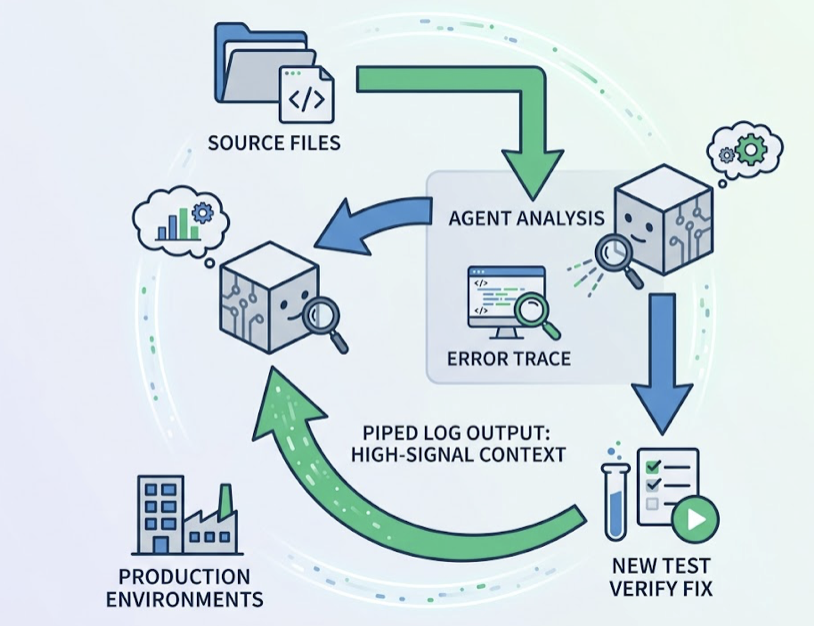
At 2:00 AM, a CI pipeline fails. No engineer opens their laptop. An AI agent reads the error logs, traces the race condition to a recent commit, implements a fix, runs the test suite, and leaves a detailed report for the morning standup.
That’s not a demo. That’s Claude Code running a routine on Anthropic-managed infrastructure.
If you’ve been thinking of it as a smarter autocomplete, you’ve been looking at the wrong thing entirely.
Autocomplete Was Never the Bottleneck
Most AI coding tools were built to solve the wrong problem.
Typing speed was never what slowed engineers down. The real constraint is context switching: the constant toggling between the terminal, the browser, the test runner, Slack, and back again. Research tracking developer behavior found that the average knowledge worker switches applications roughly 1,200 times per day. After each switch, it takes an average of 9.5 minutes to regain productive flow. For complex coding tasks, that recovery window stretches to 23 minutes.
That adds up to 40% of productive time lost to reorientation, not to thinking about code.
Tools like the original GitHub Copilot made typing faster. They didn’t fix the orchestration problem.
What Makes Claude Code Different from a Smarter Copilot
Claude Code runs in the terminal. That’s not a UX choice; it’s an architectural one.
By operating in the shell rather than as an IDE plugin, the agent gains unrestricted access to the full development environment: the file system, the build tools, the package manager, git state, and anything that can be piped through a command. IDE extensions are bounded by the APIs of their host environment. Claude Code isn’t.
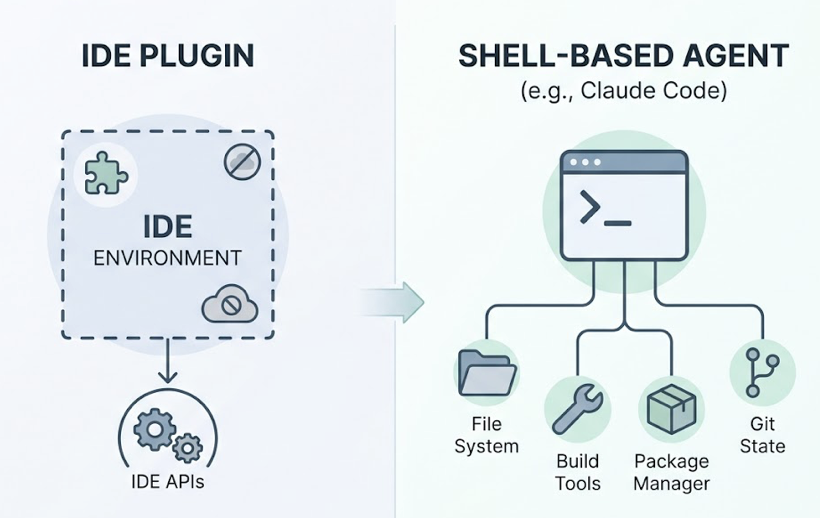
The context window difference matters more than most teams realize. Claude Code operates with a 1-million-token context window, meaning it can hold an entire enterprise codebase in active memory. GitHub Copilot works within roughly 8k to 32k tokens. Cursor extends that to around 200k to 400k.
| Claude Code | GitHub Copilot | Cursor | |
|---|---|---|---|
| Interface | Terminal/CLI | IDE Extension | Forked VS Code |
| Context Window | 1,000,000 tokens | 8k–32k tokens | ~200k–400k tokens |
| Execution Authority | Runs terminal commands | Suggests text only | Background agents |
| Multi-File Scope | Repository-wide | Limited | “Composer” multi-file |
| Pricing | Consumption-based | $10–39/mo flat | Subscription/Credits |
That gap shows up concretely in complex refactoring. An assistant suggests how to update a function. Claude Code plans a 50-file refactor, executes the changes across the entire directory, and runs the test suite to verify no regressions were introduced.
3 Workflow Shifts Claude Code Actually Creates
These aren’t incremental. They change how engineering teams are structured.
Shift 1: From author to orchestrator. Engineers aren’t writing every line anymore. They’re providing architectural intent and reviewing what the agent produces. Rakuten used Claude Code to implement a complex technical method across a 12.5 million-line codebase in seven hours, with 99.9% accuracy. The engineer’s value in that workflow was system design and verification, not typing.
Shift 2: From weeks of onboarding to hours. A new developer joining a complex codebase traditionally needs weeks of documentation reading and pair programming. Claude Code can explore an unfamiliar repository, trace dependencies, and explain architectural decisions on demand. A frontend engineer can contribute to the backend layer because the agent bridges the knowledge gap in real time.
Shift 3: From manual routines to autonomous background operations. The “Routines” feature lets teams schedule tasks to run without a human present: dependency audits, PR reviews, overnight CI analysis. The 2:00 AM scenario at the top of this article isn’t hypothetical. It’s a routine.
That third shift is what separates Claude Code from every previous generation of dev tooling.
Where Claude Code Still Needs a Human in the Loop
Autonomy has limits. The current design makes this explicit.
The first limit is business logic. An agent can find a technical fix for a bug. It may not understand why a particular “inefficient” pattern was chosen for compliance or legacy compatibility. That context lives in people’s heads, not in the codebase.
The second limit is reliability under complexity. Research indicates that without structured human oversight, AI agents can fail multi-step tasks up to 70% of the time when encountering unforeseen edge cases. Claude Code’s Plan Mode addresses this by presenting the agent’s intended action sequence before execution, so engineers can catch misaligned decisions before they touch production systems.
| Limitation | Specific Challenge |
|---|---|
| Regulatory sensitivity | Deleting patient records requires documented human authorization |
| Financial risk | AI may misjudge nuance in high-stakes transactions |
| Security boundaries | Production modifications demand human gates |
| Subjective judgment | Satire moderation, recruiting, organizational politics |
The third limit is security. Because Claude Code can access integrated files and MCP-connected data sources during a session, the volume of sensitive information in the context window during a large repository review is substantial. Teams handling proprietary code on consumer plans should note that default data retention settings may extend up to five years without an explicit opt-out. Enterprise accounts include no-training guarantees and institution-level controls.
The Agentic Shift Changes Who AI Recommends
Here’s a dynamic most technical teams haven’t priced in yet.
As AI agents like Claude Code become the primary interface through which engineers discover tools, evaluate documentation, and make technical decisions, the question of “which brand does the agent recommend” becomes a business-critical variable.
That’s not intuitive. You’d assume that engineers do their own research. In practice, they increasingly ask Claude, Perplexity, or ChatGPT directly: “What’s the best library for X?” or “Which observability platform should we use?” The agent synthesizes an answer based on signals it’s already been trained on or retrieved from external sources.
The data is stark. Organic traffic to websites declined by 10% to 40% in 2025, as users get direct answers from AI systems. About 60% of all queries are now “clickless searches.” And 82% to 85% of AI citations come from third-party domains, not brand websites: Reddit, forums, media coverage, community documentation.
For technical brands, this means the usual SEO playbook is only part of the picture. The more decisive factor is how the brand appears inside AI responses across platforms.
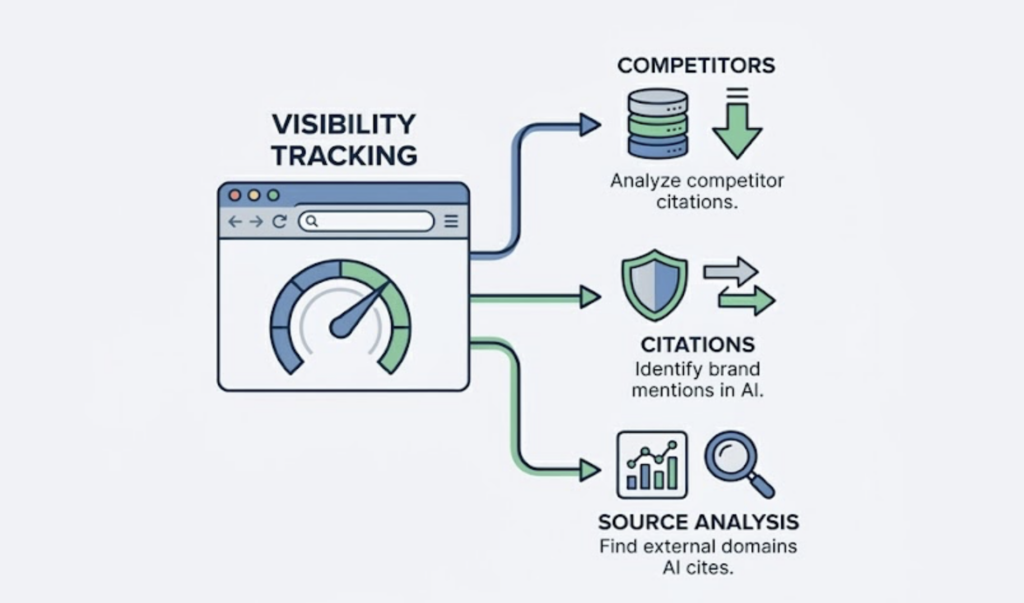
Topify tracks exactly this. Its AI visibility platform monitors brand performance across ChatGPT, Gemini, Perplexity, and other major AI systems using seven metrics: visibility, sentiment, position, volume, mentions, intent, and CVR. Its Source Analysis feature traces which external domains AI platforms are citing, revealing where the content gaps are and which third-party channels are actually shaping the AI’s recommendations.
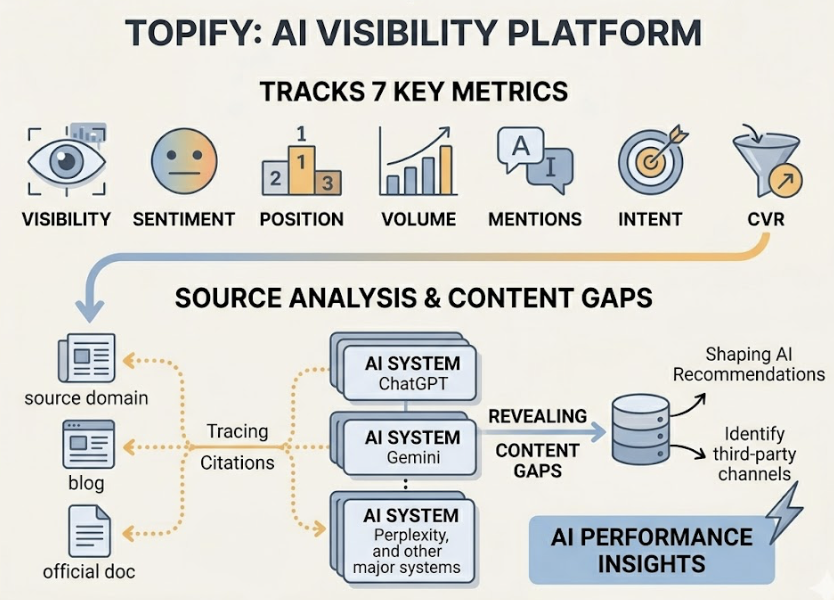
Between 82% and 85% of AI citations come from third-party sources. If your documentation doesn’t show up there, your brand doesn’t show up either.
How to Decide If Claude Code Fits Your Team Right Now
Not every team should adopt it at the same pace.
Solo founders and small startups see the most immediate ROI. Agentic coding effectively compresses the headcount required to ship a product. Tasks that previously required a full-time engineer’s week can be delegated to an agent session with human review at the end.
Mid-size engineering teams benefit most in the “orchestration” model: senior engineers manage multiple agent sessions in parallel, handling technical debt or feature branches simultaneously instead of sequentially. Speed improvements on routine tasks run up to 90%.
Large enterprises with legacy codebases (think COBOL or Fortran modernization) gain access to an agent that can navigate unfamiliar language environments and trace decades-old architectural decisions with context that a human onboarding would take months to build.
The pricing consideration is real. Claude Code’s consumption-based model can run $100 to $200 per month for power users, compared to the flat-rate $10 to $20 of legacy assistants. The question is whether the 55% speed increase in task resolution justifies the variable spend for your team’s workload mix.
A practical starting path:
- Create a
CLAUDE.mdin your project root capturing tech stack details, conventions, and architectural constraints. - Identify two or three low-risk, repetitive tasks (linting, dependency audits) and automate them with Routines.
- Move senior engineers into Plan Mode for complex features, using the agent for multi-file implementation and reserving human attention for verification.
Conclusion
The shift Claude Code represents isn’t about writing code faster. It’s about changing what engineers spend their time doing.
By 2028, an estimated 38% of organizations will have AI agents operating as full members of blended human-AI teams. The engineers who adapt early won’t just be faster; they’ll be working at a fundamentally different level of abstraction.
The same dynamic applies to technical brands. In an environment where AI agents make tool recommendations, the brands with clear documentation, strong third-party presence, and measurable AI visibility will be the ones that get discovered. The brands optimizing only for Google rankings will increasingly find themselves invisible to the agents their target users are actually consulting.
Agentic coding is live. The optimization window is now.
FAQ
Is Claude Code better than GitHub Copilot?
They serve different purposes. GitHub Copilot is an IDE extension for autocomplete and single-file assistance. Claude Code is a terminal-native agent for complex, multi-step tasks across an entire codebase, with a 1M-token context window and the ability to run shell commands and tests autonomously.
Can Claude Code work with any codebase?
Yes. It operates via the terminal and can read and edit any file in your project directory regardless of language. It also supports legacy languages like COBOL and Fortran, which makes it useful for modernizing older systems.
What’s the difference between Claude Code and Cursor?
Cursor is an AI-native IDE (a fork of VS Code) with a graphical interface. Claude Code is a command-line tool that follows the Unix philosophy, making it composable with other terminal tools and deployable in CI/CD pipelines.
Does Claude Code require cloud access to run?
Officially, yes. It uses the Claude 3.5 Sonnet model via an Anthropic subscription and internet connection. Community-built workarounds exist to point it at local model endpoints via Ollama or LM Studio, though local models typically trail on reasoning performance.
How does agentic coding affect security and code review?
It accelerates code production velocity significantly, which strains traditional review processes. Teams are increasingly adopting AI-assisted first-pass reviews while reserving human reviewers for high-level security architecture decisions. For teams handling proprietary code, enterprise-tier accounts with no-training guarantees are the safer operational choice.