Your domain authority is solid. Your keyword rankings are exactly where you want them. Then a prospect asks Claude, “What tools do you recommend for [your category]?” and your brand isn’t in the answer.
That’s not a fluke. It’s a structural gap, and traditional SEO metrics can’t explain it because they weren’t built to measure it. Google ranking and Claude AI brand visibility operate on completely different logic, and most marketing teams don’t realize this until they’re already losing ground to competitors who do.
Two Search Systems That Don’t Speak the Same Language
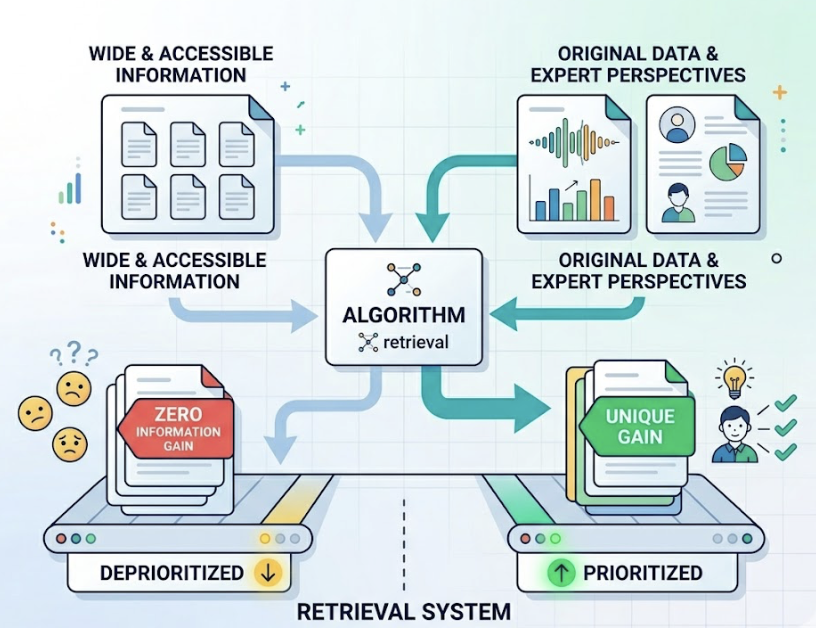
Google is a retrieval system. It ranks URLs based on backlinks, keyword relevance, and technical performance, then hands you a list of ten results to click through.
Claude is a synthesis system. It reads, reasons, and generates a single response. There’s no list of ten options. There’s a shortlist of two or three, and everything else is invisible.
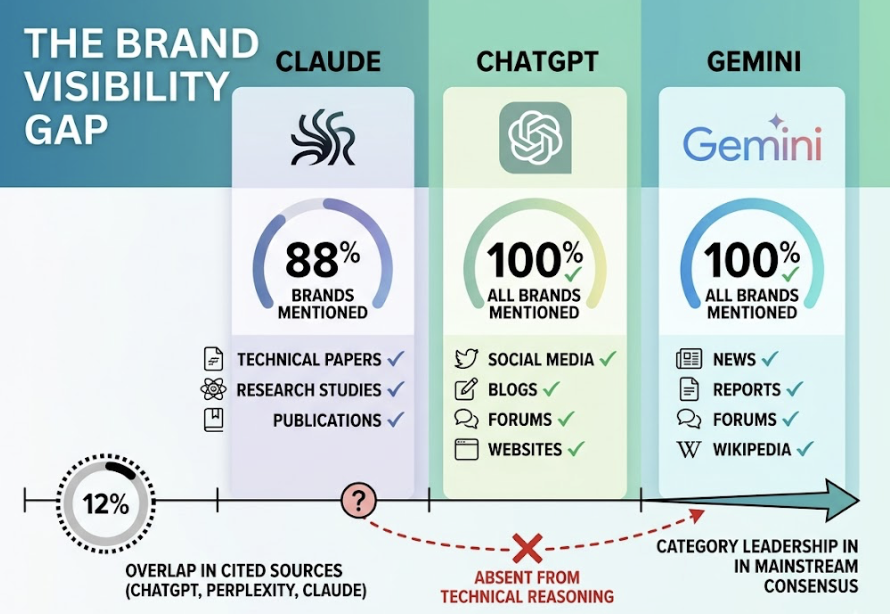
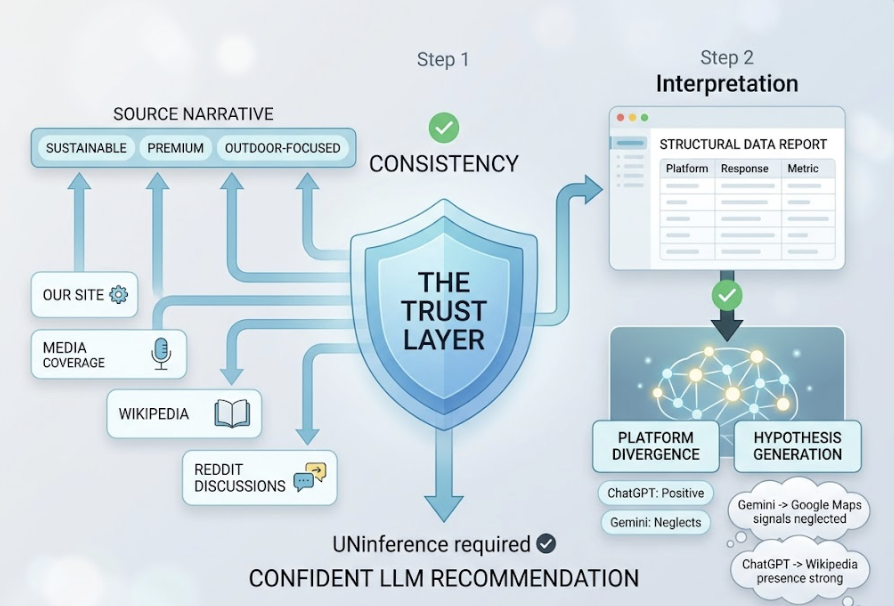
The authority signals are different too. Google weighs domain authority and backlink profiles. Claude weighs what researchers call “Digital Consensus”, how often a brand is mentioned with consistent attributes across multiple high-trust sources. A brand that dominates its own domain but rarely appears in third-party coverage may rank first on Google and not register at all in Claude’s reasoning.
That’s the gap most brands still can’t see.
What Claude Actually Uses to Decide Who to Mention
Here’s something most SEO teams don’t know: Claude doesn’t primarily use Google’s index for real-time queries.
Statistical analysis shows that Claude has an 86.7% correlation with Brave Search results, compared to ChatGPT’s 26.7% correlation with Bing. In practice, this means a brand optimized exclusively for Google but absent from Brave’s index is functionally invisible to Claude’s retrieval layer. Two platforms, two completely different indexes.
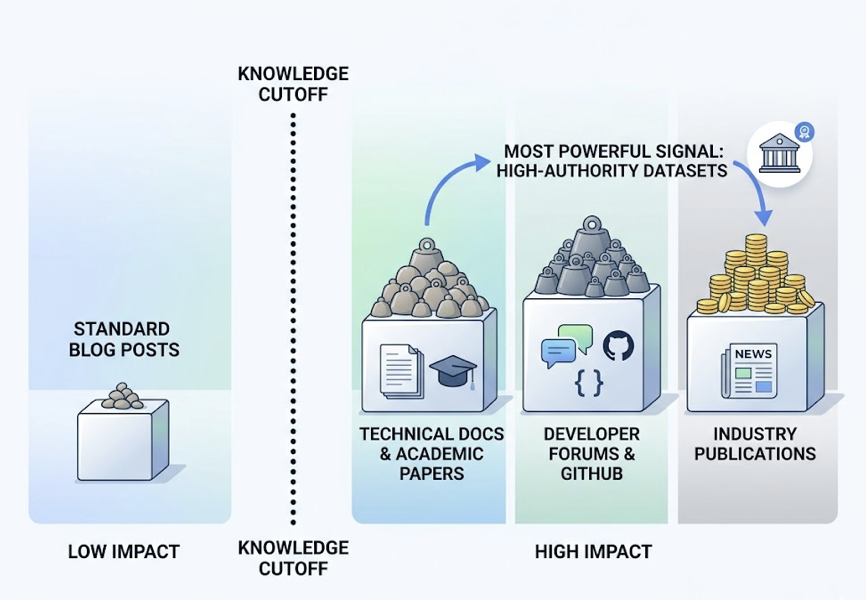
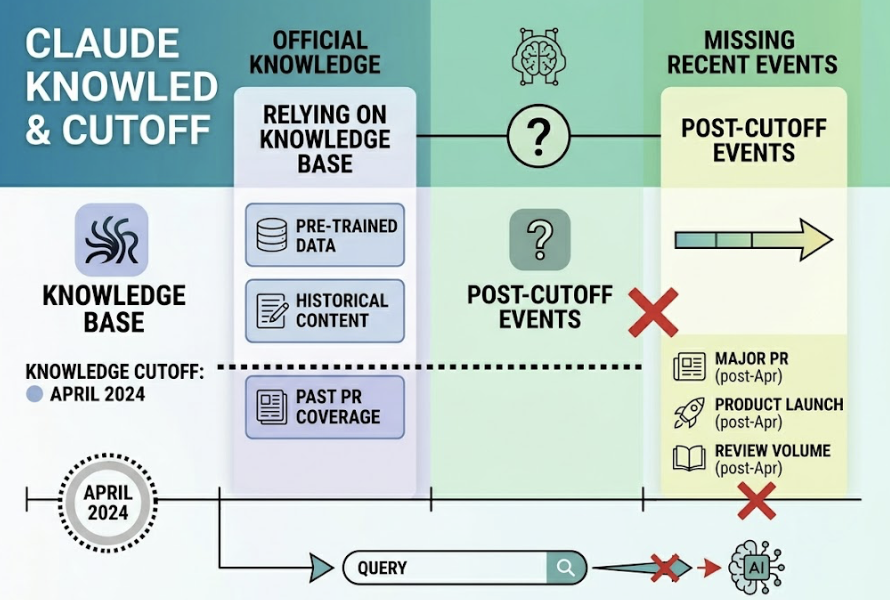
For queries that don’t trigger a live web search, Claude relies on its pre-trained knowledge base. Claude 3.5 Sonnet has a knowledge cutoff of April 2024. If your brand’s major PR coverage, product launches, or review volume came after that date, the model’s base parameters simply don’t reflect your existence unless the browsing tool is explicitly activated.
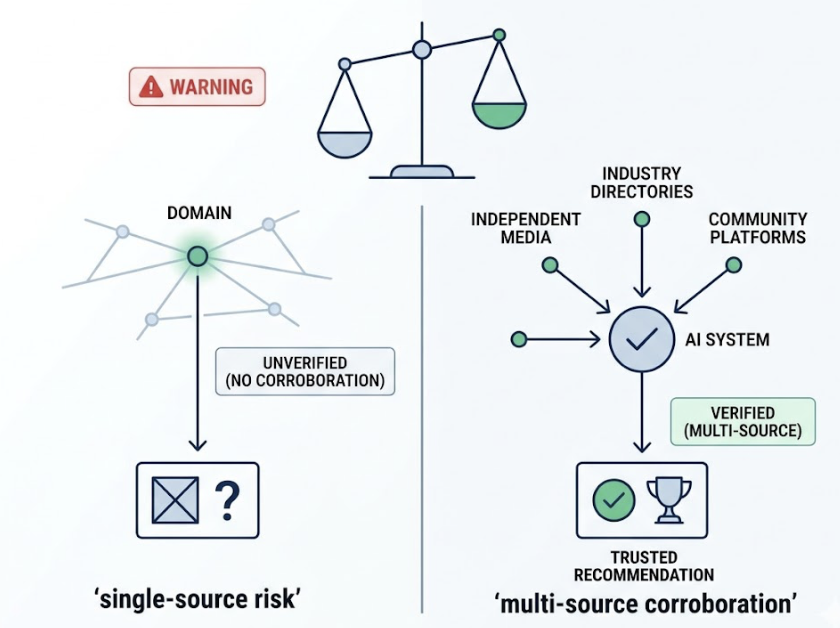
Anthropic’s training approach also weights “reliability” heavily. Claude favors facts that are corroborated across multiple high-trust domains: established media, government sources, industry journals. If your brand’s claims only live on your own website, Claude lacks the external proof to recommend you with confidence.
5 Reasons Your Brand Disappears in Claude’s Answers
These aren’t ranking failures in the traditional sense. They’re extractability and credibility failures.
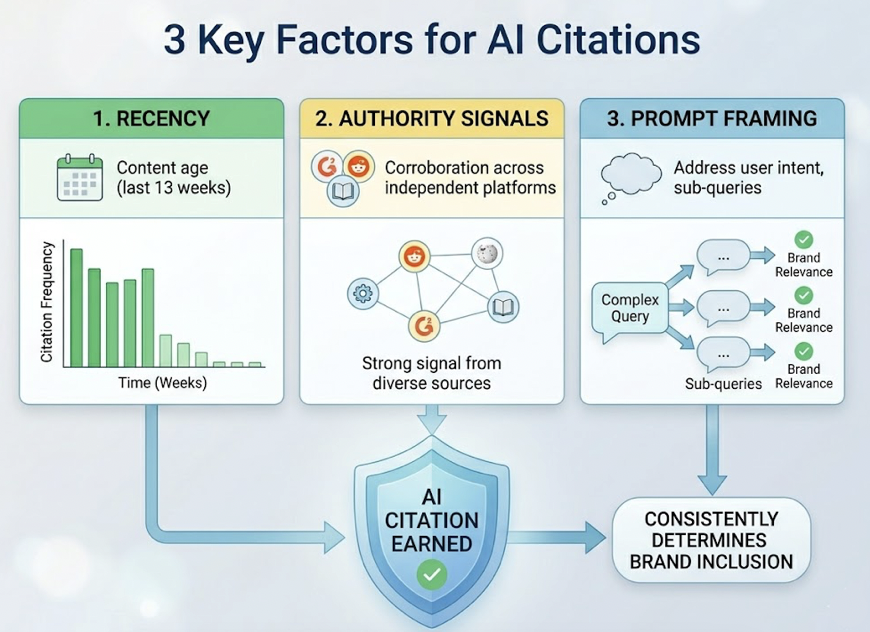
No third-party digital consensus. AI models evaluate brands as entities within a knowledge graph. An entity’s strength comes from how often it’s co-mentioned with specific attributes across high-trust sources. Strong internal SEO doesn’t help here. What Claude needs is earned coverage on Reddit, established publications, G2, and similar platforms.
Content that’s not machine-extractable. Research shows that in 40% of cases, AI models skip the Google #1 result in favor of a page-two result that uses a clear table or FAQ block. Cluttered, marketing-heavy pages require more “computational noise” to summarize, so models skip them. Structured, fact-dense content wins the citation slot.
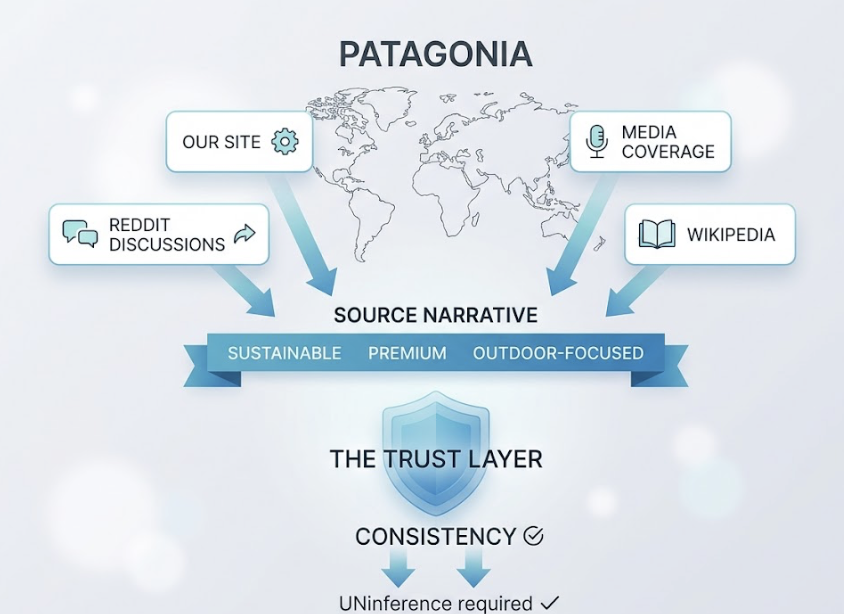
Insufficient brand proof points in training data. If a brand isn’t frequently mentioned in high-density datasets like Common Crawl or Reddit, it develops a low co-occurrence probability. For established brands, associations like “sustainable” and “Patagonia” are mathematically inseparable in a model’s weights. Newer or niche brands without that kind of presence fail to trigger the model’s internal association engine.
Competitors already own the citation sources. Generative AI is a zero-sum game. An AI response typically surfaces two or three options. If a competitor has secured placements in the sources Claude trusts, like a specific comparison guide or a heavily-upvoted Reddit thread, they own the retrieval slot. You don’t get a second listing.
Weak knowledge graph presence. Traditional SEO focuses on keywords. Claude’s logic runs on semantic triples: Subject, Predicate, Object. If your brand doesn’t use structured data or Schema.org markup to explicitly define its relationship to its category, the model is forced to guess. Guessing usually results in omission.
How to Actually Measure Claude AI Brand Visibility
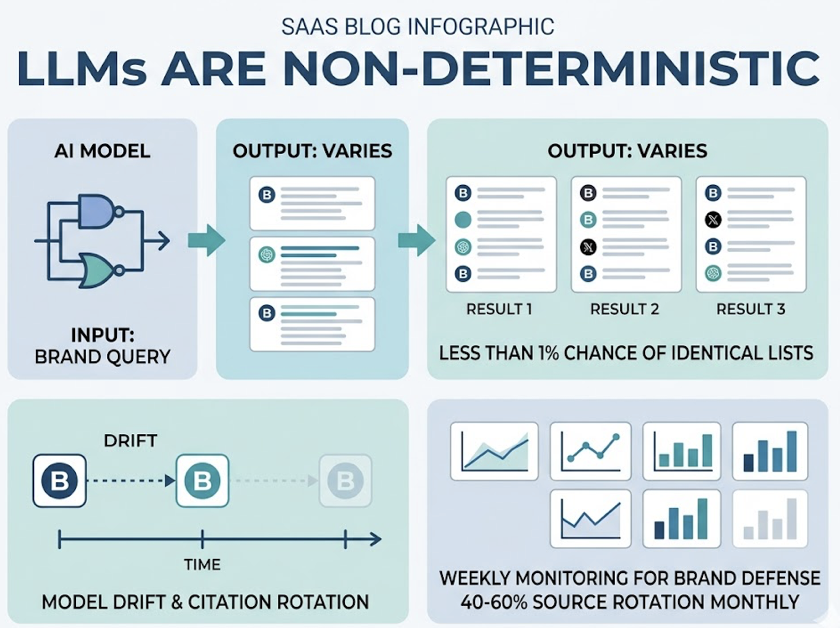
Manual spot-checking doesn’t work.
LLMs are non-deterministic. A model might mention your brand in response to one prompt and omit it in the next based on minor phrasing variations. You can’t build a strategy on anecdotal checks.
What actually works is systematic prompt testing across multiple AI platforms, tracking five core metrics:
| Metric | What It Measures |
|---|---|
| AI Visibility Rate | % of relevant prompts where your brand appears |
| Position Score | Average rank in the response (1st vs. 4th) |
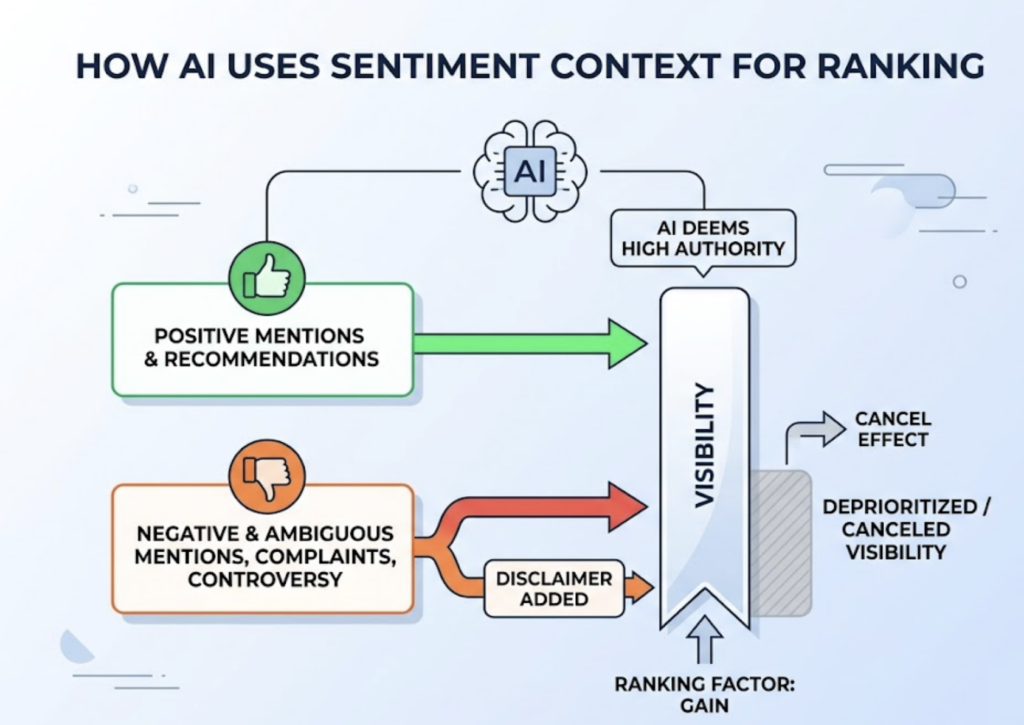
| Sentiment Score | Tone of the mention: recommended vs. neutral |
| Citation Frequency | How often your domain is cited as a source |
| Entity Strength | How closely the AI associates your brand with your category |
Position matters more than most teams realize. Research into AI-referred traffic shows visitors from AI citations convert at 4.4x to 9x the rate of traditional search traffic. But that conversion potential is concentrated in the top-ranked mentions. First position in an AI response carries roughly 5x the weight of being listed fourth.
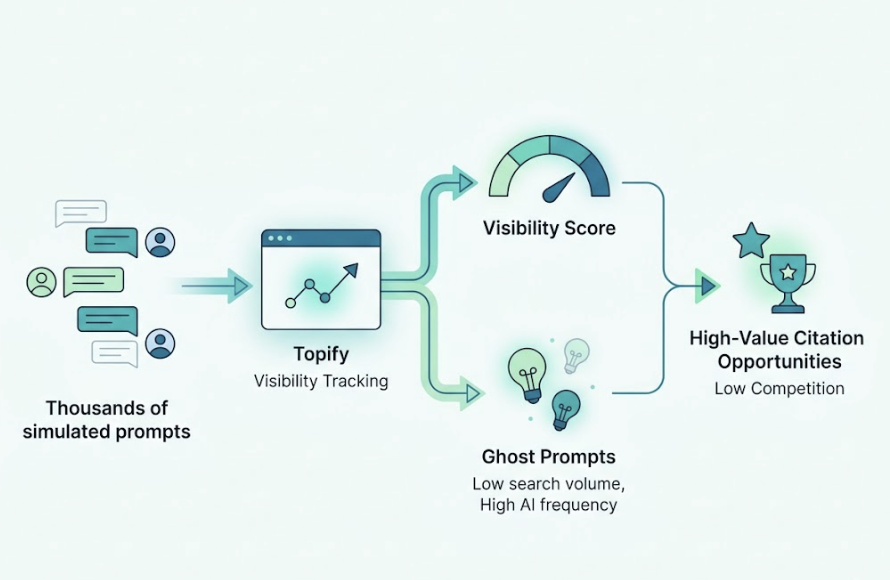
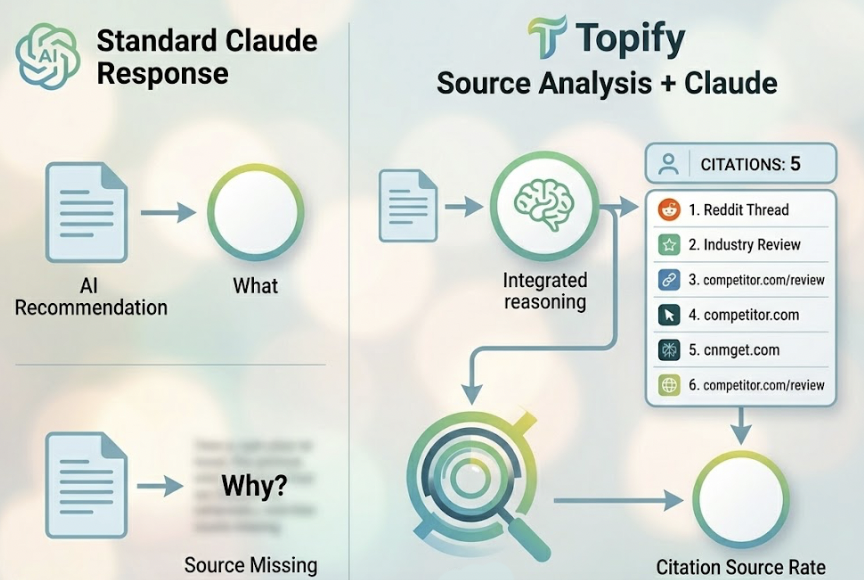
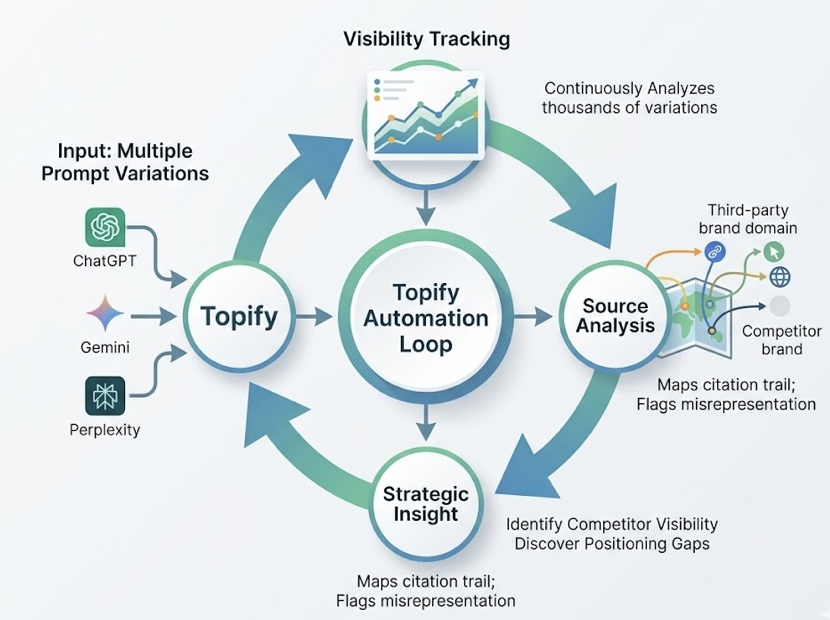
Topify automates this through what it calls Prompt Matrixing: querying models thousands of times across different phrasings, personas, and locations to produce a Share of Voice score. The output isn’t just a single visibility number. It maps exactly which prompts you’re invisible on, so you can prioritize where the gap costs you most.
What Actually Moves the Needle for Claude AI Brand Visibility
Research from Princeton and Georgia Tech identified a set of content changes that consistently increase AI citation probability. The numbers are specific enough to act on.
Adding concrete statistics instead of vague claims increases extraction rates by 37%. Embedding inline citations from industry reports improves visibility by 40%. Including direct quotes from named experts with titles adds another 30%. These aren’t soft recommendations. They’re measurable structural changes.
Beyond on-page content, entity verification matters. This includes claiming Google Business Profiles, keeping Wikipedia entries accurate where your brand qualifies, and ensuring consistent NAP data across platforms. The goal is to build what the research calls “Digital Consensus”: a pattern of corroborated facts that Claude can extract with confidence.
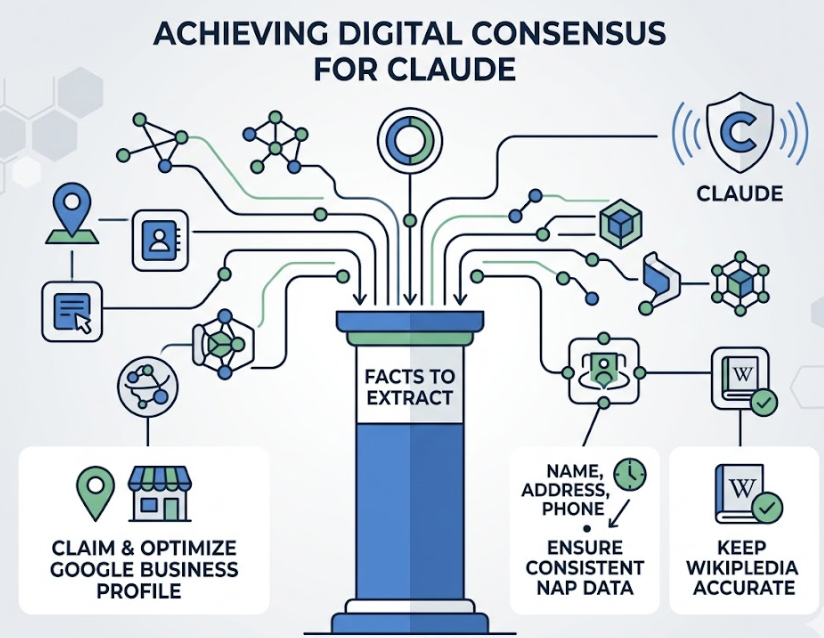
One more tactic worth deploying: hosting a Markdown summary at /llms.txt on your domain. It’s a lightweight file designed specifically for AI agents, and it speeds up accurate indexing without requiring a full crawl.
For the timeline: RAG-based citations, the real-time web layer, can be influenced in two to six weeks through structural content changes and Brave SEO. Influencing the base model, meaning the offline answers Claude generates without live search, requires consistent narrative across high-trust sites over six to eighteen months.
Topify’s One-Click GEO Strategy addresses the execution gap by automating schema markup deployment and data table insertion once a visibility gap is detected. You define the goal, the system handles the rollout.
Don’t Let Competitors Own the Answer
Here’s where the stakes get concrete.
AI responses don’t have a second page. There’s no “also consider” section below the fold. The brands that appear are the brands that matter to the user. The brands that don’t appear don’t exist in that decision moment.
Topify’s Competitor Monitoring shows which sources Claude is using to talk about your competitors. If a rival is winning citations through a specific industry comparison guide or a Reddit thread with high engagement, you can identify those sources and build coverage there before that foothold becomes permanent.
Position Tracking adds another layer. It monitors where your brand appears relative to competitors in actual AI responses, not just whether you appear at all. Being mentioned fourth, with a caveat about pricing, is meaningfully different from being the first recommendation. Both show up as “mentioned.” Only one drives conversions.
Gartner projects a 25% drop in traditional search volume by 2026 as AI assistants handle more of the discovery layer. The brands that are already building Claude AI brand visibility today are the ones that will own the shortlist when that shift completes.
Conclusion
Google ranking is a prerequisite, not a finish line.
Claude operates on a different set of trust signals, a different search backend, and a completely different content selection logic. A #1 ranking doesn’t carry over. It has to be earned separately, through third-party credibility, structured content, and systematic measurement.
The gap between Google visibility and AI visibility is real, it’s widening, and it’s measurable. The first step is knowing exactly where you stand. Get started with Topify to map your brand’s AI visibility across Claude, ChatGPT, and Perplexity in one place.
FAQ
Q: Does Google ranking help with Claude AI brand visibility at all?
A: Yes, but only indirectly. Claude’s search backend correlates strongly with Brave Search, which often aligns with Google results. So strong SEO remains a prerequisite for the retrieval layer. But ranking well doesn’t guarantee Claude will select your content for its final synthesized answer. That selection is based on structure, credibility signals, and third-party consensus, not rank position alone.
Q: How often does Claude update its knowledge?
A: Foundation models are retrained only a few times per year, often with a lag of six to eighteen months. Claude 3.5 Sonnet’s training data cuts off at April 2024. For real-time queries, Claude can access current web data through Brave Search, typically within two to fourteen days of a page being indexed.
Q: What types of content does Claude tend to cite?
A: Claude consistently favors structured, fact-dense content. Comparison tables, FAQ blocks, and authoritative guides that include inline citations and named expert quotes perform significantly better than long-form narrative pages. Content that’s easy for a model to extract a clean answer from wins the citation slot.
Q: How long does it take to improve brand visibility in Claude?
A: There are two timelines. For real-time RAG citations, structural content changes and Brave Search optimization typically show results in two to six weeks. For influencing Claude’s base model knowledge, the offline layer that doesn’t require a live search, expect six to eighteen months of consistent presence across high-trust sources.