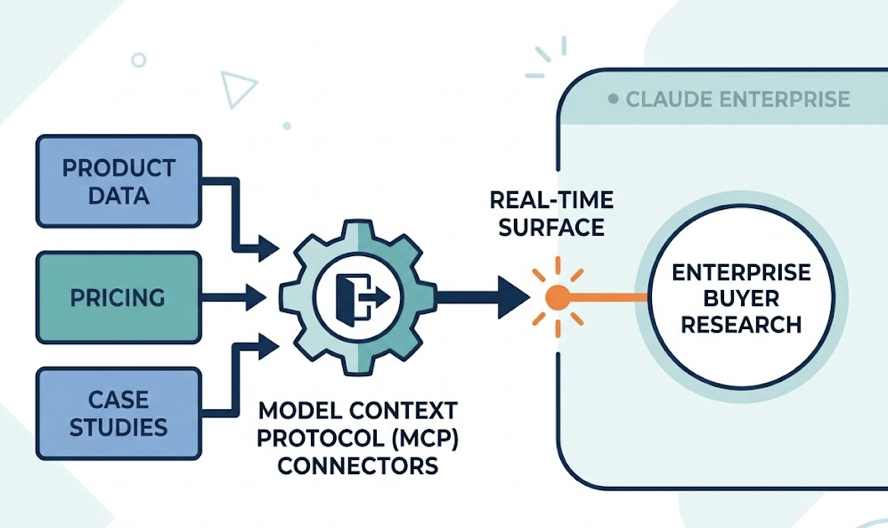
You ran a GEO score check. The number came back somewhere in the 40s or 50s. Now you’re staring at a dashboard and wondering what, exactly, you’re supposed to do with that information.
That’s the gap most optimization content doesn’t fill. Knowing your score is step one. Knowing which specific changes will actually move it — and in what order — is where most teams get stuck. Research has a clear answer on this. Pages that hit a GEO score of 0.70 or above, covering at least 12 signal dimensions, achieve a 78% cross-platform AI citation rate. The three factors that drive the most of that outcome aren’t content volume or keyword density. They’re metadata freshness, semantic HTML structure, and structured data.
Here’s what to fix, and why it works.
Your GEO Score Isn’t One Metric — It’s a Weighted System
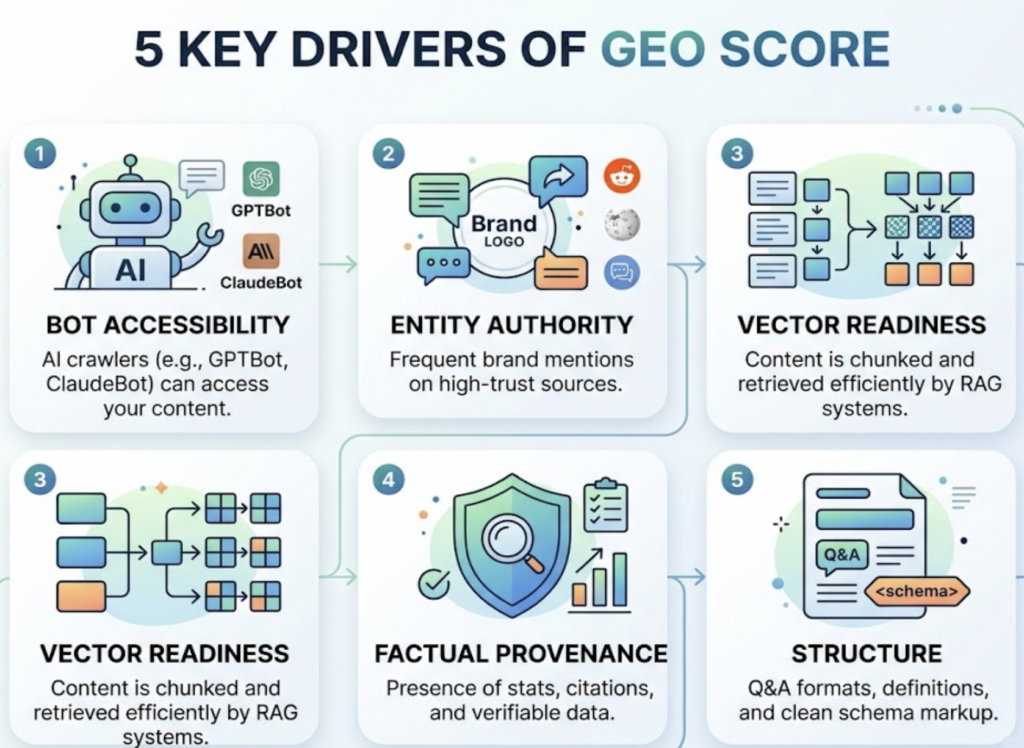
Most teams treat GEO score like a single number to push upward. It’s not. It’s a composite of 12 signal dimensions that reflect how ready a page is for AI retrieval and citation.
According to Geoptie’s framework, these dimensions span technical infrastructure, content architecture, authority signals, and monitoring practices. The weighting matters here: “AI interpretability” and “semantic richness” together account for more than 55% of the total score. That’s why brands can have strong content but still score in the 40–60 range — they’ve invested in the wrong dimensions.
The practical implication is that improving your GEO score isn’t about doing everything at once. It’s about identifying which of the 12 dimensions are dragging your weighted average down. In most cases, three categories explain the majority of the gap.
The 3 Factors Behind 78% of AI Citation Rate
Research by Arlen Kumar and Leanid Palkhouski, conducted at UC Berkeley and the Wrodium Research Center, audited 1,702 citations across Brave Summary, Google AI Overviews, and Perplexity. The finding that stands out isn’t just the 78% citation rate at G ≥ 0.70 — it’s the threshold effect. Citation probability doesn’t increase linearly with quality. It jumps once a page crosses the 0.70 line.
The three factors with the highest correlation coefficients in the logistic regression were:
| Factor | Correlation (r) | Primary Mechanism |
|---|---|---|
| Metadata Freshness | 0.68 | Addresses RAG time-decay bias |
| Semantic HTML Structure | 0.65 | Reduces extraction noise |
| Structured Data (Schema) | 0.63 | Accelerates entity recognition |
These aren’t arbitrary rankings. Each one directly resolves a specific obstacle in the Retrieval-Augmented Generation (RAG) pipeline that AI engines use to pull and synthesize content. A page that scores well on all three gives an AI model cleaner data, clearer context, and more confidence that the content is current.
High-scoring pages are 4.2 times more likely to be cited than low-scoring pages. That’s the odds ratio from the same study. The asymmetry is significant enough that fixing these three factors should come before anything else.
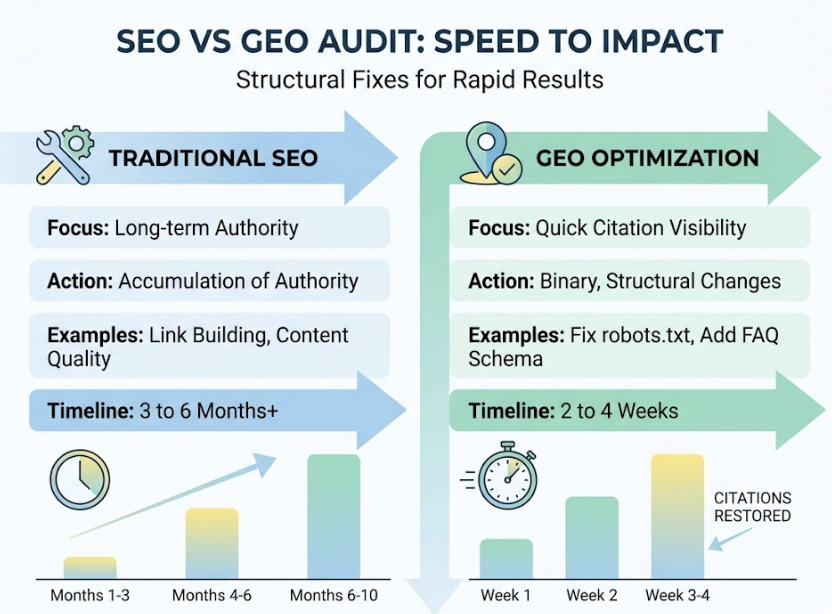
Change #1: Refresh Your Metadata Before You Touch Anything Else
Metadata freshness has a correlation coefficient of 0.68 with AI citation rate — the highest of the three. The reason is straightforward: AI engines with real-time retrieval capability, like Perplexity, are trained to prioritize current, accurate information. Stale metadata acts as a binary filter. A page whose timestamp still reads 2023 can get excluded from the candidate pool before an AI even evaluates its content.
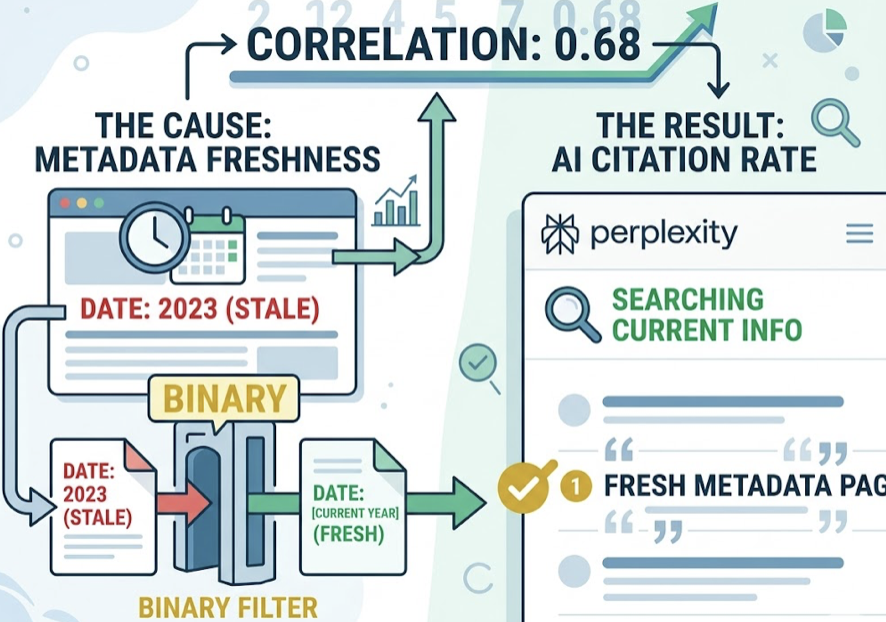
The data on this is concrete. Content updated within the past 60 days is cited 1.9 times more often than older content. That’s not a marginal improvement — it’s nearly double the citation rate for pages that simply signal recency.
The operational fix is more specific than just “updating content.” Three fields matter most:
Last-Modified header: This needs to appear in both the HTTP response header and the HTML source. It should be a machine-readable timestamp, not a visible date string.
Meta description: AI-optimized meta descriptions should be 50–100 words and state the page’s core conclusion directly. The traditional click-bait format doesn’t serve AI retrieval — a concise, factual summary does.
OG tags: These are often overlooked. If your Open Graph tags reference an old version of a headline or image, AI systems pulling cached data will work with outdated information.
For fast-moving industries, a monthly metadata audit is worth building into the content calendar. For evergreen content, quarterly is sufficient.
Change #2: Rebuild Your Page Structure with Semantic HTML
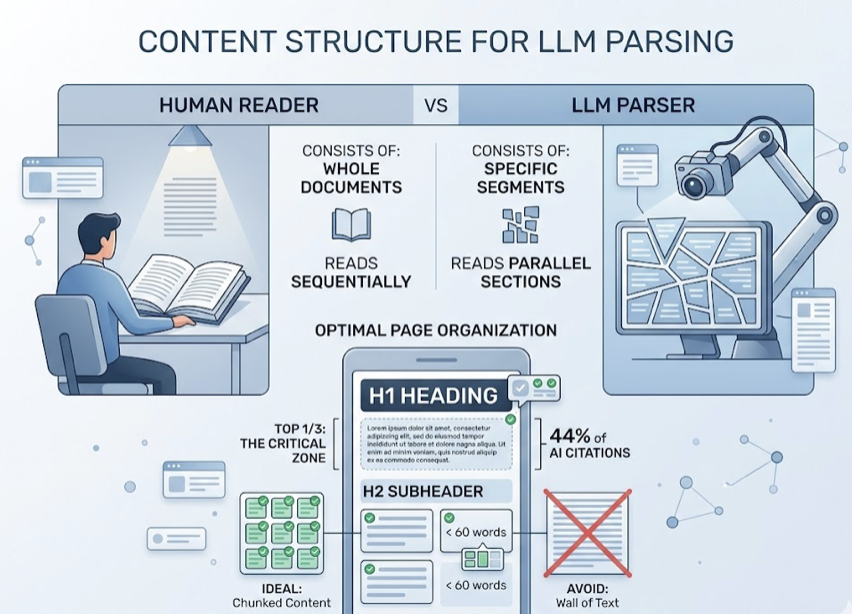
The correlation between semantic HTML structure and AI citation rate is 0.65. That’s because AI retrieval systems don’t read pages the way humans do — they parse them. A page built with generic <div> containers creates extraction noise. A page with proper semantic markup gives the retrieval model a clear map.
Research shows that clear H1–H3 heading hierarchies allow AI models to achieve 85% chunking accuracy during text parsing. Without semantic structure, content gets fragmented or loses context during extraction — meaning even good content can get cited incorrectly or not at all.
Five structural changes with the highest GEO impact:
<article> and <section> tags: These define content boundaries. When a retrieval system encounters these tags, it treats the content inside as a discrete information block — which is exactly how you want your content to be indexed and vectorized.
<header> and <main> tags: These help crawlers separate navigation and sidebar content from the page’s actual substance. Without them, irrelevant sidebar text can get weighted alongside your core argument.
Strict H1–H3 hierarchy: H2 for primary sections, H3 for supporting points. This creates a natural summary-to-detail relationship that AI can use to generate accurate, structured answers.
<table> with <thead>: Tabular data gets cited at 2.5 times the rate of plain-text equivalents. If you’re making comparisons or presenting data, a table isn’t just visually cleaner — it’s structurally superior for AI extraction.
<cite> and <blockquote>: When your content references expert sources, these tags explicitly signal attribution. That transparency raises the page’s authority score in AI evaluation.
The underlying principle: a “clean” HTML architecture is the physical prerequisite for G ≥ 0.70. You can’t compensate for structural chaos with better content.
Change #3: Add Structured Data — and the Right Kind
If semantic HTML is about making content extractable, JSON-LD structured data is about making it understandable. It converts natural language into machine-readable fact sheets that AI engines can use to verify, categorize, and confidently cite information.
Pages with structured data show 43–44% higher visibility in AI responses. The mechanism is direct: when a RAG pipeline matches a query to a page with Schema markup, the AI’s confidence in generating an accurate answer increases. That confidence translates into citation.
Four Schema types that move the needle most:
FAQPage: This is the highest-leverage Schema type for GEO. Since generative search is fundamentally a question-answering system, FAQ structure allows AI to directly extract a question and its verified answer. Even pages that have lost Google SERP visibility can gain AI citation volume through FAQPage markup.
Article: Defines content type, author identity, and publication date. This is the primary input for E-E-A-T evaluation — the set of signals AI uses to assess whether an author and publisher are credible.
Organization: Establishes your brand as a distinct entity. This is what allows AI systems to aggregate information about your brand from multiple sources and attribute it correctly.
HowTo: For procedural queries, structured step data gets extracted more reliably than long-form prose. If your content explains a process, HowTo Schema turns it into a format AI can use directly.
The fastest path to implementation: identify the key entities on each page, generate JSON-LD using a Schema generator, and add SameAs properties that link your entities to authoritative third-party profiles. That linkage alone has been shown to raise authority scores by 20% or more. One non-negotiable: render Schema server-side, not via client-side scripts. AI crawlers need to parse it immediately.
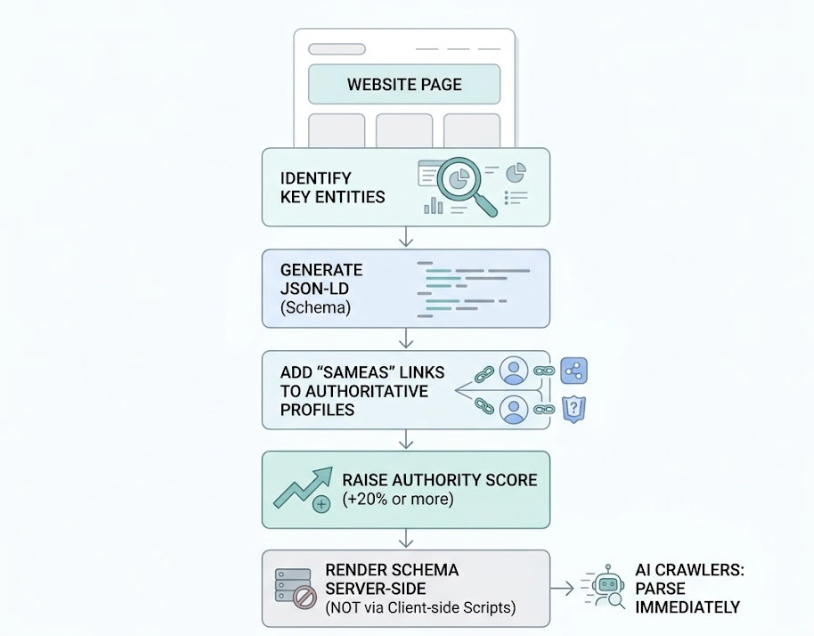
Changes #4 and #5: The Last Mile to 0.70
Once the technical foundation is in place, two more factors determine whether a page can reach and hold a score above 0.70. These are less about infrastructure and more about content depth.
Change #4: Strengthen Authority Signals
In the 12-dimension GEO scoring model, authority signals carry high weight. Research from Princeton (Aggarwal et al., 2023) confirmed that specific authority-building interventions produce measurable citation gains.
Adding concrete statistics to a page improves AI visibility by 40%. Not approximate ranges — specific numbers. AI engines treat quantitative data as a verification anchor. If your content can make a claim and back it with a precise figure, it becomes more citable than a page making the same claim without evidence.
Including expert quotations lifts visibility by 30% or more. AI interprets direct attribution as a signal of industry consensus and depth of sourcing.
The counterintuitive one: citing high-authority external sources within your content. This doesn’t dilute your page’s value — it positions the page as a knowledge hub. Pages that actively cite credible external references have shown visibility gains of 115% in AI responses for Tier 5 sites. The logic is that AI models view outbound links to authoritative sources as a sign that the content is well-researched and contextually accurate.
Change #5: Optimize for Answer Density
AI models have a finite context window. They’re looking for pages that deliver the highest information-to-token ratio. A page that answers a question directly, with minimal setup and no filler, is more likely to be selected as a source.
Content written at a Flesch-Kincaid grade level of 6–8 gets cited 31% more often than content at higher complexity levels. That’s not about dumbing down — it’s about removing friction from the extraction process. Short sentences and direct statements are faster for AI to parse and verify.
Each paragraph should orbit one central fact. Transitional throat-clearing (“As we’ve seen so far…”) consumes token space without adding information. Cut it.
There’s also a credibility angle: content that explicitly acknowledges trade-offs or presents multiple perspectives is 1.7 times more likely to be cited than single-viewpoint content. AI models appear to weight intellectual honesty — admitting what a recommendation doesn’t cover — as a quality signal.
You’ve Optimized. Now Track Whether AI Actually Notices.
These five changes will move your GEO score. But here’s what most teams discover next: they don’t know if it worked.
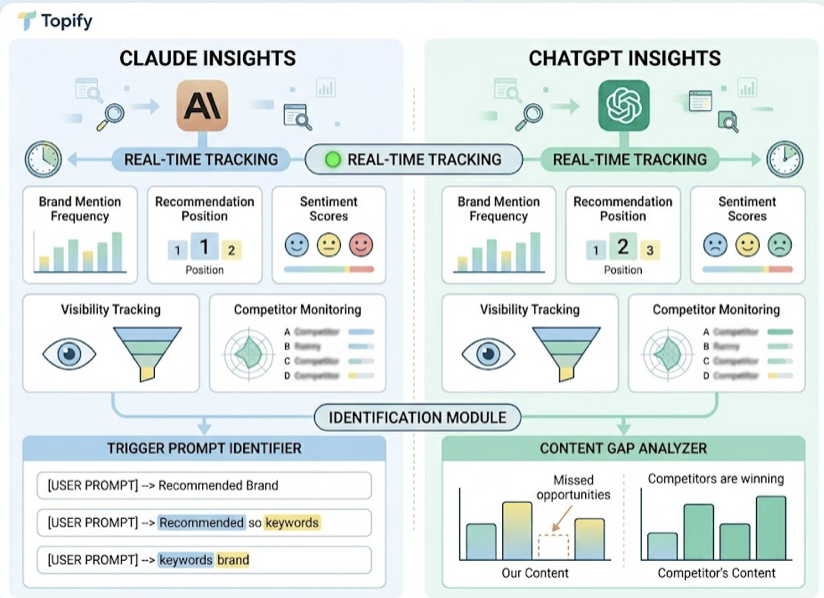
AI citation is probabilistic. The same prompt can produce different results across ChatGPT, Perplexity, Gemini, and Claude — and can shift week to week as models update. A one-time score check tells you where you started. It doesn’t tell you whether your brand is being cited now, what language AI is using to describe you, or which competitors just moved ahead of you in AI recommendations.
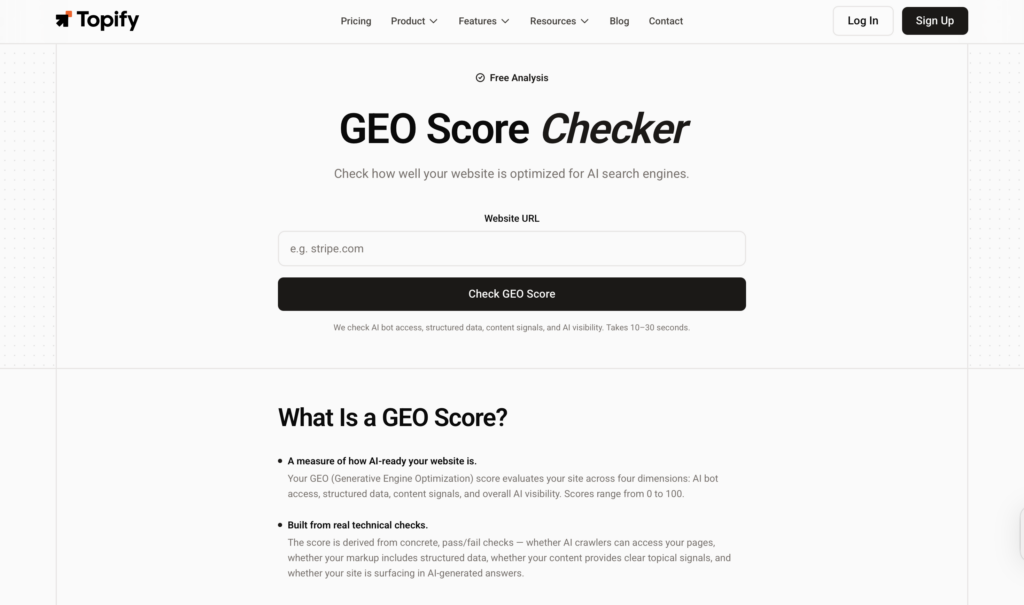
That’s the problem Topify is built to solve. The GEO Score Checker gives you a baseline — and ongoing monitoring across major AI platforms shows you what happens after you’ve made the changes. You can track visibility by prompt, monitor sentiment in AI-generated descriptions, and analyze which source URLs AI platforms are actually citing when they answer questions in your category.
Top brands in competitive categories reach 12% AI visibility on relevant prompts. The average is 0.3%. The gap between those two numbers isn’t just about content quality — it’s about whether a brand is iterating on real citation data or guessing.
Optimization without measurement is a one-time event. Measurement turns it into a system.
Conclusion
A GEO score below 0.70 typically means a page has structural gaps, not content gaps. The three highest-leverage changes — metadata freshness, semantic HTML architecture, and structured data — address the retrieval and comprehension bottlenecks that prevent AI from citing even well-written content.
Changes #4 and #5 close the gap for pages already near the threshold. Authority signals and answer density are what separate a page that sometimes gets cited from one that consistently does.
Start with a GEO score check to know which dimensions are pulling your score down. Fix the technical layer first — metadata, HTML, Schema. Then add the content-level authority signals. And build a monitoring system that tells you whether the citations are actually coming in.
The research is clear on what the threshold is. Whether you’ve hit it is a measurement question, not a guessing one.
FAQ
Q: What is a good GEO score for AI citations?
A: A score of 70 or above is generally considered the baseline for entering the AI citation pool. Pages at this level have sufficient semantic structure and metadata to be included in multi-engine retrieval. To hit the 78% cross-platform citation rate identified in the Kumar et al. research, you’d want to push toward 85+. Most current websites score in the 40–60 range, so exceeding 70 already represents a significant competitive advantage.
Q: How long does it take to see GEO score improvements after optimization?
A: Technical changes — Schema markup, metadata updates, HTML restructuring — typically register within 1–2 weeks, once AI crawlers re-index the page. Longer-term authority signals like E-E-A-T improvements can take 3–6 months to shift how AI models represent your brand in non-RAG contexts, where the underlying knowledge base needs time to update.
Q: Does improving my GEO score also help traditional SEO rankings?
A: Yes, and the correlation is strong. Around 80% of AI citations already come from pages that rank in Google’s top 10. The technical requirements for GEO — structured data, fast load times, semantic markup, quality external links — are the same signals Google’s ranking algorithm rewards. Improving your GEO score is, in practice, a reinforcement of the same content quality and technical health that drives traditional SEO.
Q: Which Schema type has the biggest impact on GEO score?
A: FAQPage Schema tends to have the highest GEO impact because generative search is fundamentally a question-answering system. AI engines can directly extract the question and its answer from FAQPage markup, which is cleaner and more reliable than parsing a long-form paragraph for the same information. Article and Organization Schema are also high-priority additions, particularly for establishing entity identity and E-E-A-T signals.