Your Google Analytics dashboard shows stable organic traffic. Your keyword rankings haven’t moved. Everything looks fine.
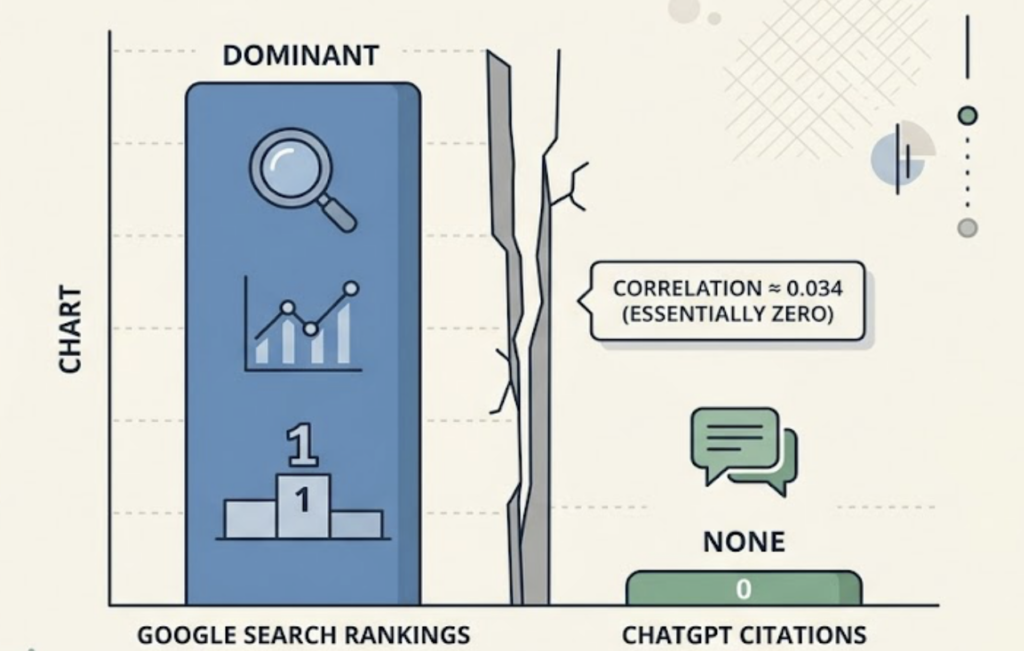
Meanwhile, ChatGPT just recommended your competitor to 900 million weekly users. And your brand wasn’t mentioned once.
That’s the gap. And most brands still can’t measure it.
Traditional SEO tools were built for a world where users click links. That world is shrinking fast. As of early 2026, 83% of searches that trigger an AI Overview end without a click, and Google’s dedicated “AI Mode” pushes that number to 93%. The discovery path has moved upstream, into the AI’s answer, before any link is ever touched.
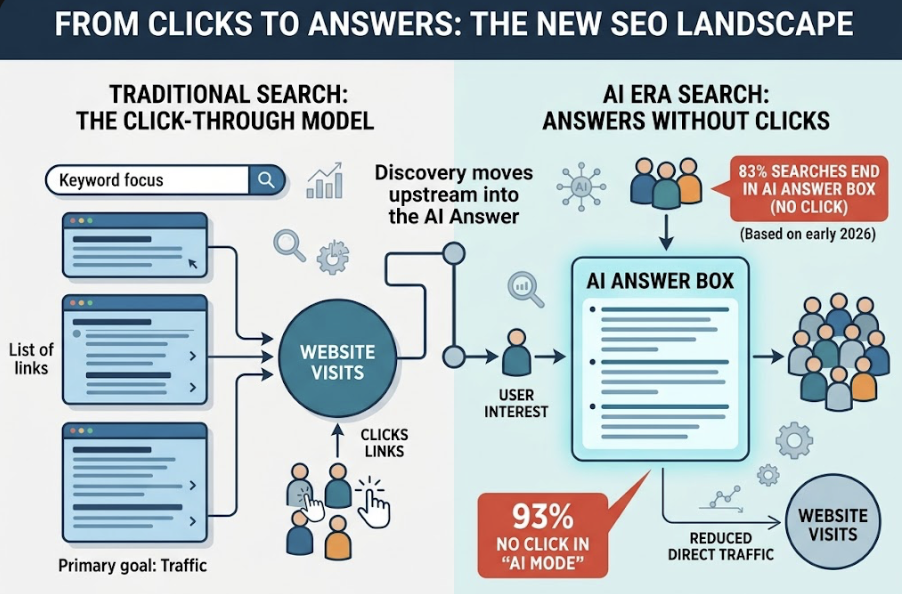
The five metrics below are what actually tell you whether AI is recommending your brand, ignoring it, or quietly pointing people elsewhere.
Your SEO Dashboard Doesn’t See What AI Sees
Traditional search attribution works on a simple model: user searches, user clicks, you measure. AI search breaks that model at every step.
When a user asks Perplexity “what’s the best project management tool for remote teams” and Perplexity answers directly, no click happens. No impression is recorded in your Search Console. No session appears in Analytics. Your brand either existed in that answer or it didn’t, and you have no way of knowing which.
This isn’t a minor reporting gap. Between January 2025 and February 2026, ChatGPT’s weekly active user base grew from 400 million to over 900 million. Google AI Overviews now reach 1.5 billion monthly users. AI-powered search tools have captured 12-15% of global search market share, up from 5-6% at the start of 2025.
The brands that measure what’s actually happening in that space will have a structural advantage over those still optimizing for clicks that increasingly aren’t coming.
Metric #1: AI Visibility Score — How Often AI Mentions You
Think of the AI Visibility Score (AVS) as your brand’s “mental share” inside the models. It answers one question: across the prompts your buyers are actually typing, how often does your brand appear?
The standard methodology runs 20 or more structured prompts across major platforms like ChatGPT, Perplexity, Gemini, and Claude, then scores mentions by prominence:
| Prominence Level | Score | Example |
|---|---|---|
| Primary recommendation, specific reasoning | 5 pts | “For enterprise teams, [Brand] is the top choice because…” |
| Included in a comparison list | 3 pts | “[Brand], [Competitor A], and [Competitor B] are the main options” |
| Passing mention without detail | 1 pt | “Some users also mention [Brand]” |
| Not mentioned | 0 pts | — |
Most brands start with an AVS between 0 and 8 out of 100. A score of 25-50 is considered “Category Presence” — AI knows you exist and mentions you in relevant contexts. Above 70 is “Category Authority” — AI actively recommends you as a leading option.
Topify‘s Visibility Tracking automates this across seven major AI platforms, running structured prompt sets and returning a normalized visibility score broken down by topic, platform, and competitor.
Metric #2: Sentiment Score — Being Mentioned and Being Recommended Are Two Different Things
A brand can appear in 80% of AI answers about its category and still be losing customers to competitors. The reason: AI might be mentioning you as the “budget option,” the “legacy choice,” or worse, surfacing old negative reviews as the first thing it cites.
Sentiment score measures the favorability of how AI talks about your brand, not just whether it talks about you.
By early 2026, 66% of consumers said they believed AI tools provide accurate results. That trust transfers directly to whatever characterization the AI has formed about your brand. If the AI’s training data is weighted toward a period when your product had known issues, or if a competitor has built a stronger third-party review presence, the AI’s default narrative about you may not reflect where you actually are.
A particularly costly version of this problem: brands marked as “discontinued” in AI answers because of deleted blog posts or rebranded domains. The AI inherited that signal from its training data and kept surfacing it.
Tracking sentiment requires analyzing not just whether your brand appears, but what value-adjectives surround it and how it’s framed relative to competitors. Topify’s Sentiment Analysis assigns a 0-100 score and flags shifts in narrative tone across platforms, so you know whether a recent content change or PR mention is actually moving the needle.
Metric #3: AI Position Ranking — First Mention Is Not the Same as Fifth Mention
Position-based thinking isn’t obsolete in AI search. It’s just moved inside the answer.
Research into user behavior shows that B2B buyers with high purchase intent clicked through to at least one cited source in 90% of encounters with AI-generated summaries. But which source they clicked depended heavily on where it appeared in the AI’s narrative — and whether the AI framed it as a recommendation or a footnote.
On traditional Google, the CTR for position #1 has dropped by 58-61% when an AI Overview is present. The traffic didn’t disappear; it got absorbed by whichever brand the AI chose to present first.
That’s the new position #1: being the brand the AI names first, with reasoning, when someone asks a relevant question.
Topify’s Position Tracking monitors where your brand falls in AI-generated recommendation sequences, across ChatGPT, Perplexity, Gemini, and others. It tracks not just whether you’re in the answer, but whether you’re the lead recommendation or the runner-up — and how that position shifts week over week against specific competitors.
Metric #4: Source Citation Rate — If AI Doesn’t Read You, It Can’t Recommend You
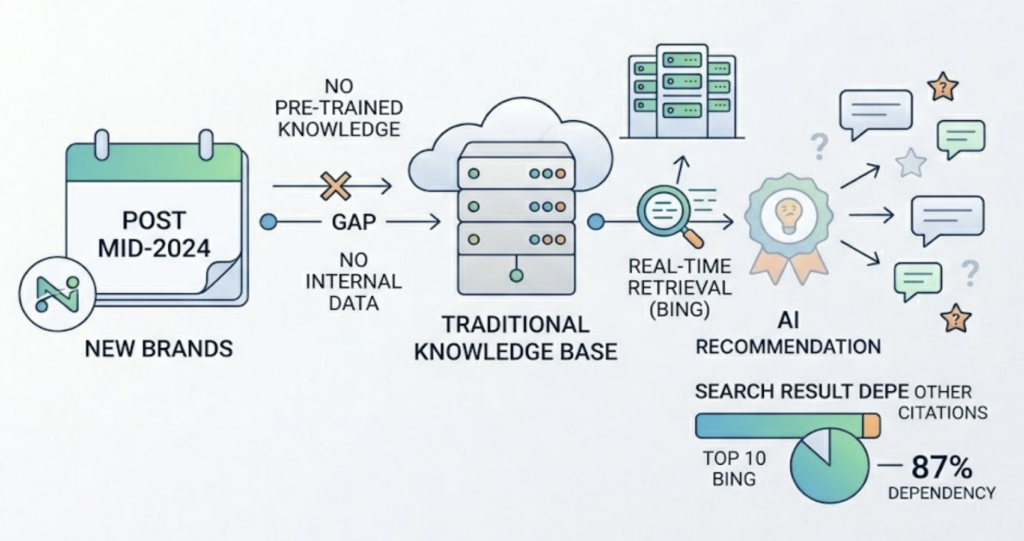
AI recommendations don’t come from nowhere. They’re grounded in content the models have crawled, indexed, and retrieved. Your Source Citation Rate measures how much of that grounding actually includes your domain.
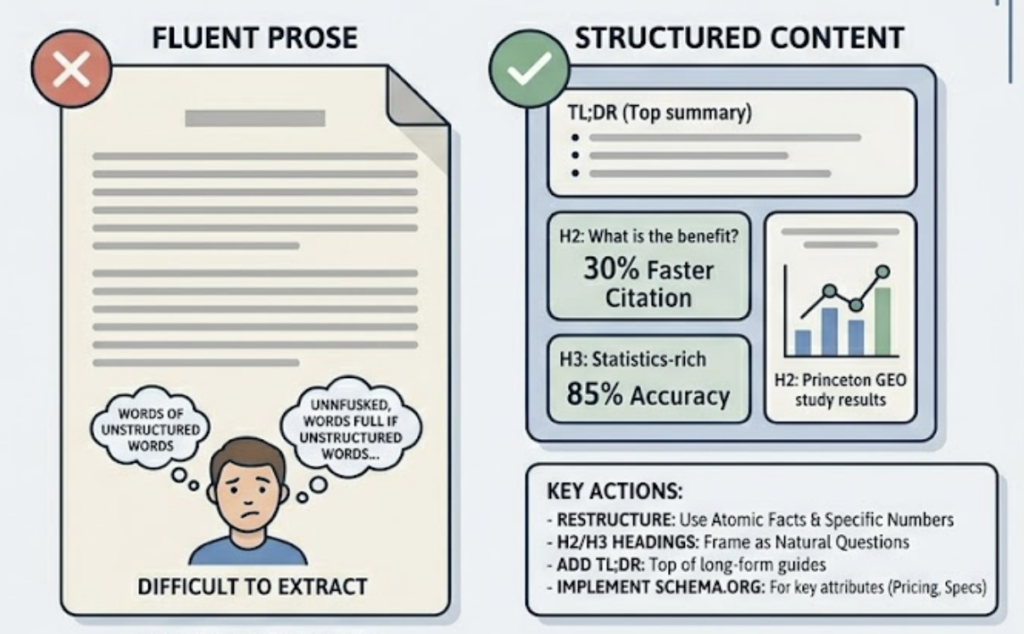
A large-scale analysis of 17.2 million AI citations in late 2025 found that first-party brand websites generate 4.31 times more citation occurrences per URL than aggregators or listing sites — but only if they meet the content quality thresholds the models use for selection. Content that includes hard data is 30-40% more likely to be cited. Freshness matters too: AI-cited content tends to be 25.7% newer than what traditional SERP rankings surface.
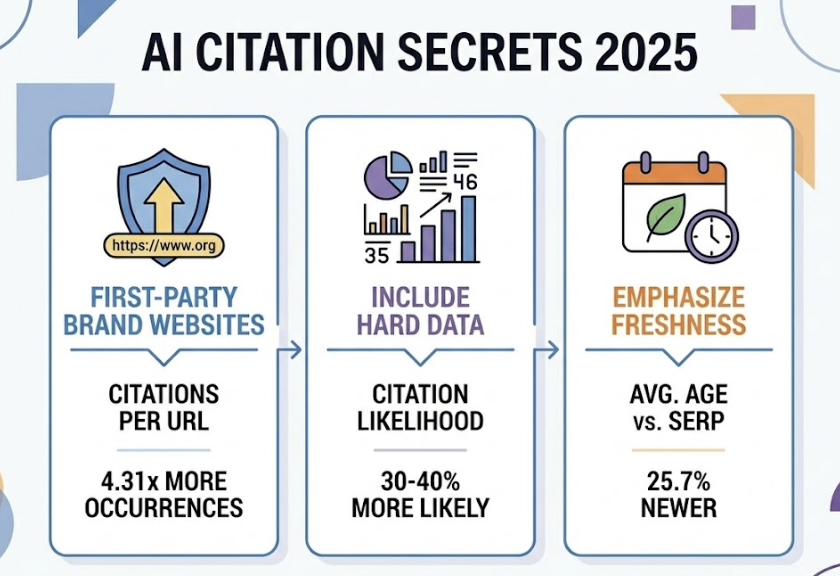
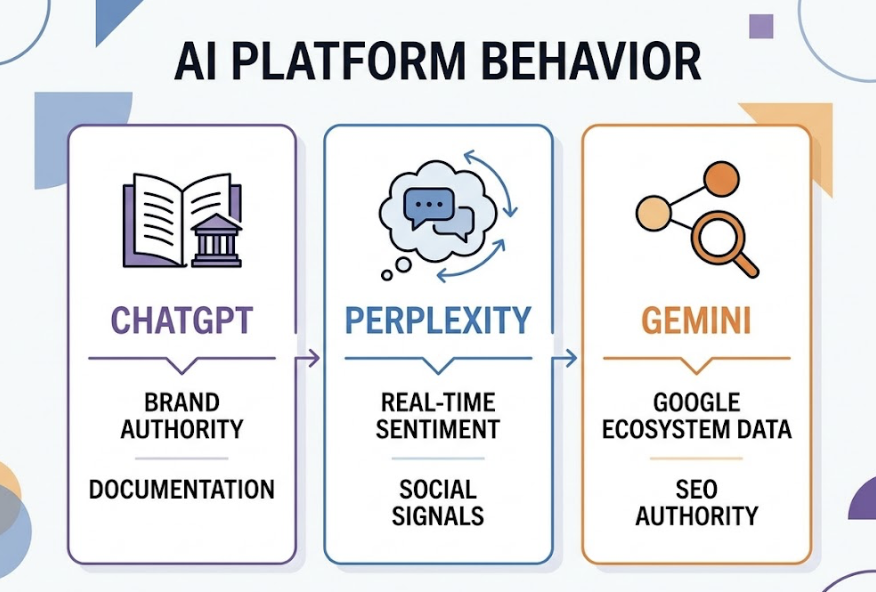
Platform architecture shapes this differently across engines. ChatGPT Search relies heavily on Bing’s organic index — 87% of its citations match Bing’s top 10. Perplexity prioritizes real-time retrieval and recency, often surfacing niche sources if they’re precise. Knowing which platform favors what kind of content changes how you structure your citation strategy.
Topify’s Source Analysis reverses-engineers the domains and URLs that AI platforms are actively citing within your category, showing you where the citation share is flowing and which content gaps are costing you presence.
Metric #5: Conversion Visibility Rate — The Metric That Connects AI Mentions to Revenue
AI search currently drives between 0.15% and 1% of total web traffic. That sounds like a rounding error. It isn’t.
AI search visitors arrive at your site having already read a synthesized comparison. The AI handled the research phase. The user clicking through has already narrowed their shortlist. That changes the conversion math entirely.
Across B2B SaaS, AI search visitors convert at 12-15%, compared to 2.5-4% for traditional organic search. In retail, AI-sourced traffic converts 42% better than non-AI traffic (including paid search), with users spending 48% longer on site and browsing 13% more pages per visit.
The Conversion Visibility Rate tracks the quality and commercial relevance of the contexts in which your brand appears — not just mention volume, but whether those mentions are occurring inside high-intent prompts where a buyer is actually making a decision.
There’s also an AI readability problem underneath this metric. The average U.S. retail homepage is only 75% machine-readable by AI systems. Product pages drop to 66%. Roughly a third of most brands’ digital presence is effectively invisible to the agents that are guiding purchasing decisions.
Topify’s CVR metric maps which prompt categories are driving actual downstream engagement and flags where your AI visibility is concentrated in low-intent contexts.
Reading All Five Together
No single metric tells the full story. In practice, each one exposes a different failure mode:
| Metric | What High Scores Miss | Risk If Ignored |
|---|---|---|
| AI Visibility Score | Can be high even with negative sentiment | Appears often, but as the “wrong” choice |
| Sentiment Score | Doesn’t show volume | Good reputation, but AI rarely mentions you |
| Position Ranking | Doesn’t show conversion quality | First mention in low-intent contexts |
| Source Citation Rate | Doesn’t show commercial framing | Cited as a source, not as a recommendation |
| Conversion Visibility Rate | Doesn’t show reach | Strong conversion rate on minimal volume |
The brands that win in AI search aren’t necessarily the ones with the highest visibility score. They’re the ones with a healthy score across all five.
Topify tracks all of these metrics in a single dashboard, running structured prompt sets across ChatGPT, Perplexity, Gemini, DeepSeek, and others, then returning a composite view with week-over-week shifts. The Basic plan starts at $99/month and covers 100 prompts and 9,000 AI answer analyses — enough to build a meaningful baseline for most brands within the first 30 days.
Conclusion
SEO dashboards measure what happens after discovery. These five metrics measure discovery itself.
Your AI Visibility Score tells you if you exist in the conversation. Your Sentiment Score tells you how AI talks about you. Your Position Ranking tells you whether you’re the recommendation or the footnote. Your Source Citation Rate tells you whether AI has the content infrastructure to cite you at all. And your CVR tells you whether those mentions are converting into anything.
Together, they replace the guesswork about whether AI is helping or ignoring your brand with something you can actually act on.
Start measuring. Topify covers all five metrics in one place.
FAQ
What’s a good AI Visibility Score for my brand?
Most brands start between 0 and 8 out of 100. Reaching 25-50 (Category Presence) within six weeks of active GEO effort is a realistic benchmark. Above 70 is considered Category Authority, where AI actively recommends you as a leading option in your space.
How is AI brand visibility different from traditional SEO metrics?
Traditional SEO measures what happens after a user clicks a link — rankings, impressions, traffic. AI visibility measures what happens before the click: whether your brand is present in the AI’s synthesized answer, how it’s characterized, and whether it’s the option the user walks away wanting to research further. Most brands have no data on that part of the funnel at all.
Can I track AI brand visibility across ChatGPT and Perplexity at the same time?
Yes, and you should — each platform has different citation logic. ChatGPT Search draws 87% of its citations from Bing’s top 10. Perplexity prioritizes freshness and real-time retrieval. A brand that’s well-cited in one may be underrepresented in the other. Cross-platform tracking surfaces those gaps.
How often should I check these five metrics?
Perplexity updates citation patterns within 2-3 weeks of content changes. ChatGPT can lag by months due to its reliance on crawl cache and training data. A weekly or biweekly check is reasonable for most brands, with daily monitoring reserved for periods of active content publishing or reputational events.
What’s the fastest way to improve my AI Visibility Score?
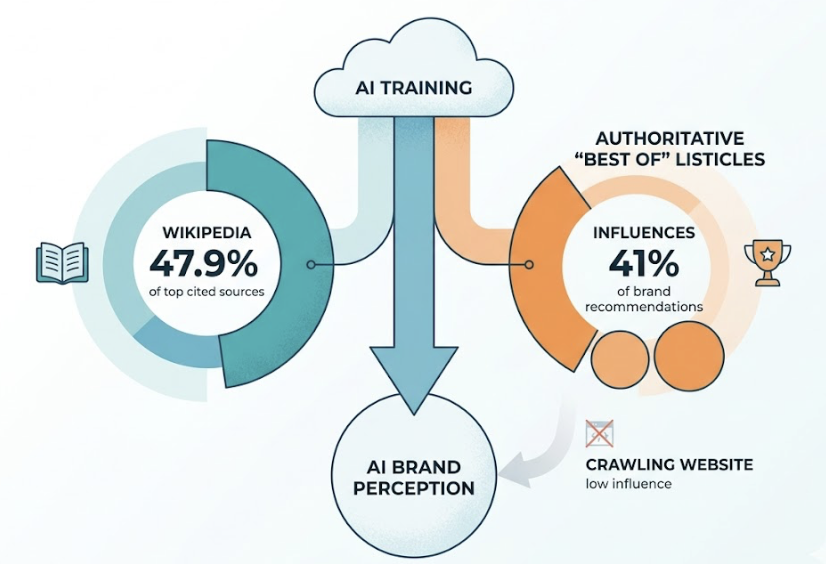
The single strongest correlation in citation research is web mentions: how often your brand is referenced on third-party, authoritative domains. Publishing data-dense content and building mentions on sites like Reddit, LinkedIn, and industry publications tends to move the AVS faster than on-site optimization alone.