Your keyword rankings are solid. Your domain authority took years to build. Then a potential customer opens ChatGPT, types “what’s the best [your category] tool for my team,” and gets a list of five recommendations. Your brand isn’t on it. And your current analytics have no idea that conversation even happened.
That’s the gap AEO tools are built to close.
AEO Isn’t SEO with a New Name
AEO stands for Answer Engine Optimization. It’s the practice of making sure your brand shows up, gets cited, and gets recommended when AI platforms like ChatGPT, Perplexity, and Gemini answer questions relevant to your category.
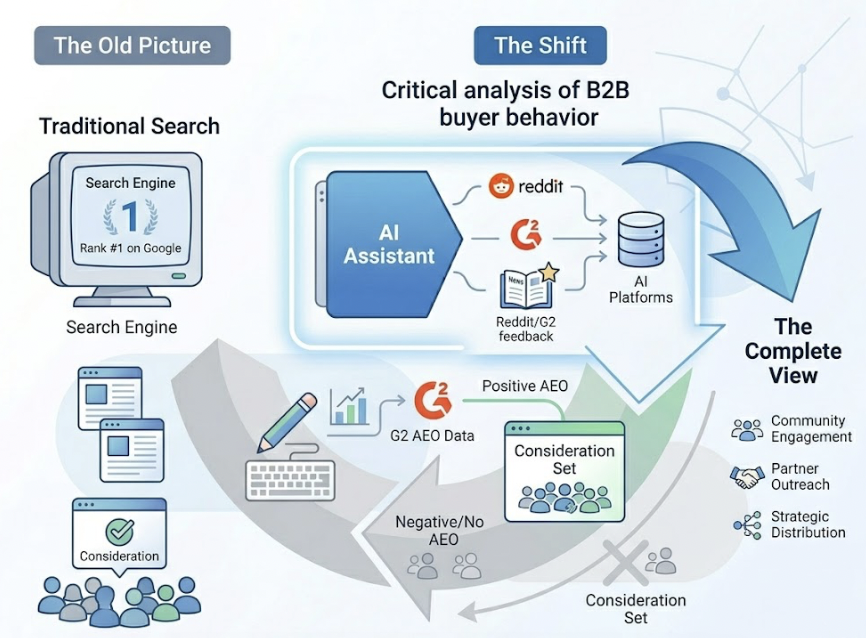
The distinction matters. SEO optimizes for a Google ranking. AEO optimizes for inclusion in an AI-generated answer. Those are two different outcomes, measured on two different platforms, driven by two different signals.
A brand can hold the #1 position on Google for a high-intent keyword and still be completely absent from the AI response for the exact same query. This isn’t a bug. It’s how generative engines work. Understanding AI search visibility as a separate discipline from traditional rankings is the starting point for everything that follows.
What an AEO Tool Actually Does
An AEO tool monitors what happens before a user ever reaches your website. Specifically, it tracks whether your brand appears in AI-generated responses, how you’re described when you do appear, and which sources the AI used to form that answer.
Most traditional analytics start at the click. AEO tools start earlier.
Think of it across three layers. First, Visibility: does your brand name show up when AI answers relevant questions? Second, Sentiment: when it does appear, is the framing positive, neutral, or quietly negative? Third, Source Attribution: is the AI pulling from your content, your competitors’ content, or third-party platforms like Reddit and G2?
AI agents and AEO work together in this framework. The agent retrieves sources, synthesizes them, and delivers a verdict. An AEO tool shows you whether your brand made that shortlist, and if not, why.
AEO Tool vs. SEO Tool: A Side-by-Side Look
| Dimension | SEO Tool | AEO Tool |
|---|---|---|
| What it tracks | Rankings, backlinks, traffic | AI mentions, citations, sentiment |
| Target platform | Google, Bing | ChatGPT, Perplexity, Gemini |
| Output | Keyword position | Brand visibility in AI answers |
| Optimization goal | Rank higher | Get cited more often |
| Core metric | Impressions, CTR | Mention rate, Citation rate |
The Numbers That Explain Why Marketers Are Paying Attention
This isn’t a future trend. It’s already showing up in traffic data.
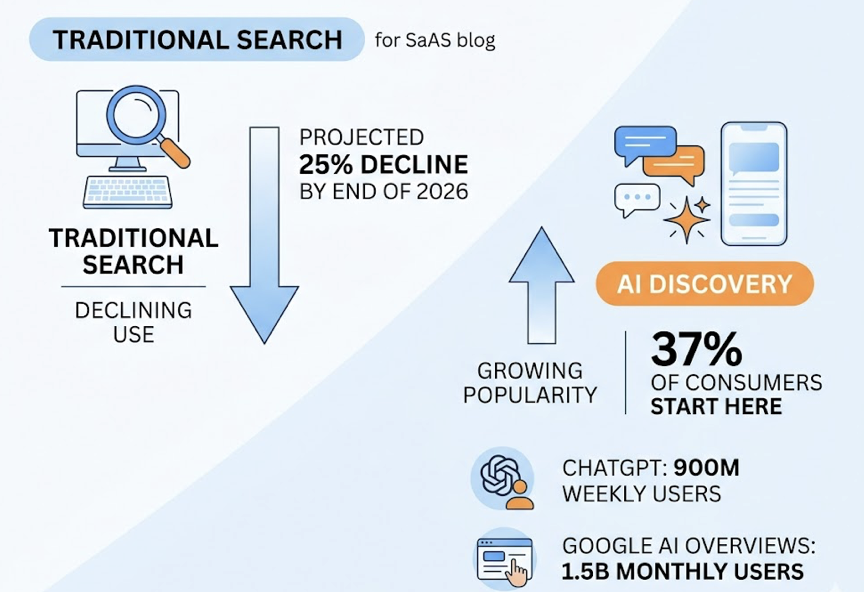
37% of consumers now start their product discovery journeys with AI tools rather than traditional search engines. ChatGPT has reached 900 million weekly active users. Google AI Overviews reaches 1.5 billion monthly users globally. Traditional search volume is projected to decline by approximately 25% by the end of 2026.
The conversion numbers make the case even more directly. Visitors referred from AI platforms convert at 4.4x to 5x the rate of standard organic search visitors. In B2B SaaS, AI-referred conversion rates have reached as high as 14.2%.
That last number deserves its own sentence.
The explanation is structural. By the time a user asks ChatGPT for a recommendation, the AI has already done the top-of-funnel and mid-funnel research for them. They arrive pre-qualified. The trade-off is that 93% of AI search sessions end without any click to an external website, meaning if you’re not named in the answer, you don’t exist for that user. Forrester data shows B2B marketing teams have already seen 20-30% declines in web traffic tied to AI-native discovery.
Understanding how AI search marketing works and how to measure it is quickly becoming a baseline expectation, not a niche skill.
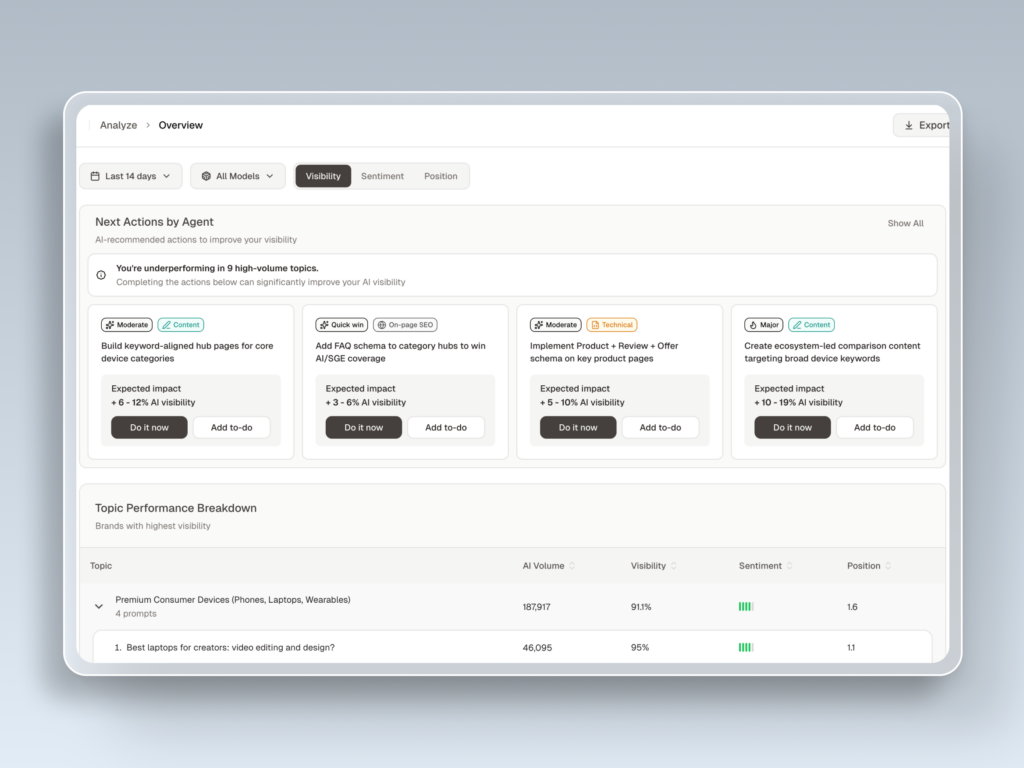
5 Things a Good AEO Tool Should Track
Not all AEO tools measure the same things. Before evaluating any platform, it helps to know which signals actually matter.
Mention Rate is the percentage of relevant queries where your brand name appears in the AI’s actual response text. This is the most direct measure of whether AI platforms are recommending you.
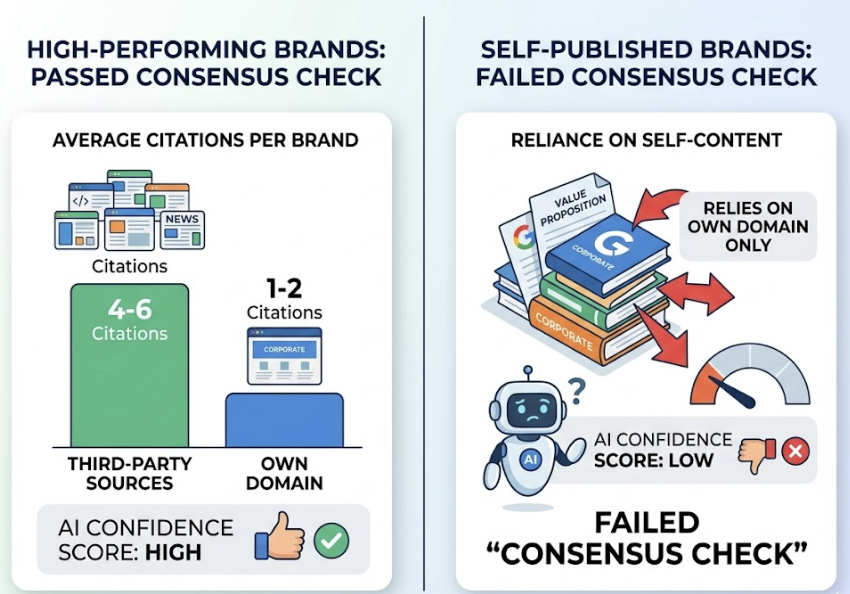
Citation Rate tracks how often your domain is referenced as a source in AI responses, even when the brand name isn’t mentioned in the answer itself. This distinction matters because a tool might cite your content 182 times in a month without ever saying your brand name. That pattern, sometimes called a “ghost citation,” means your data is trusted but your brand hasn’t earned a direct recommendation yet.
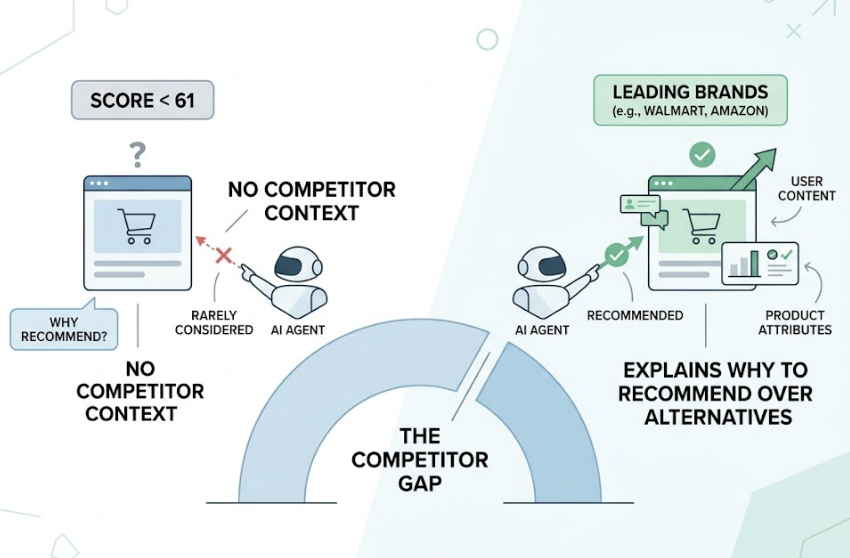
AI Share of Voice compares your mention rate against a defined set of competitors. In a typical AI response, three to six brands are named. You’re either in that group or you’re not. There’s no position eight here.
Sentiment Score measures how the AI frames your brand when it does mention you. A high score means the AI positions you as a recommended leader. A low one means you’re more likely described as a cautionary alternative. Keyword research built for GEO and AEO can surface the topic clusters where your framing needs work.
Prompt Coverage identifies which questions your brand shows up for, and equally, which high-volume AI prompts you’re absent from entirely. Research shows that 95% of the sub-queries AI models generate internally have zero recorded search volume in traditional tools like Ahrefs. AEO tools surface these uncontested opportunities before anyone else is optimizing for them.
What Makes It Harder: The AI Visibility Gap
Here’s something worth understanding before you start optimizing.
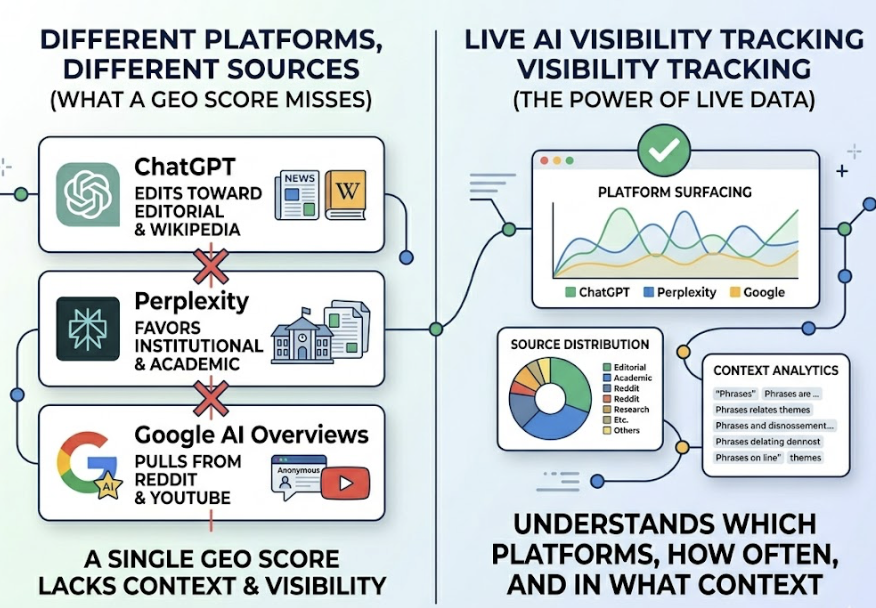
Different AI platforms don’t agree with each other. There’s less than an 11% overlap in the domains cited by ChatGPT versus Perplexity. Being well-cited on one platform doesn’t transfer to others automatically. Cross-platform tracking isn’t a premium feature. It’s the baseline.
AI platforms also favor freshness in a specific way. Content updated within the last 90 days is 2.3x more likely to be cited than older material. This isn’t about changing a publication date. It’s about content that reflects current positioning, current product features, and current context.
The implication is direct: AEO isn’t a one-time audit. It’s a continuous monitoring function.
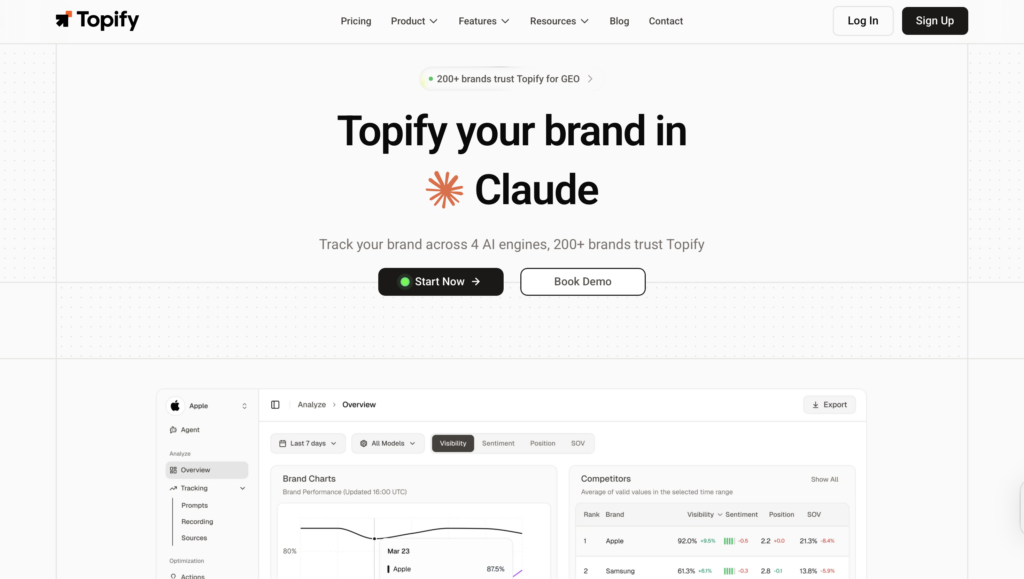
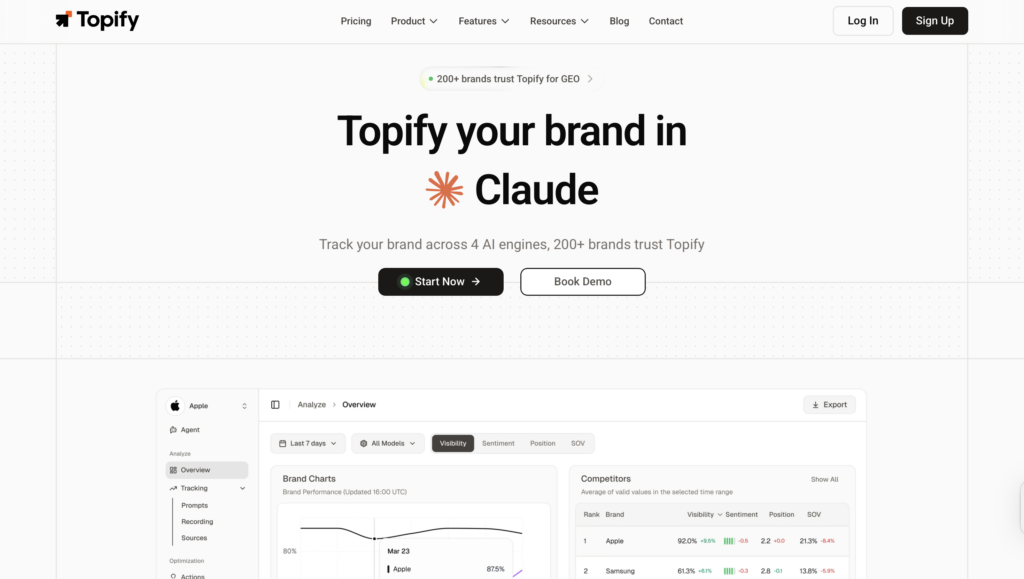
Where Topify Fits Into the AEO Picture
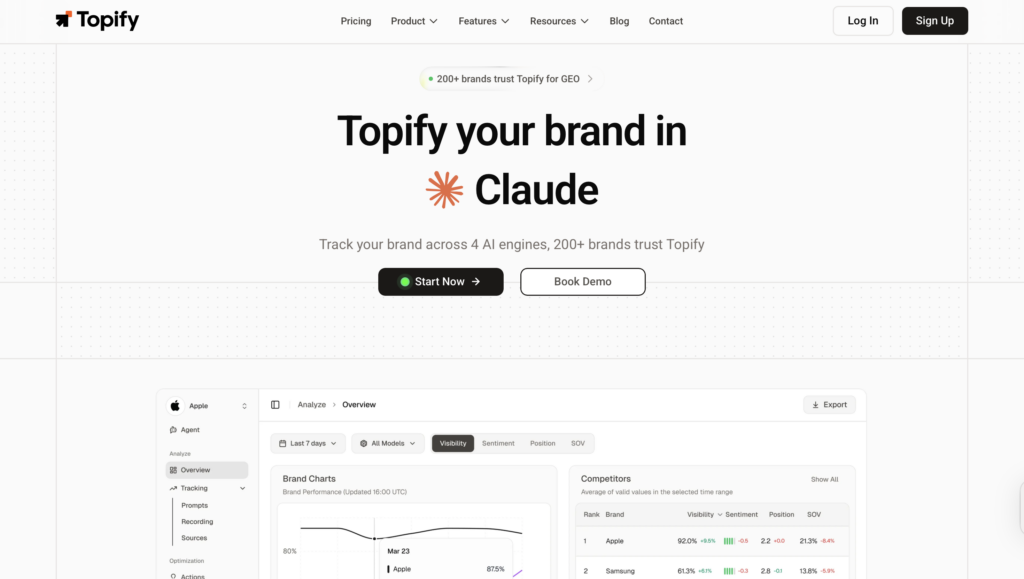
For marketing teams that need to track AEO systematically across multiple platforms, Topify treats AI search visibility as a structured, measurable channel rather than a one-off diagnostic.
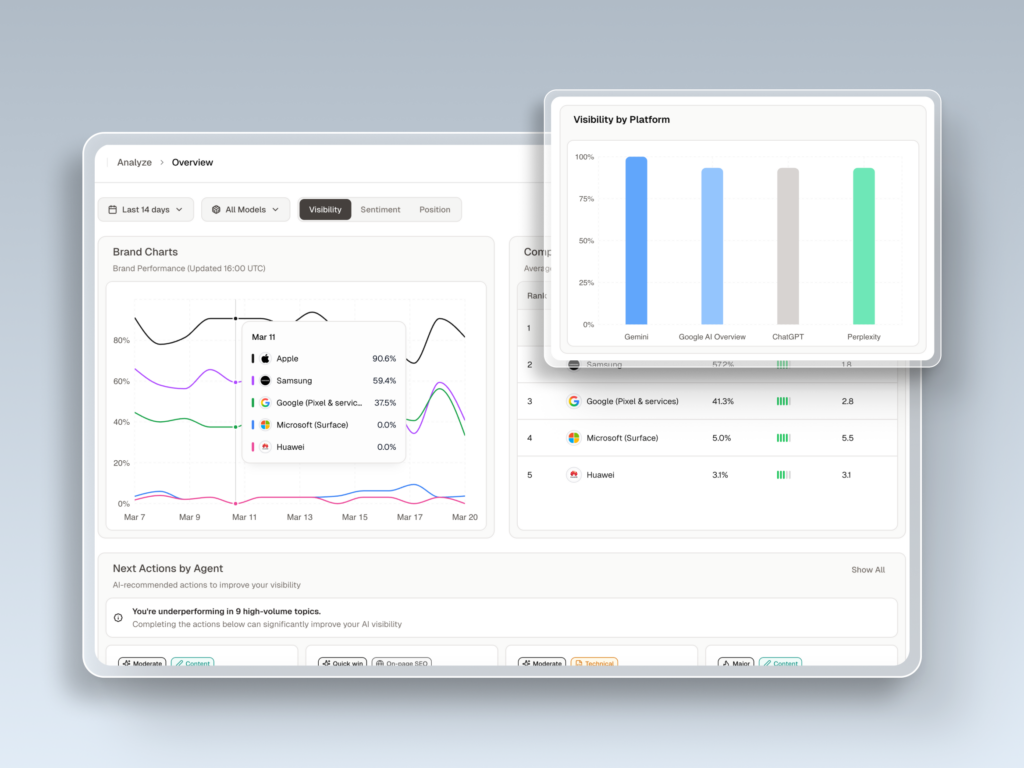
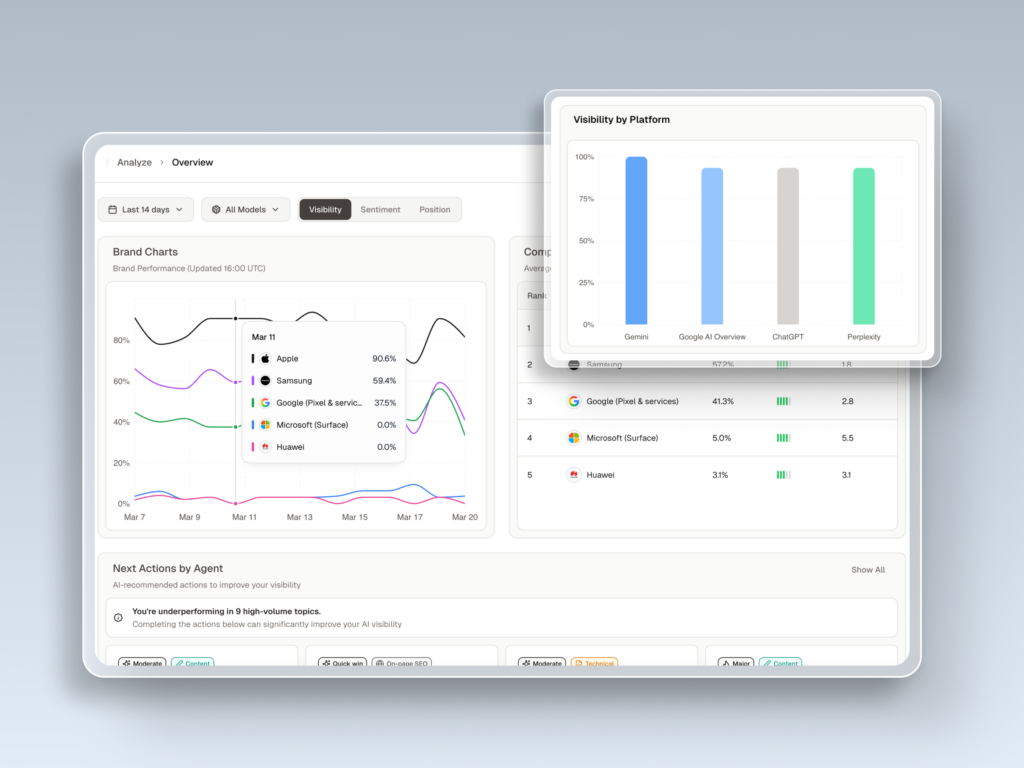
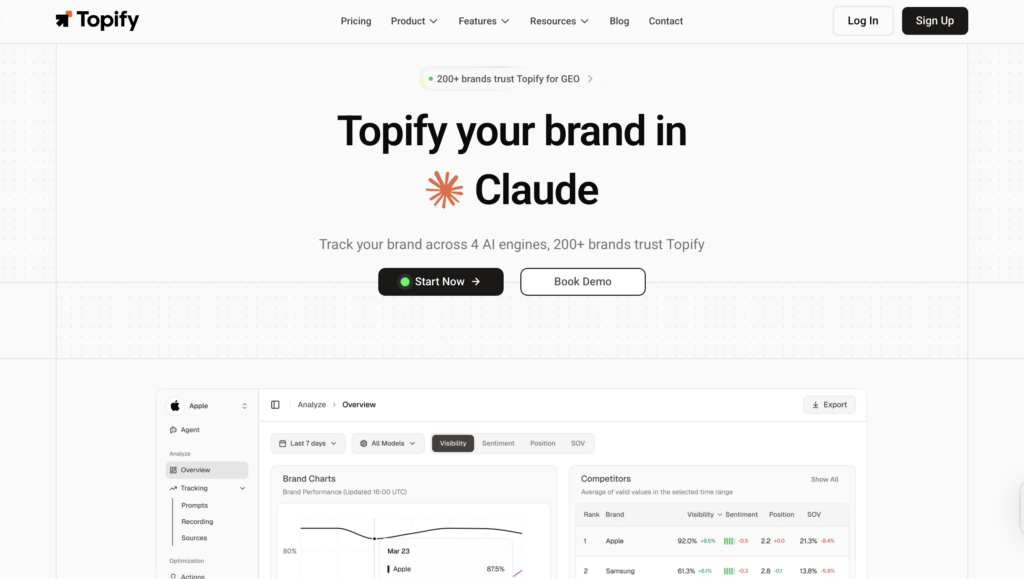
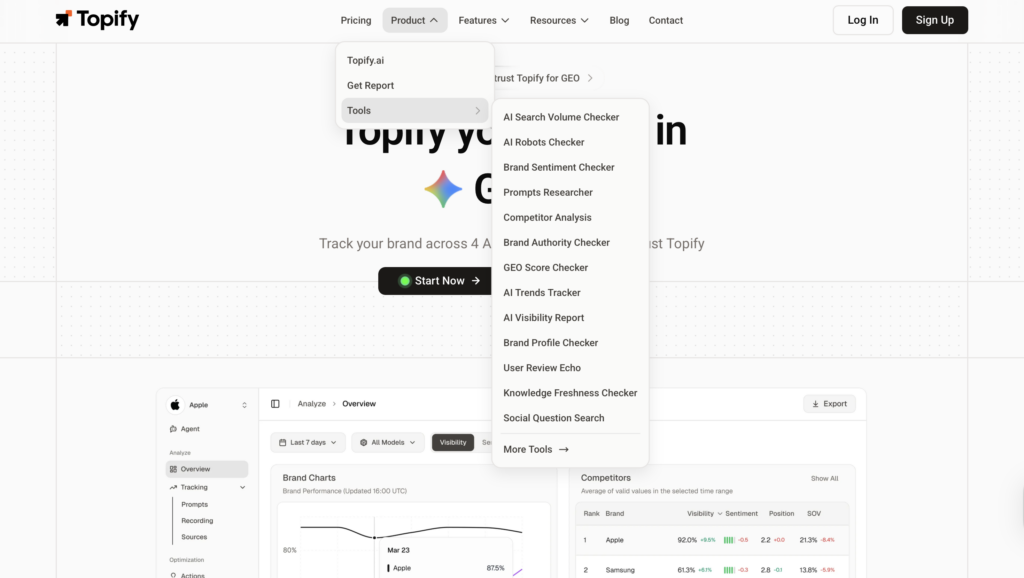
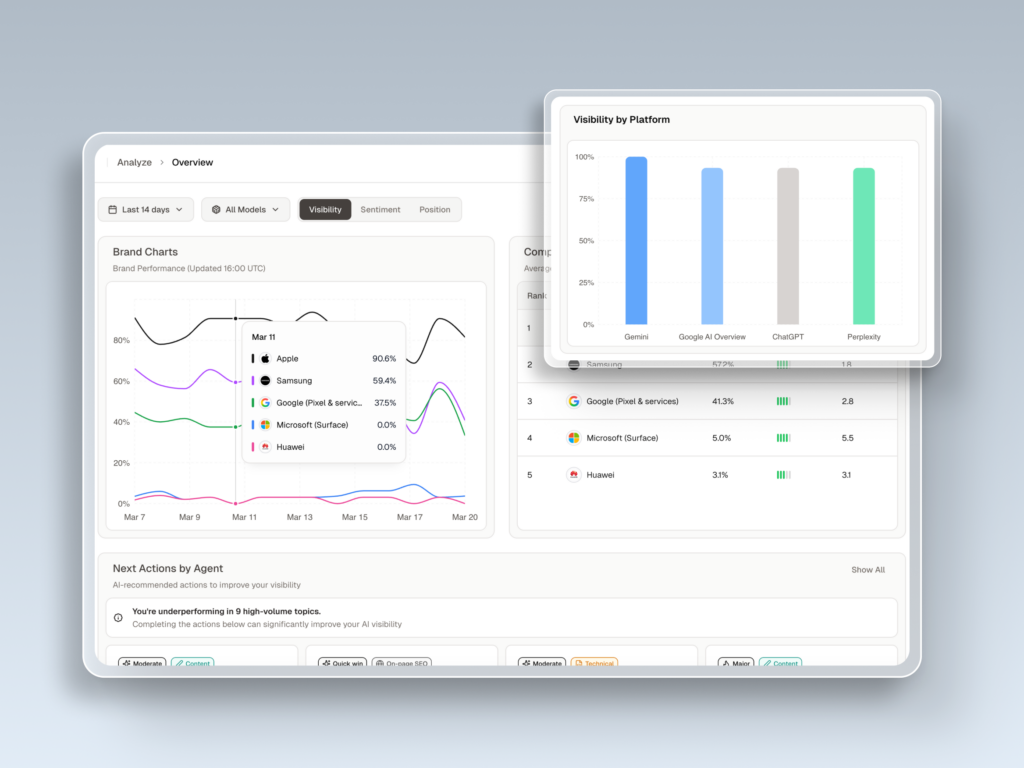
The platform monitors seven metrics across ChatGPT, Gemini, Perplexity, DeepSeek, and other major AI engines: visibility, sentiment, position, volume, mentions, intent, and CVR (Conversion Visibility Rate). Together, these give a marketing team a working picture of how AI systems describe and recommend their brand, not just on one platform, but across the ones their audience actually uses.
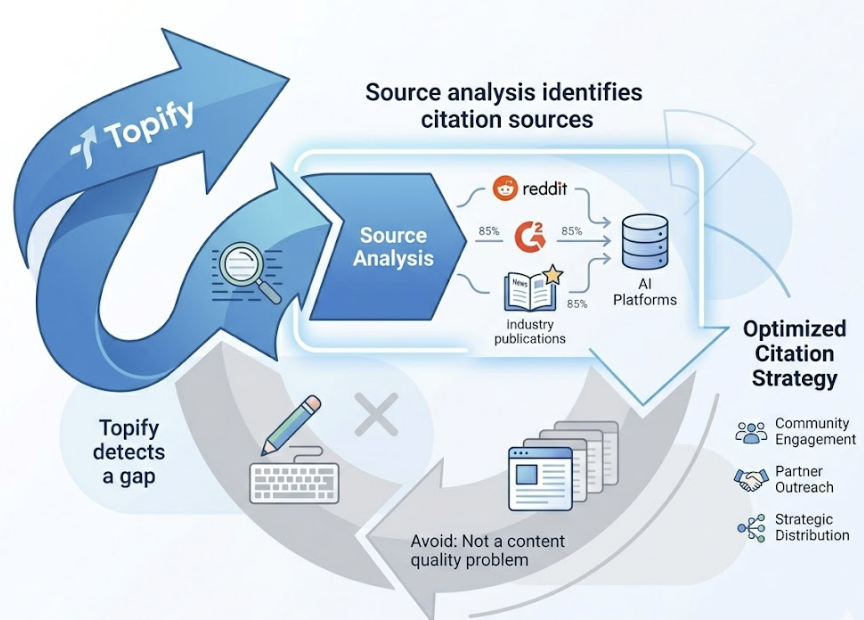
The Source Analysis feature is especially relevant for AEO work. It reverse-engineers which third-party URLs the AI is citing for a given topic, so a content team can identify exactly which domains they need to appear on to earn a citation. That’s a materially different workflow from traditional link-building.
Topify’s AI Volume Analytics surfaces high-frequency prompts being used on ChatGPT and Perplexity that have no recorded volume in conventional keyword tools. For brands that want to build content targeting the AI’s internal reasoning process, that prompt data is the starting point, not an afterthought.
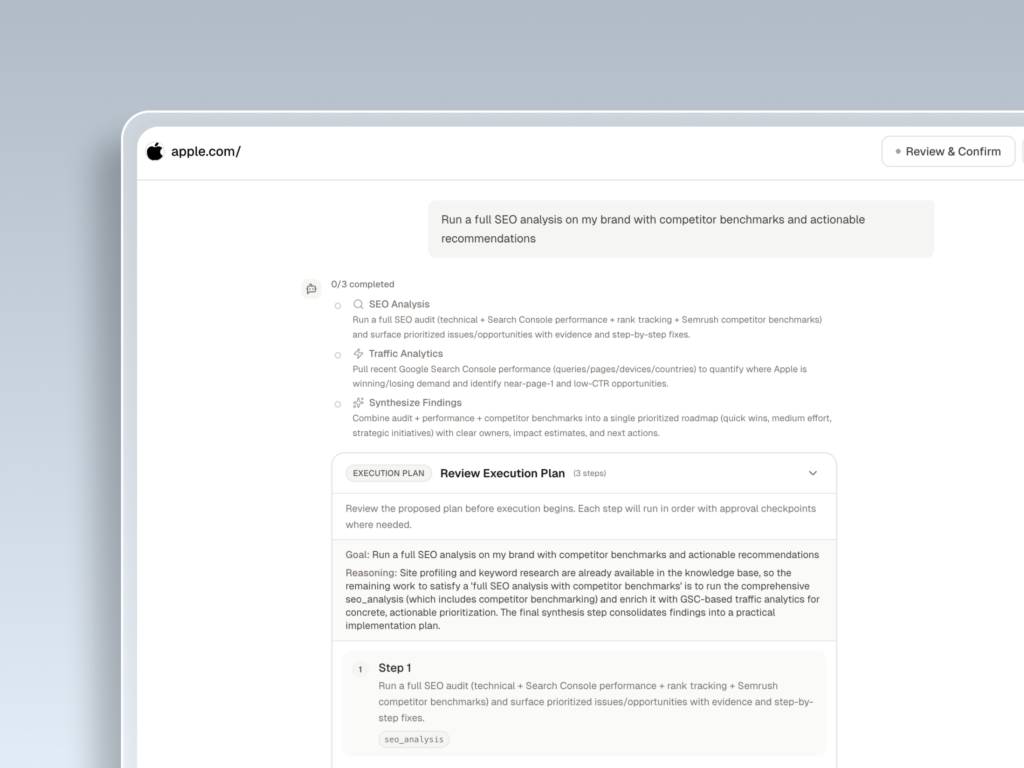
The GEO agent layer takes it one step further: rather than just showing you what’s missing, it proposes and can execute optimization strategies with a single click. For teams managing multiple brands or clients, that changes the labor math.
Trusted by 50+ enterprises and startups, Topify is built for LLM-era visibility from the ground up, not retrofitted from a legacy SEO platform.
How to Get Started with AEO Optimization
The entry point doesn’t need to be complex. Here’s a practical framework.
Start with a baseline audit. Pick your top 15-20 high-intent questions and test them across ChatGPT, Gemini, and Perplexity. Document where you’re mentioned, where you’re cited but not named, and where you’re absent entirely. That three-way breakdown tells you what kind of problem you’re actually solving.
Identify your real AI competitors. The brands the AI recommends in your category are often not the same ones ranking on Google. This is a consistent finding for brands running their first AEO audit. It changes which content gaps matter most.
Prioritize by prompt volume. AEO tools with AI Volume Analytics show you which specific questions your audience is asking AI platforms. Start with high-volume prompts where you’re currently absent. That’s where the conversion opportunity is largest.
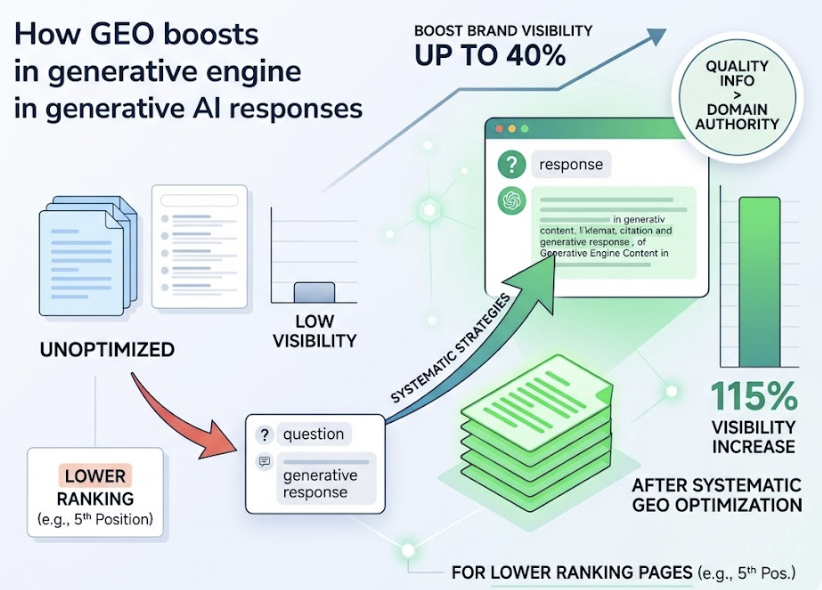
From there, content structure matters more than content volume. Research from Princeton found that adding expert quotes to existing content improves AI visibility by 41%, and incorporating specific statistics boosts it by 31-37%. These are repeatable improvements to content you’ve already published.
Setting up a consistent AI answer monitoring system lets you track whether those updates are actually moving your mention rate, rather than optimizing blind. Update your content at least every 90 days and treat your mention rate the same way you’d treat a keyword ranking: something that shifts, drifts, and requires active management.
Get started with Topify to run your first cross-platform AEO audit.
Conclusion
Your SEO rankings measure how Google sees your content. They say nothing about what ChatGPT, Perplexity, or Gemini recommends when someone asks a question you should be answering.
AEO tools bridge that gap. They tell you whether you’re in the answer, how you’re described when you are, which sources the AI trusts over yours, and which high-volume prompts you’re completely missing. That’s the diagnostic layer traditional analytics can’t provide.
As traditional search volume continues its decline and AI-native discovery becomes the default for high-intent research, brands with a clear picture of their AI visibility will have a structural advantage. The ones flying blind on this won’t find out what they’ve missed until the traffic data catches up a year later.
FAQ
Q: What does AEO stand for? A: AEO stands for Answer Engine Optimization. It’s the practice of optimizing your brand’s content and entity presence to appear in the synthesized answers generated by AI platforms like ChatGPT, Perplexity, and Gemini, rather than just in traditional search results.
Q: Is an AEO tool the same as a GEO tool? A: They overlap significantly but aren’t identical. AEO focuses on being included in direct AI answers and zero-click environments like featured snippets and AI Overviews. GEO (Generative Engine Optimization) refers specifically to how LLMs synthesize information and how to ensure your brand is cited as a trusted authority during that generation process. Many platforms, including Topify, cover both layers in a single dashboard.
Q: Do I need an AEO tool if my SEO is already strong? A: Strong SEO doesn’t automatically translate to AI visibility. A brand can rank #1 on Google for a keyword and be entirely absent from the AI answer for the exact same query. Google prioritizes authority and relevance for rankings. AI engines prioritize structural clarity, entity consistency, and third-party citation patterns. The two systems are separate, and you need visibility into both.
Q: Which AI platforms should an AEO tool cover? A: At minimum, a useful AEO tool should cover ChatGPT, Google Gemini, and Perplexity, which together account for the majority of consumer AI search behavior in 2026. Regional platforms like DeepSeek matter for brands with international audiences. Given that there’s less than 11% overlap in what ChatGPT and Perplexity cite, single-platform tracking leaves most of the picture invisible.