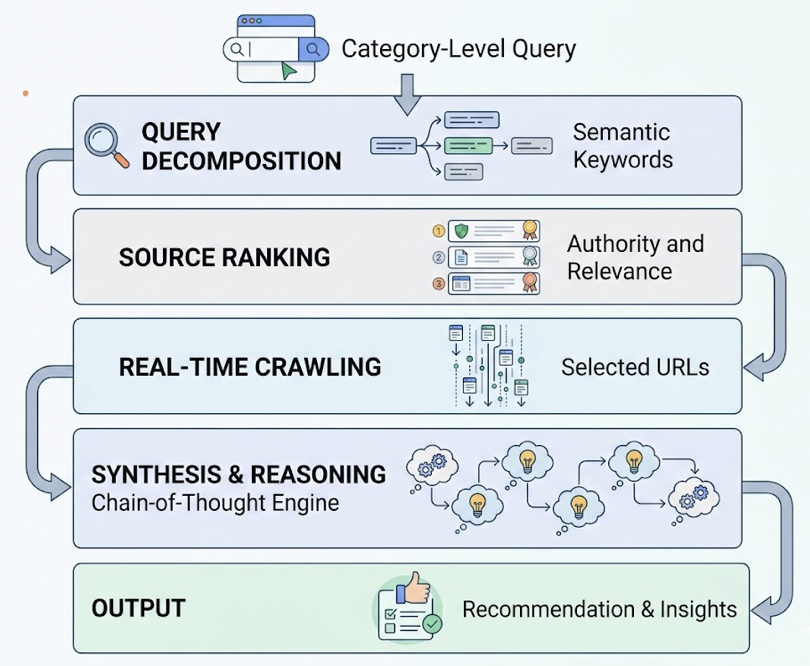
The answer matters more than a search ranking. Generative engines don’t present a list of options — they synthesize information and deliver a recommendation. If a user asks Perplexity for “the best project management tool for remote teams,” the engine produces a single, unified answer. If your brand isn’t part of that synthesis, you’re not in the consideration set before a single click can occur.
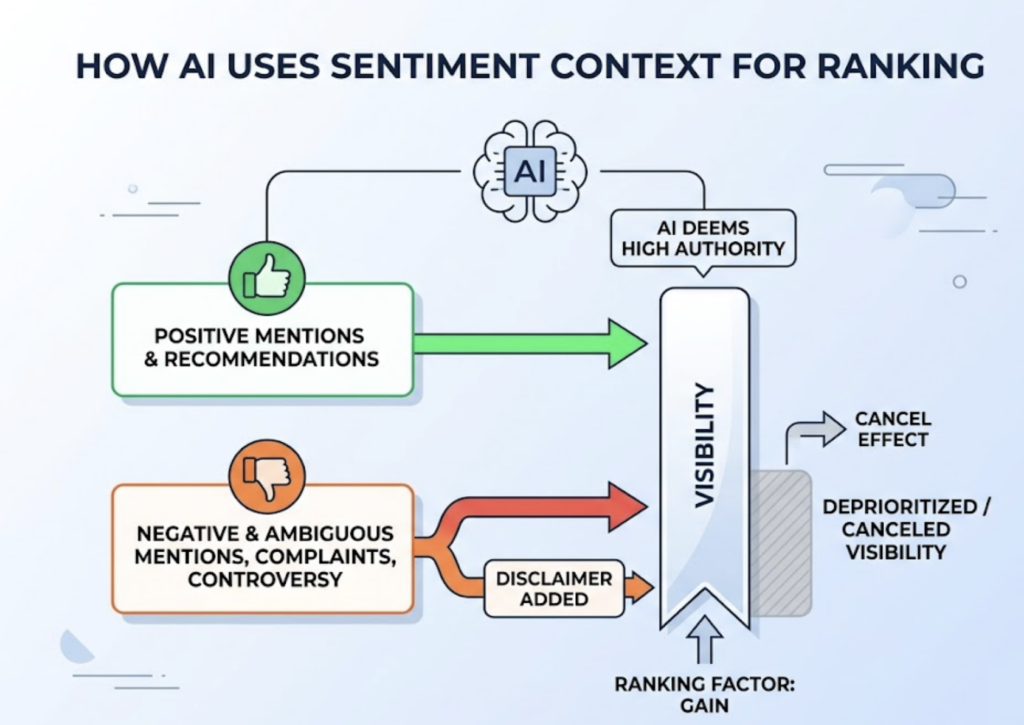
The conversion data confirms the stakes. AI-referred traffic in B2B SaaS converts at 14.2%, compared to 2.8% for traditional organic search. That’s a 5x premium. Visitors arriving from AI recommendations are already pre-qualified by the model’s summary. Being in the answer is worth more than ranking for the link.
There’s also a volatility problem that traditional monitoring wasn’t designed for. Only 30% of brands maintain consistent visibility across multiple regenerations of the same AI query. AI recommendations are probabilistic, not fixed. Monitoring in this environment means tracking statistical probability across dozens of prompt variations — not a single position on a results page.
What Claude 4.7 Can Actually Do for Brand Intelligence
Claude 4.7 is a reasoning model, not a crawler. That distinction matters for understanding where it genuinely helps.
Released on April 16, 2026, Claude Opus 4.7 introduced more literal instruction-following than its predecessors and significantly improved vision support, handling high-resolution images up to 2,576 pixels. For brand intelligence specifically, these upgrades unlock several capabilities that earlier versions couldn’t reliably deliver.
When you feed Claude 4.7 a set of AI-generated responses about your brand, it can identify subtle sentiment patterns, narrative drift, and framing inconsistencies across those outputs. It can also generate sophisticated prompt matrices — hundreds of natural-language queries mapped to different buyer intent stages — for teams that want to manually test brand visibility across platforms.
The upgraded vision support adds another dimension. Claude can now analyze screenshots of competitor dashboards or marketing materials and synthesize competitive positioning from visual inputs. That’s a meaningful unlock for understanding how rivals present themselves and how that might be influencing what AI models say about them.
The Limits You Need to Know Up Front
Claude 4.7 can’t independently check what ChatGPT is saying about your brand right now. It relies entirely on you to provide that data.
Session memory improved in this release, but it’s not the same as persistent, automated tracking. If you want to compare this week’s AI sentiment against last month’s, you have to bring the historical data yourself.
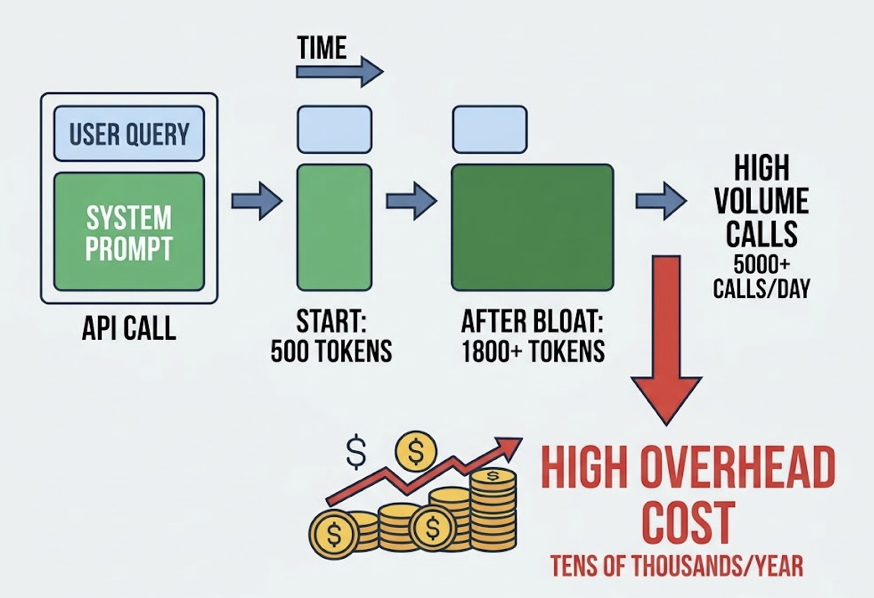
There’s also a cost consideration. Claude 4.7 uses a new tokenizer that can produce a token count 1.0 to 1.35 times higher than previous models for the same input. For teams running large multi-step analysis workflows, that “tokenizer tax” of up to 35% can add up quickly. The smart move is using Claude for high-value interpretation, not for repetitive data collection that a specialized tool handles more efficiently.
5 Claude 4.7 Brand Monitoring Tasks That Actually Work
The model’s strength is qualitative reasoning at depth. These are the five tasks where that translates directly into brand intelligence.
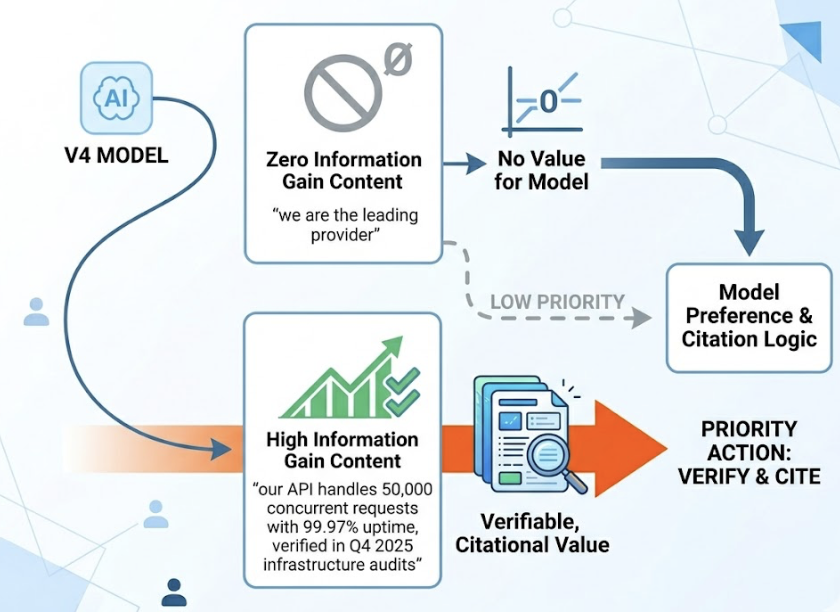
1. Sentiment analysis of AI-generated brand answers. Claude doesn’t just classify mentions as positive, neutral, or negative. It distinguishes between being “mentioned” and being “recommended” — and identifies the framing underneath. A brand appearing in 80% of AI answers but consistently described as “legacy software with a steep learning curve” has a visibility problem, not an asset. Claude can ingest those responses and analyze the specific value-adjectives the engine uses to characterize the brand.
2. Identifying framing gaps vs. desired positioning. This is one of Claude’s most useful second-order capabilities. A SaaS company might spend significantly on positioning itself as “the most secure enterprise solution,” but if AI engines consistently describe it as “easy to use for small teams,” there’s a structural failure in content distribution. Claude can compare your internal positioning documents against collected AI outputs and flag exactly which value propositions aren’t reaching the models.
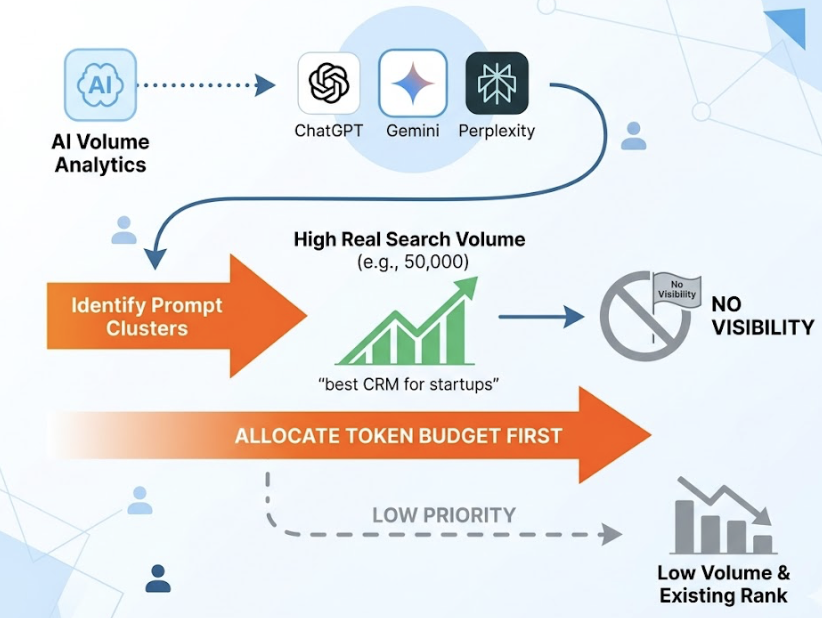
3. Drafting prompt matrices to test brand mentions. To get a real picture of AI visibility, brands must move beyond branded queries. Claude can generate comprehensive prompt matrices covering the full buyer intent spectrum — problem discovery, solution comparison, vendor evaluation — creating 500 to 1,000 variations of natural-language questions for systematic visibility audits.
4. Competitor narrative analysis. Feed Claude a set of AI-generated answers for competitors and it will synthesize their perceived market position. It identifies the “labels” that AI platforms have attached to rivals, such as “best for fast implementation” or “highest reliability,” and determines if a competitor has effectively claimed a specific recommendation category. That tells you where there’s unoccupied narrative territory.
5. Flagging inconsistencies in product descriptions. For technical or regulated industries, AI accuracy is non-negotiable. Claude can audit AI outputs for hallucinations or factual errors about your product’s specs, pricing, or compliance status. It can flag where an AI is surfacing outdated data — say, marking a product “discontinued” because of an old blog post — and identify the specific pages that need updating to correct the model’s retrieval.
For teams that want this analysis running continuously across multiple platforms, manually pasting data into Claude becomes the bottleneck fast. That’s the gap a platform like Topify is built to fill.
The Claude 4.7 + Topify Workflow for AI Visibility Optimization
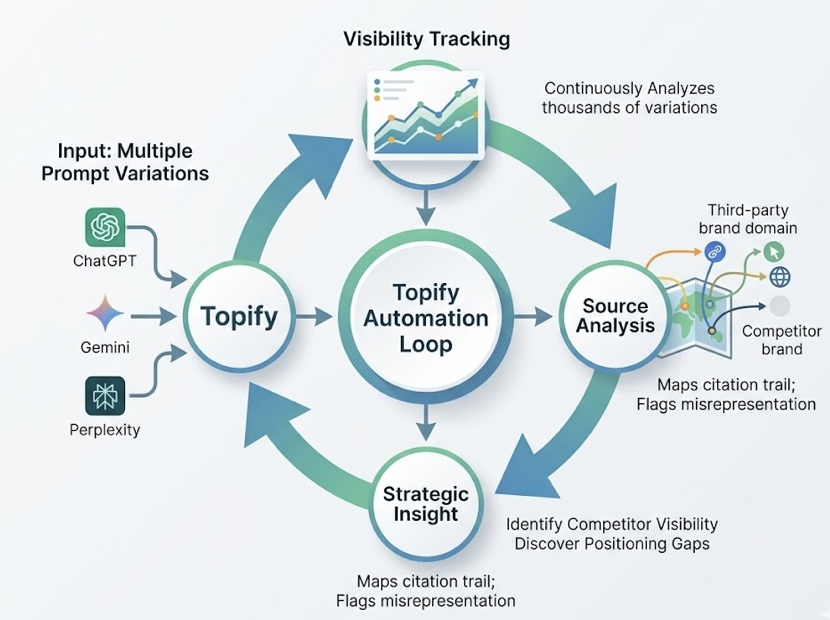
The most effective brand monitoring setups in 2026 use Claude 4.7 as the interpretive layer and Topify as the underlying data engine. Here’s how the cycle runs.
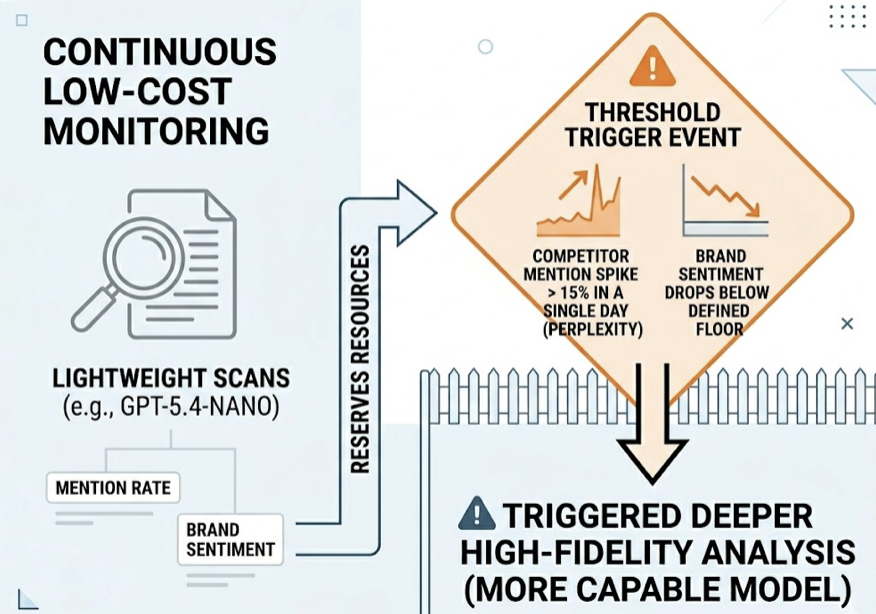
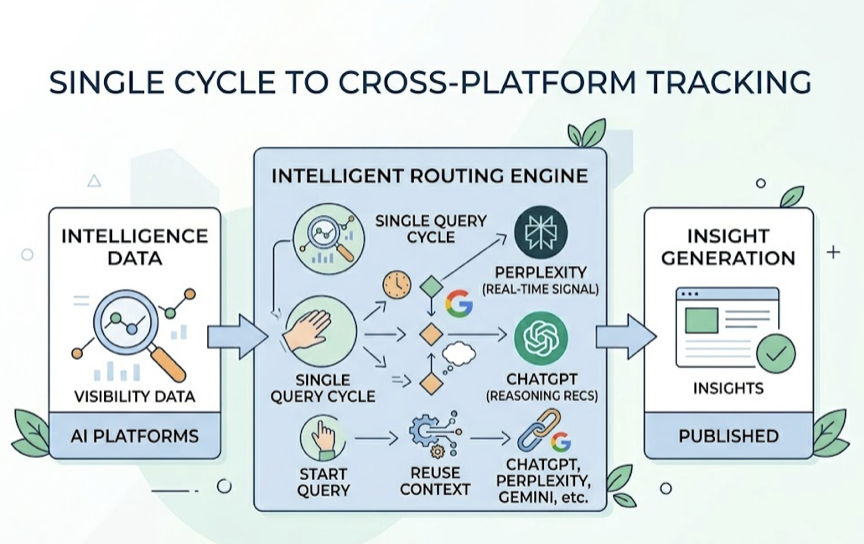
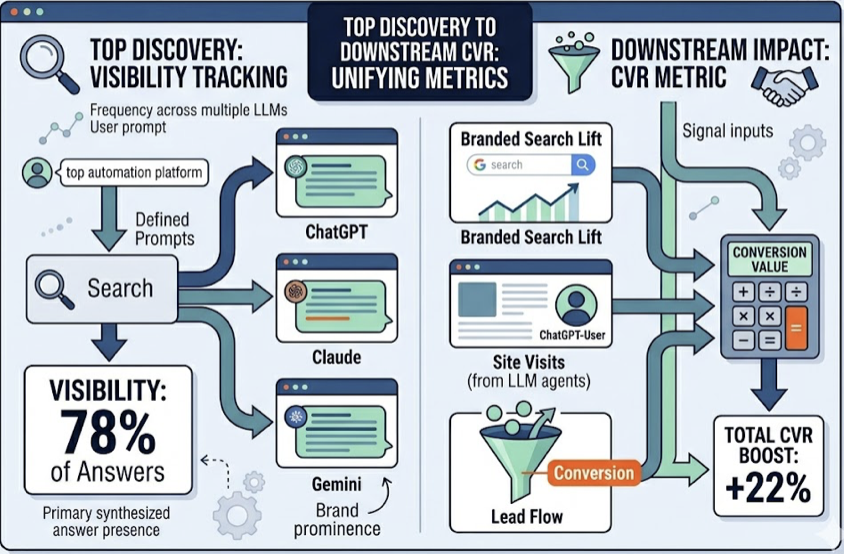
Step 1: Surface structured AI visibility data via Topify. Topify queries ChatGPT, Gemini, Perplexity, and Google AI Overviews in the background and delivers a 7-metric dashboard: visibility score, sentiment polarity, recommendation position, prompt volume, distinct mentions, intent alignment, and Conversion Visibility Rate (CVR). This is the objective baseline that Claude can’t generate on its own.
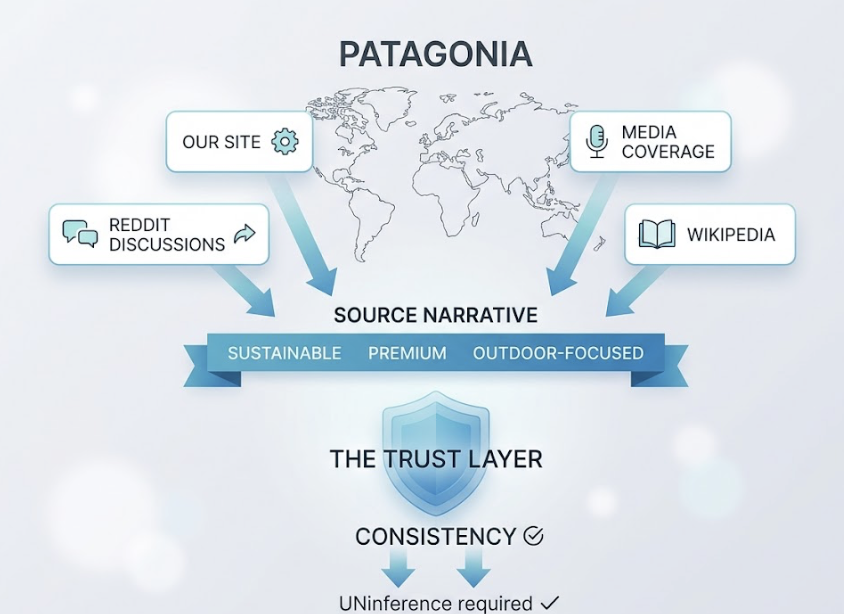
Step 2: Feed structured data into Claude 4.7 for interpretation. Once the data is collected, export it to Claude. With its large context window, Claude can process reports containing hundreds of AI responses alongside their corresponding metrics. Claude then performs divergence analysis — identifying where different platforms disagree. It might notice that ChatGPT provides a highly positive recommendation while Gemini ignores the brand entirely, then hypothesize why, perhaps because Gemini relies on Google Maps signals that the brand has neglected while ChatGPT is pulling from a strong Wikipedia presence.
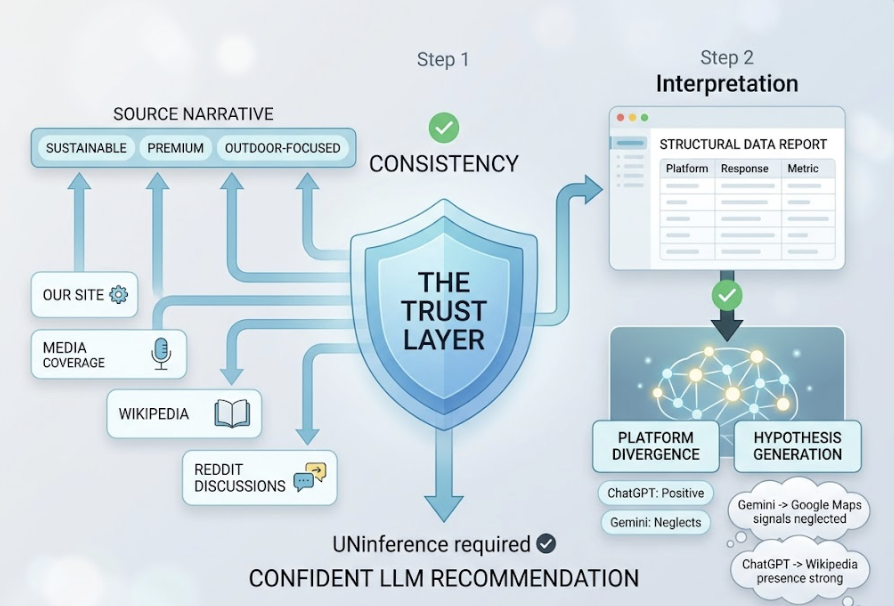
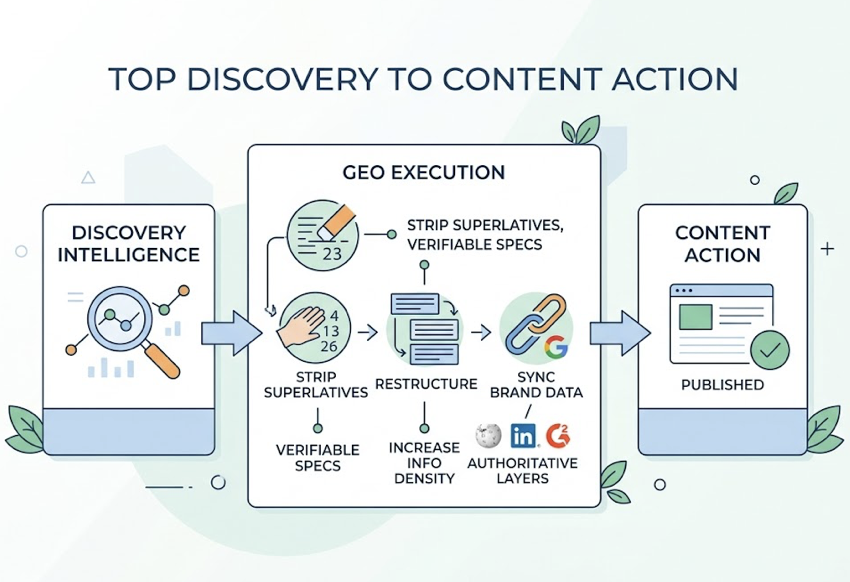
Step 3: Generate prioritized GEO recommendations. Using insights from Step 2, Claude produces a ranked list of Generative Engine Optimization actions with specific content directives. Because the model now follows instructions more literally, the outputs are actionable rather than vague. For example: “To improve citation frequency on Perplexity, add a data-dense table to your main product page — statistics improve AI citation probability by 37%.” It can also draft the updated content, optimized for machine-readability and citation extractability.
Step 4: Execute and measure change. Topify’s one-click agent pushes optimized content updates directly to CMS platforms like Shopify or WordPress. After updates go live, the team monitors the impact on their AI Visibility Score over subsequent weeks. That closes the loop between insight and action.
Sample Prompt Templates for Claude 4.7 Brand Analysis
For sentiment analysis, this structure works well:
You are a brand intelligence analyst. Below are [N] AI-generated responses
about [Brand Name] from different platforms.
Analyze the following:
1. The dominant framing used to describe the brand (category leader /
budget alternative / legacy tool / etc.)
2. The specific value-adjectives used across responses
3. Any divergence between platforms in how the brand is characterized
4. A sentiment score from 0-100, where 100 = unambiguous recommendation
Responses: [paste Topify export]
For framing gap analysis:
Below is our official positioning statement and a set of AI-generated
brand mentions. Identify:
1. Which positioning claims appear in AI outputs
2. Which positioning claims are absent or contradicted
3. The top 3 content gaps most likely causing the divergence
Positioning: [paste internal doc]
AI outputs: [paste data]
What Topify Surfaces That Claude 4.7 Can’t Do Alone
Claude is a superior reasoning engine. It’s not a monitoring infrastructure.
Topify covers ChatGPT, Gemini, Perplexity, Google AI Overviews, and platforms like DeepSeek simultaneously. With DeepSeek V4’s release in April 2026 — featuring 1.6 trillion parameters and a distinct retrieval architecture that favors neutral citations over recommendations — the divergence between platforms has widened. DeepSeek shows a 95.6% neutral mention rate, a fundamentally different strategic target than GPT-5. Tracking that divergence manually isn’t realistic.
The 7-metric dashboard breaks down AI presence into components that can be reported to stakeholders without ambiguity:
| Metric | Business Relevance |
|---|---|
| Visibility Score (AVS) | Mental share in the model |
| Sentiment Score | Distinguishes mention vs. recommendation |
| Position Ranking | Order of retrieval in synthesis |
| Volume | Reach across prompt variations |
| Mentions | Raw frequency per 1,000 relevant queries |
| Intent Alignment | Presence in high-commercial-value queries |
| CVR | Probability of driving brand interaction |
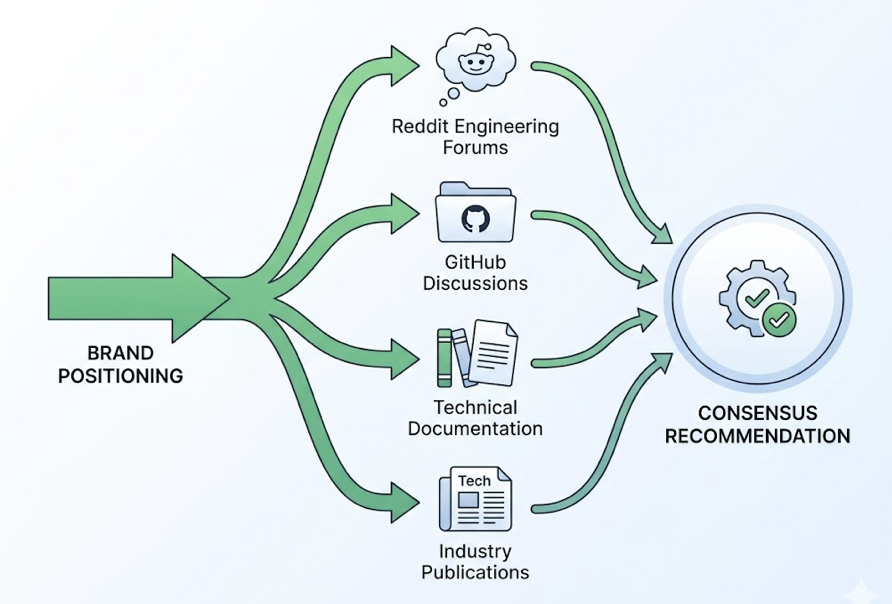
Topify’s source analysis adds another layer that Claude alone can’t provide. It reverse-engineers which specific domains and URLs AI models cite when building their answers. If a competitor is being recommended because of a single highly-cited Reddit thread or an industry review, Topify identifies that source. This “Citation Source Rate” is the GEO equivalent of a backlink count — it tells you exactly where you need to build presence to influence AI recommendations, not just that you’re losing ground.
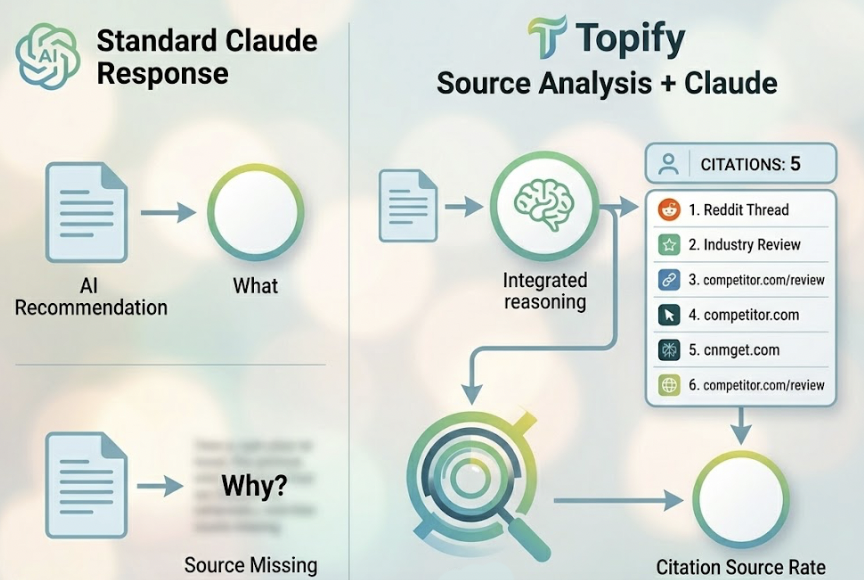
Real Use Cases: Who Benefits Most from This Combination
SaaS brands tracking product positioning. A B2B SaaS company might use Topify to discover it’s completely absent from AI answers about “security integrations” despite having a superior feature set. Feeding that data into Claude 4.7 can reveal that technical documentation is buried behind a PDF wall that AI crawlers can’t parse. Claude then drafts new FAQ-schema pages designed for AI extraction.
Marketing agencies managing multiple clients. With traditional organic CTR declining as users resolve questions inside AI summaries, agencies need to prove value through “Share of Model” metrics. Topify automates tracking across 10+ clients; Claude 4.7 synthesizes the insights into monthly AI Visibility Audits showing competitive standing across ChatGPT, Gemini, and Perplexity. That’s a service offering that didn’t exist two years ago.
PR teams monitoring narrative shifts. After a product launch or a crisis, AI models can have high “persistence” for negative narratives found in their training data. PR teams use Topify to flag when a resolved lawsuit or a discontinued product is still being mentioned. Claude then analyzes those outputs and suggests the specific rehabilitation content needed to displace the negative signal with more recent, evidence-backed information.
In-house competitive intelligence teams. The focus here is the “Divergence Map” — where competitors are winning citations that a brand isn’t. Topify’s source analysis identifies which review platforms or industry forums carry the most influence in a given category. Claude then analyzes the content of those citations to understand which labels (e.g., “fastest customer support”) are driving competitor recommendations.
Conclusion
Claude 4.7 gives you analytical depth at the prompt level. Topify gives you the structured, continuous data layer underneath.
Brand monitoring in 2026 is no longer passive listening. It’s an active discipline: monitor which AI platforms mention your brand, analyze why the framing is what it is, generate specific optimization actions, execute, and measure the change.
Claude 4.7’s improved instruction-following and vision capabilities make it a genuinely useful reasoning engine for brand intelligence. But its structural limitations — no real-time crawling, no persistent tracking, no cross-platform benchmarking — mean it needs a data foundation to work from.
Together, the two tools cover the full cycle. The brands that build this workflow now, while most competitors are still running traditional SEO playbooks, are the ones that will hold “Category Authority” in the AI-mediated search environment. That’s not a future state. It’s already the channel with the highest conversion premium available.
FAQ
Q1: Can Claude 4.7 monitor brand mentions automatically?
No. Claude 4.7 processes the data you provide — it doesn’t crawl or monitor AI platforms in real time. To automate that collection, you need a specialized tracking tool like Topify, which gathers the data automatically and formats it for downstream analysis.
Q2: How often should I run brand monitoring prompts in Claude 4.7?
Core brand visibility should be monitored at least weekly. AI models update their indices frequently, and weekly checks let you detect “model drift” — sudden changes in how an AI describes your brand — before they affect customer acquisition.
Q3: What’s the difference between brand monitoring and GEO?
Brand monitoring is the diagnostic layer: it identifies your current visibility, sentiment, and content gaps across AI platforms. Generative Engine Optimization (GEO) is the action layer — the specific content and technical changes you make to improve the metrics monitoring surfaces.
Q4: Does Topify integrate with Claude 4.7?
Topify’s data exports are formatted to be analyzed by frontier models like Claude 4.7, enabling a direct workflow from automated tracking to deep qualitative synthesis. The combination is designed to work as a single loop rather than two separate tools.
Q5: Is Claude 4.7 good enough for brand monitoring without additional tools?
For deep-dive analysis on specific AI responses, yes — Claude 4.7 is strong. For comprehensive brand monitoring, no. It can’t provide cross-platform benchmarking, historical trend data, or real-time visibility scores across the thousands of prompts that define a brand’s presence in the AI ecosystem.