On March 31, 2026, Anthropic shipped Claude Code v2.1.88 with a 59.8MB JavaScript source map accidentally bundled into the npm package. That single file exposed roughly 512,000 lines of TypeScript across nearly 1,900 files, including the core query engine, tool-call logic, multi-agent orchestration patterns, and 44 unreleased feature flags.
Anthropic pulled it fast. The community mirrored it faster.
Within days, developers had reverse-engineered the architecture and started building. What’s emerged since isn’t just a collection of hacks. It’s a map of where agentic infrastructure is actually heading.
Here are the five forks worth paying attention to.
Before You Dig In: Why These Forks Reveal More Than the Official Docs
The leaked code made one thing clear: Claude Code was never just a coding assistant. At its core, the QueryEngine.tsmodule binds LLM reasoning to local execution environments (terminal, file system, Git) through a modular tool system. Each tool has a strict input schema, a permission model, and isolated execution logic.
That architecture turns out to be extremely forkable.
BashTool runs arbitrary shell commands. AgentTool spawns recursive sub-agents. MCPTool calls external MCP servers, including GitHub APIs and web search. The moment developers saw this, they stopped thinking “coding assistant” and started thinking “execution kernel.”
The forks below are the result.
Fork #1: Everything Claude Code (ECC) — 28 Agents Where There Was One
Everything Claude Code (ECC), maintained by Affaan Mustafa, has crossed 100,000 GitHub stars as of March 2026. The number makes sense once you see what it actually does.
ECC doesn’t copy Claude Code. It rebuilds it as a specialist agent cluster. The original single assistant gets replaced by 28 purpose-built sub-agents, each with fine-tuned prompts and restricted tool permissions. A planner agent builds execution trees before any code is written. A tdd-guide agent enforces test-first workflows and won’t let the model write implementation code until a failing test exists. A security-reviewer agent runs OWASP audits and auto-scans for hardcoded secrets like sk- and ghp_ prefixes.
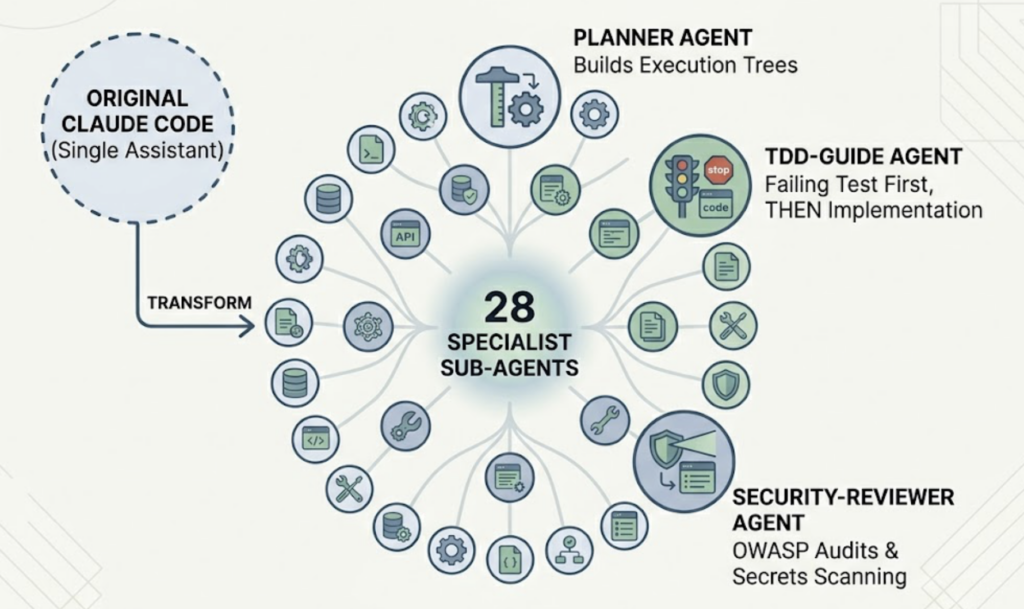
The result is a measurably higher task completion rate on complex projects. Each agent does less, which means it does its specific thing much better.
What really separates ECC is its persistent learning system. The original Claude Code forgets everything between sessions. ECC uses pre- and post-tool hooks to extract knowledge after every tool call, converting patterns into “instincts” scored by confidence (0.3-0.9). When three or more instincts accumulate in the same category, the system prompts you to run /evolve, locking them into permanent “skill” modules.
Over time, the agent learns your team’s specific architecture decisions and style conventions.
ECC also uses a cross-platform adapter pattern (DRY Adapter) so the same configuration works across Claude Code, Cursor, OpenCode, and Codex. One ruleset, consistent behavior everywhere.
Fork #2: Claude SEO — From Code Generation to AEO and GEO
This one caught the marketing world off guard.
Claude SEO, built by AgriciDaniel, takes Claude Code’s agentic engine and routes it entirely toward content and search optimization. The project includes 19 sub-skills and 12 dedicated agents. The pitch: replace a $5,000-10,000/month agency retainer with an automated audit and optimization system.
The /seo audit command runs multi-agent parallel audits across an entire website. The /seo programmatic module auto-generates scaled page templates while actively preventing index bloat. The /seo google module pulls live Google Search Console metrics, PageSpeed data, and GA4 traffic in real time.
The more interesting angle is the /seo geo module.
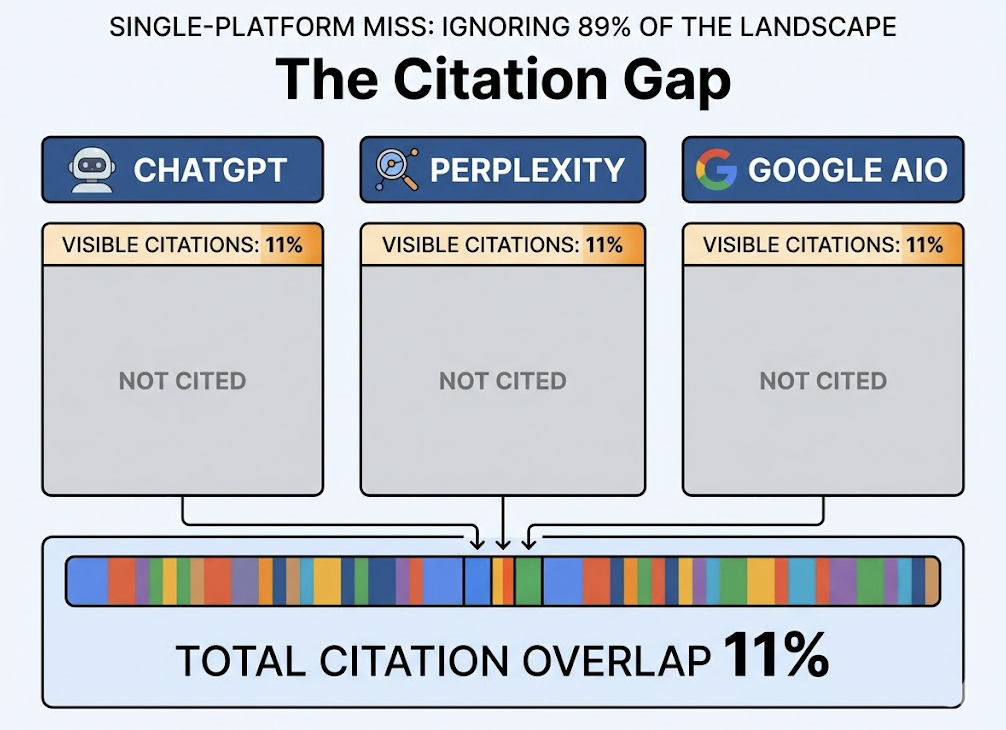
AI-driven search now accounts for 45% of first-touch queries, and traditional organic click-through rates drop roughly 80% when AI summaries appear above organic results. Claude SEO’s GEO module generates content specifically optimized for ChatGPT, Perplexity, and Gemini visibility, applying an E-E-A-T quality gate based on Google’s September 2025 Quality Rater Guidelines.
But generating content and tracking whether it actually surfaces in AI answers are two different problems.
That’s where Topify comes in. Claude SEO integrates with Topify’s monitoring API to give marketers a real feedback loop: the agent generates GEO-optimized content, and Topify tracks whether that content is translating into measurable Share of Voice and Citation Rate inside AI answers across ChatGPT, Perplexity, Gemini, and others. Without that tracking layer, you’re essentially publishing into a black box.
If you’re thinking about AI search visibility as a growth channel, get started with Topify to close the loop between content execution and AI performance data.
Fork #3: Ruflo — Enterprise Swarm Orchestration With Byzantine Fault Tolerance
Ruflo, originally called Claude Flow and developed by rUv, sits at the opposite end of the complexity spectrum from ECC. It’s not a configuration system. It’s a full orchestration layer for agent swarms.
Ruflo supports over 60 specialized agent types, organized into dynamic swarms with a Queen agent that holds 3x voting weight over worker agents for faster decisions. That’s not a metaphor: Ruflo implements actual distributed consensus algorithms for multi-agent decision-making.
Critical architectural decisions use Byzantine Fault Tolerance, requiring a 2/3 majority threshold to proceed. Regular tasks like code review use simple majority voting. Security patches run through BFT regardless. The framework was designed for use cases like full microservice migration or large-scale security hardening, where an incorrect sub-agent decision cascades badly.
The performance story is also unusual. Ruflo ships a Rust-compiled WASM kernel called Agent Booster that handles simple code transformations locally, without making any LLM API calls. That’s 352 times faster than routing the same task through the API, which matters when you’re running dozens of agents in parallel.
The system’s internal vector database (RuVector, built on PostgreSQL) enables sub-millisecond pattern retrieval across the swarm. Every agent has shared context access, which eliminates the “thought drift” problem where different agents in a cluster develop inconsistent views of the same codebase.
Ruflo is overkill for individual developers. For engineering teams running multi-day autonomous tasks, it’s currently the most architecturally serious option in the ecosystem.
Fork #4: Claudeck and CodePilot — Giving the Terminal a Dashboard
Not every interesting fork adds capability. Sometimes the useful move is removing friction.
Claudeck, built by Hamed Farag, is a browser-based local web app. Its headline feature is a 2×2 parallel mode: four independent Claude sessions running simultaneously on the same screen. For long-running tasks that involve separate concerns (frontend, backend, tests, docs), this alone changes the workflow significantly.
The more practical feature is real-time cost tracking. Claudeck connects to a local SQLite billing analyzer that displays token consumption and dollar spend live, per session. Most developers don’t have a clear intuition for what their agentic workflows cost until the monthly API bill arrives. Claudeck surfaces that data at the moment it matters.
There’s also a Telegram integration for remote approval: when Claude is about to execute a bash command, a notification fires to your phone. You approve or reject it with a tap. That makes unattended long-session agents actually viable, since you’re not locked to the keyboard.
CodePilot (also known as Opcode) takes a heavier approach with an Electron and Next.js desktop app, IDE-style file tree sidebar, and full session rewind capability. Its standout feature is mid-conversation model switching: you can start a session on Claude Sonnet 4.5, realize you need deeper reasoning, and switch to Opus 4.6 or even AWS Bedrock without losing context.
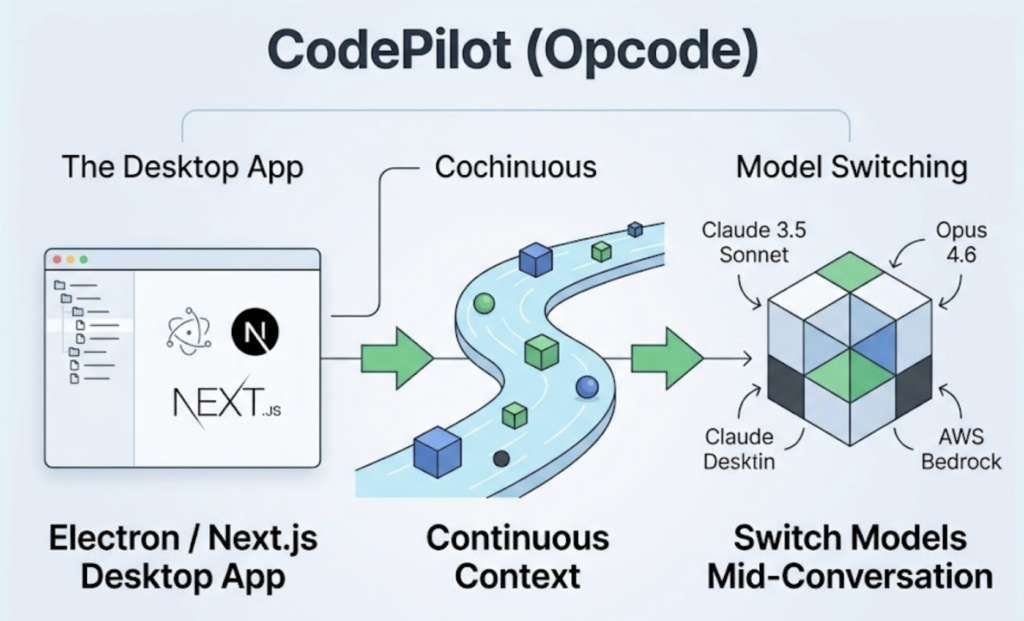
Both projects reflect the same underlying insight: the CLI works great if you’re already comfortable in a terminal. A large portion of the people who could benefit from agentic AI tooling are not.
Fork #5: OpenClaw — From Fork to Deployed Product
OpenClaw is the most commercially minded project in this list. It’s not a configuration system or a UI wrapper. It’s a deployment framework for running Claude Code agents in production, on your own infrastructure, with security isolation baked in.
The security architecture is the notable part. Every agent operation runs inside a Sysbox container with restricted network permissions and a read-only filesystem. The host machine can’t be touched by an agent executing a script, even if that script tries. API keys never live on the VPS: OpenClaw routes requests through a Cloudflare Worker that injects credentials at the edge. If the server gets compromised, the attacker gets an authorization token, not the actual API key.
OpenClaw also bridges the agent into Telegram, Discord, and Feishu, which means the agent isn’t a terminal-only tool. It’s accessible from wherever your team communicates.
The cost angle is worth noting. Claude’s current API pricing runs from $1/M tokens for Haiku 4.5 on simple tasks up to $5/$25 (input/output) for Opus 4.6 on complex reasoning. OpenClaw’s intelligent routing algorithm automatically selects the right model based on task complexity. The project claims 75% API cost reduction in production deployments by routing low-complexity tasks to Haiku instead of defaulting everything to the most expensive model.
That cost-aware architecture is arguably what makes this viable as an actual product rather than a proof of concept.
Conclusion
The March 2026 source map leak accelerated something that was already in motion. Claude Code’s architecture, built around modular tools, recursive agent spawning, and MCP extension, turns out to be an extremely flexible foundation for use cases Anthropic didn’t design it for.
ECC proves that configuration alone can drive enterprise-grade coding performance. Ruflo shows that agent swarms can operate with distributed consensus at scale. Claude SEO demonstrates that the same architecture powering code generation can power content strategy and AI search optimization. Claudeck and CodePilot show that the terminal is optional. OpenClaw shows that it’s possible to ship a product on top of all of this.
The through-line across all five: agentic AI is moving from assistant to infrastructure. The forks that understand that are the ones worth watching.
FAQ
Q: Are Claude Code forks legal to use?
A: It depends. Since many forks were built from the leaked source map, Anthropic has been issuing DMCA takedown notices for repositories that reproduce the original code directly. Projects built around configuration frameworks and prompts rather than the source code itself occupy a different legal position. For commercial use, consult a lawyer familiar with software copyright before deploying anything in this space.
Q: What’s the difference between AEO and GEO?
A: Answer Engine Optimization (AEO) focuses on getting your content cited by AI systems that answer questions directly, like ChatGPT or Perplexity. Generative Engine Optimization (GEO) is the broader practice of optimizing brand presence across all AI-generated responses. In practice, they overlap heavily, and tools like Topify track both through visibility, sentiment, and citation metrics.
Q: Do I need to be a developer to use any of these forks?
A: Not for all of them. Claudeck and CodePilot were specifically built to remove the terminal dependency. Both offer web or desktop interfaces where you manage agents through a GUI. Claude SEO also has a command-based interface that marketing teams can use without writing any code.
Q: How does Claude Code handle context across long tasks?
A: The original Claude Code doesn’t. That’s one of the core problems ECC and Ruflo were built to solve. ECC’s persistent learning system stores session knowledge as scored instincts between sessions. Ruflo’s RuVector database gives an entire agent swarm shared, sub-millisecond access to project context so different agents don’t drift out of sync.