Your team has an AI visibility tracker, an AI writing tool, and a CMS. Three tabs open, three logins saved. On paper, you’re running an agentic AEO workflow. In practice, you’re copying a visibility score from one dashboard, pasting it into a strategy doc, then manually briefing a content tool that has zero context on why that score dropped in the first place.
That gap between “we have AEO tools” and “we have an AEO agent” is where most marketing teams lose weeks of execution time every quarter. The fix isn’t another tool. It’s architecture: a three-layer stack where tracking, reasoning, and execution actually talk to each other.
Most AEO “Agents” Are Just Disconnected Dashboards
The pattern is predictable. A team buys a visibility tracker, subscribes to a content generation platform, and publishes through a CMS. Each product works fine in isolation. But the data flow between them? That’s a human analyst copying numbers between browser tabs.
Here’s where it breaks. Your tracker flags that Share of Model dropped from 12% to 4% on a specific prompt cluster. The tracker did its job. But it can’t tell you why it dropped, which competitor moved, or what content action would recover that position. A human has to figure all of that out, manually, before anything happens.
The cost of that manual connective tissue is steeper than most teams realize. Marketing professionals lose roughly 60 hours of productivity per year strictly from switching between disconnected tools. In environments without native integration, staff can waste over 125 hours annually on redundant data entry alone.
That’s not an AEO agent. That’s a swivel chair.
The industry is starting to acknowledge this structural failure. Conductor’s AgentStack launch in April 2026 signals a macro shift: as AI platforms consolidate the buyer’s discovery journey into single interactions, the underlying marketing infrastructure has to consolidate too. The solution isn’t more tools. It’s fewer seams.
What a Functioning AEO Agent Stack Looks Like
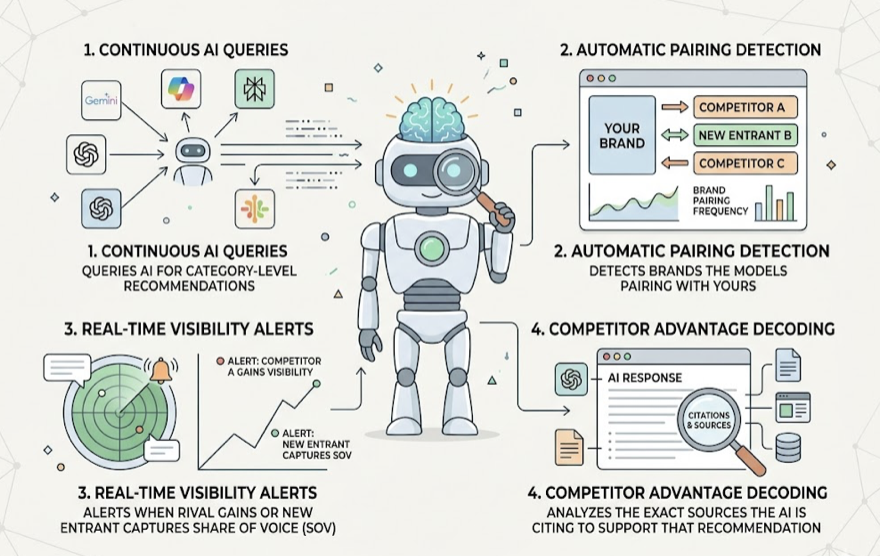
The cleanest way to think about an AEO agent is borrowed from autonomous systems theory: the Sense-Reason-Act-Learn loop. Translated into marketing operations, that becomes three layers with strict boundaries:
Tracking Layer answers one question: What’s happening right now? It monitors AI visibility, captures citation sources, records competitor movements, and measures brand sentiment. It doesn’t interpret. It doesn’t strategize. It observes.
Reasoning Layer answers a different question: What does this mean, and what should we do? It ingests tracking data, identifies causal relationships, and outputs a specific execution plan.
Execution Layer answers the final question: Is it done? It takes the reasoning layer’s blueprint and turns it into published content, schema updates, or distribution actions.
The fundamental error most teams make is automating the first and third layers while leaving the second one entirely to the human brain. Tracking is automated. Content generation is automated. But the complex, resource-intensive process of analyzing multi-dimensional data and engineering the right response? That’s still a person staring at a dashboard and scheduling a meeting.
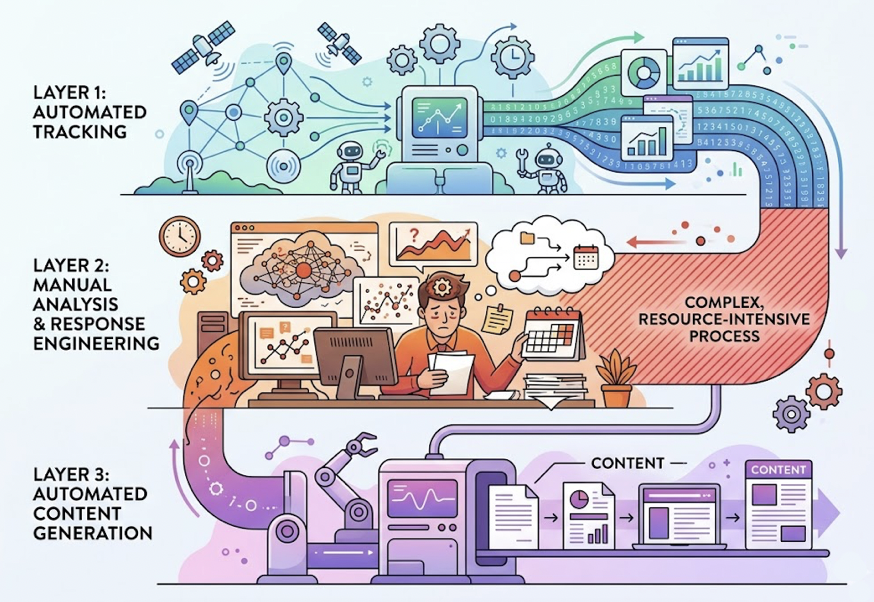
That missing middle is the bottleneck.
Tracking Layer: Where the AEO Agent Gets Its Eyes
Without accurate, multi-platform sensory input, the reasoning and execution layers are useless. Feed an agent incomplete visibility data, and it’ll execute a flawed strategy faster. Classic garbage in, garbage out.
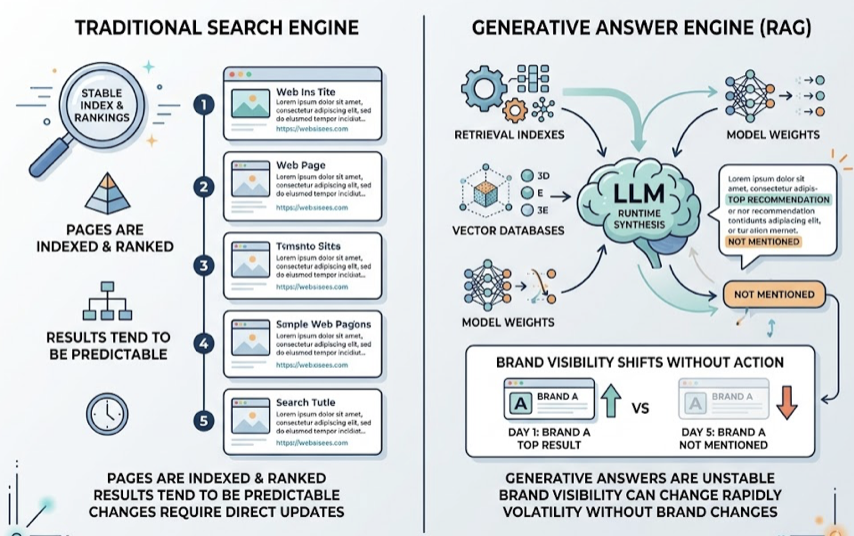
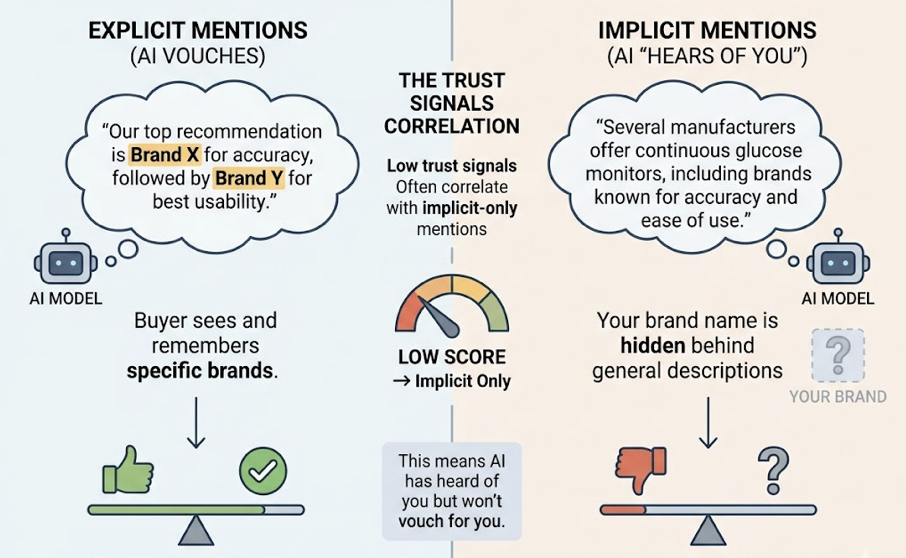
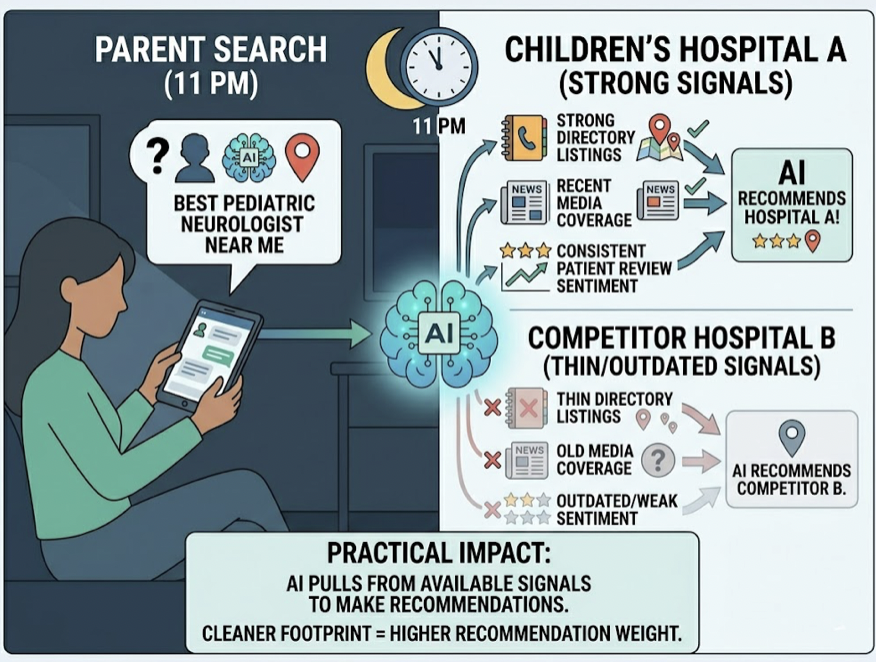
The first thing to internalize: traditional SEO metrics can’t power this layer. Domain authority, keyword rank, and organic CTR don’t measure whether ChatGPT is recommending your competitor instead of you. AEO tracking requires a different taxonomy: brand mentions, citation frequency, sentiment polarity, position within AI-generated lists, and conversion probability from AI referrals.
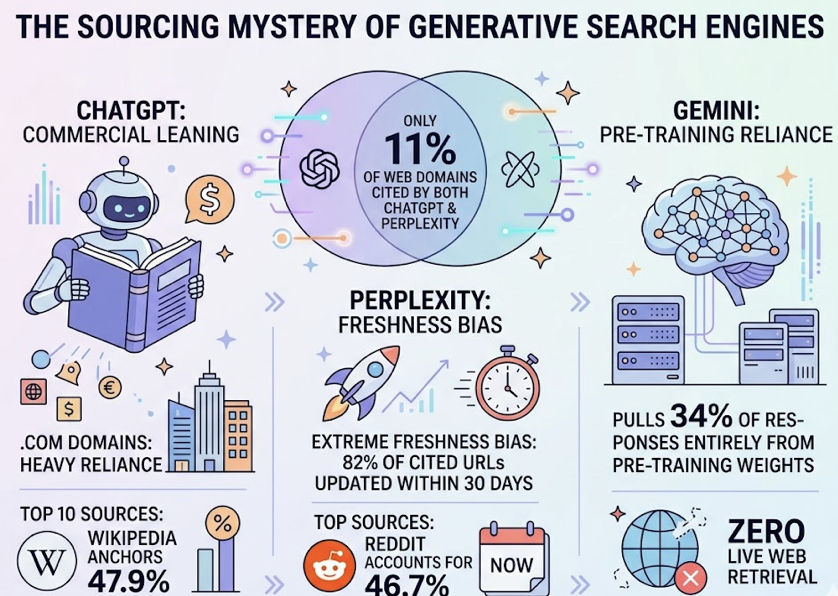
The second thing: a single-platform tracking strategy will fail. Research across 680 million AI citations found that only 11% of domains cited by ChatGPT are also cited by Perplexity. That means a brand can dominate one AI engine while being completely invisible on another.
Platform-specific behaviors make this worse. Perplexity averages roughly 21 citations per response and leans heavily on Reddit threads and niche forums. ChatGPT averages around 8 citations and prefers authoritative, encyclopedic sources. The tracking layer has to capture these differences or the reasoning layer makes decisions based on a distorted picture.
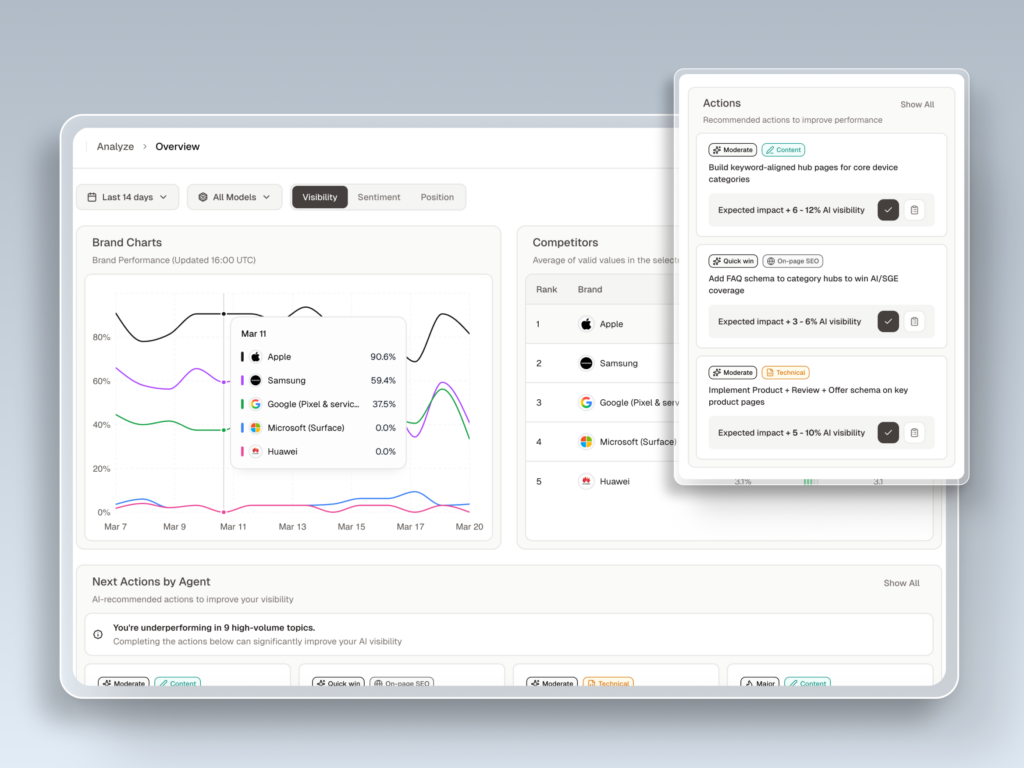
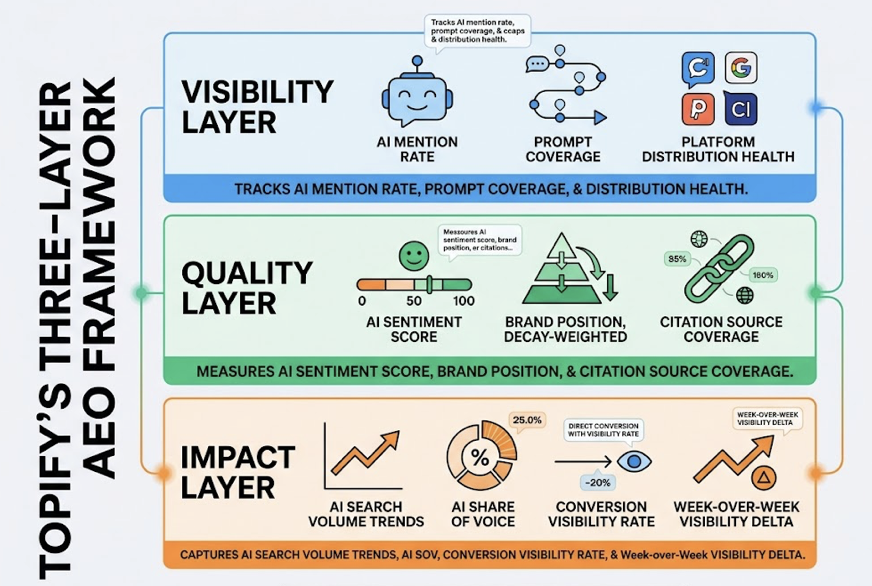
Topify addresses this by providing native tracking across ChatGPT, Gemini, Perplexity, Google AI Overviews, DeepSeek, Doubao, and Qwen. Its 7-metric framework captures Visibility (Share of Model), Position, Sentiment, Mentions, Intent, Volume, and Conversion Visibility Rate (CVR) simultaneously. That last metric, CVR, matters more than most teams think: AI-referred visitors convert at 4.4x to 23x the rate of organic search traffic, depending on the vertical. If your tracking layer can’t connect visibility to conversion probability, your CFO will never fund the program.
A fully integrated tracking layer continuously aggregates these data points across all relevant platforms. Only with that high-resolution input can the stack move to the hard part: automated reasoning.
Reasoning Layer: Where Data Becomes a Decision
This is the layer that separates a tool from an agent. Its job is to ingest tracking data and output a specific, actionable execution plan, without waiting for a human to schedule a meeting about it.
In most teams today, this layer is entirely manual. An analyst logs into the dashboard, exports data to a spreadsheet, cross-references it with competitor activity, and eventually convenes a strategy discussion. The research phase alone, identifying semantic angles, discovering citation gaps, mapping the competitive field, typically consumes about 70% of a content creator’s total workflow time. The actual writing takes a fraction of that.
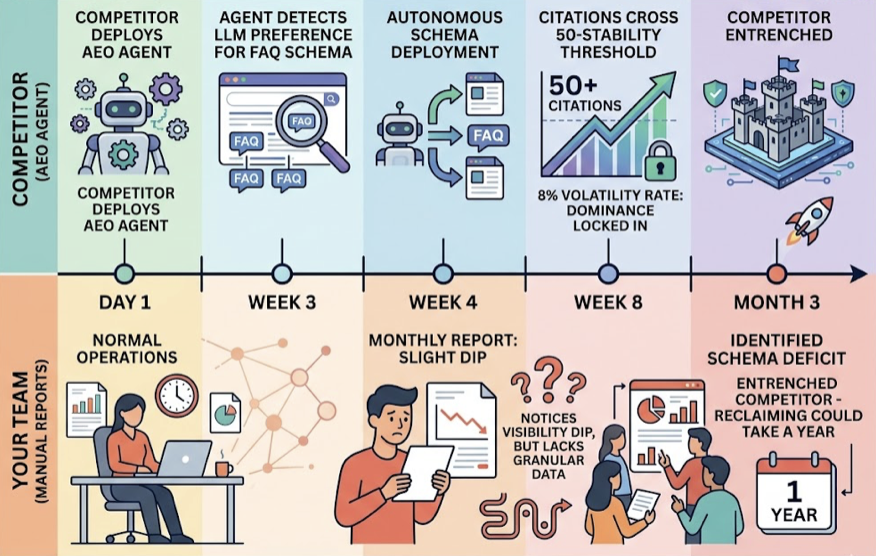
By the time the team has reasoned through the data and drafted a content brief, the generative engine’s citation preferences may have already shifted.
Here’s what automated reasoning looks like in practice. The tracking layer flags an anomaly: Brand X’s position on Perplexity for “enterprise cybersecurity solutions” dropped from #2 to #5. A human analyst could spend days querying Perplexity, testing hypotheses, and verifying sources. An automated reasoning layer parses the variables instantly.
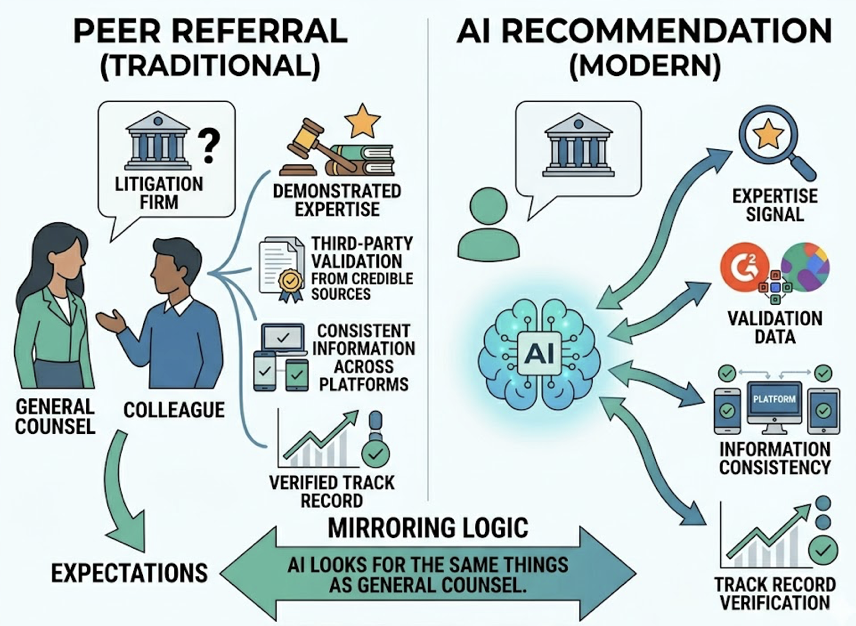
Using source analysis and competitor monitoring, the agent reverse-engineers Perplexity’s citation graph for that prompt cluster. It discovers that a competitor earned a mention in a new technical discussion on a niche subreddit, and Perplexity indexed it. This aligns with a broader pattern: 85% of brand mentions in AI search come from third-party pages, not the brand’s own domain. The reasoning layer identifies the causal link, then outputs a specific directive: produce a structured content asset targeting that third-party gap, formatted with FAQ schema to maximize algorithmic ingestion.
Topify’s Source Analysis feature powers this type of reasoning by identifying exactly which domains and URLs AI platforms are citing instead of your brand. Its Competitor Monitoring surfaces which rivals are gaining share and on which specific prompt clusters. Together, these features give the reasoning layer the context it needs to move from “something changed” to “here’s exactly what to do about it.”
That’s the difference between a dashboard and a brain.
Execution Layer: Where Strategy Becomes Content
The execution layer takes the reasoning layer’s blueprint and turns it into a published asset. In a traditional workflow, this means converting a strategy into a brief, routing it to a writer, passing it through editorial review, then handing it to a CMS admin for formatting and deployment. A standard blog post requires roughly 10 hours of labor per month to maintain through that process.
An integrated AEO agent stack collapses this into what the industry calls “one-click execution.” The reasoning layer has already identified the gap, defined the semantic targets, and specified the structural requirements. The execution layer generates content that’s natively engineered for LLM recommendation algorithms, not just human readers, because it has the full context from both upstream layers.
Topify’s One-Click Agent Execution works this way. You state a goal in plain English. The system, informed by the tracking and reasoning layers, proposes a strategy. You review it and deploy with a single click. The human role shifts from laborer to overseer.
But here’s the warning that matters most: execution without reasoning is a liability.
If you connect a generic AI content generator directly to your CMS without the guidance of a dedicated reasoning layer, you’re not building an agent. You’re building a machine that publishes the wrong content faster. Generic AI content is increasingly penalized by search and answer engines. What earns citations in AEO is “information gain,” original data, unique perspectives, and novel factual associations that don’t exist in the LLM’s training data. If your execution layer just rewrites what’s already on the internet, it’s mathematically impossible for it to capture a new citation.
Automation without reasoning accelerates failure. Automation governed by real-time data and causal logic is a competitive edge.
The Closed Loop: Why It All Falls Apart Without Feedback
The three layers only work as an agent if the output of execution flows back into tracking. Without that feedback loop, you’re guessing whether your actions worked.
In an open-loop system, a team publishes content and checks results three months later using disjointed metrics. There’s no automated connection between the action and the outcome. In a closed-loop AEO agent, the cycle is continuous:
- Execution Layer deploys a structured content asset targeting a specific citation gap on Gemini.
- Tracking Layer monitors Gemini’s output to verify whether the new asset was crawled, indexed, and cited.
- Tracking to Reasoning: the tracking layer quantifies the impact. Share of Model moved from 4% to 9%. CVR increased.
- Reasoning Layer registers the success, updates its heuristics about what works on Gemini, and refines the parameters for the next execution cycle.
That’s what makes it an agent: it learns from its own actions. A toolset waits for a human to connect the dots. An agent closes the loop automatically.
| System | Feedback Mechanism | Strategic Outcome |
|---|---|---|
| Open-loop (tool-based) | Manual data synthesis across platforms | High latency, wasted resources, guesswork |
| Closed-loop (agentic) | Automated execution-to-tracking feedback | Autonomous adaptation, measurable ROI |
Companies that implement closed-loop marketing architectures consistently report improved ROI predictability and sharper resource allocation. In AEO, where LLMs continuously update their citation preferences, a system that can’t learn from its own output is functionally obsolete.
Where to Start If Your Stack Is Still Duct-Taped Together
Don’t try to automate all three layers at once. That’s how you get architectural collapse. Build progressively.
Phase 1: Fortify the Tracking Layer. Start by defining 30 to 50 high-intent prompts relevant to your category. Map your performance across all key metrics and platforms simultaneously. Topify’s Basic tier covers 100 tracked prompts across multiple AI engines for $99/month, which is enough to establish a baseline without enterprise-level spend.
Phase 2: Formalize the Reasoning Logic. Once tracking data is flowing, manually simulate the reasoning process. When the tracker flags a visibility drop, use source analysis and competitor monitoring to reverse-engineer the cause. Document the decision rules: “If Perplexity position drops, check for new third-party citations the competitor earned.” These heuristics become the parameters that govern automation later.
Phase 3: Connect Execution and Close the Loop. Only when tracking is reliable and reasoning rules are proven should you enable automated execution. Run two full cycles under human supervision: define a target, let the reasoning engine propose a strategy, execute via one-click, then watch the tracking layer for measurable impact over 2 to 4 weeks. Once the data flows from tracking to reasoning to execution and back to tracking without manual intervention, you’ve built an AEO agent.
Conclusion
An AEO agent isn’t a product you buy. It’s an architecture you build. Three layers, each with a strict job: tracking senses the environment, reasoning turns data into decisions, execution deploys the fix. And the closed loop feeds results back into the cycle so the system gets smarter with every iteration.
Most teams today have the first and third layers covered. The reasoning layer, the one that actually determines what to do, is still a human bottleneck. Formalizing that layer, whether through manual heuristics or automated reasoning engines, is the single highest-leverage move a marketing team can make in 2026. Start with the tracking layer. Get the data right. The rest follows.
FAQ
Q: What is an AEO agent stack?
A: It’s a three-layer architecture designed to maximize brand visibility in AI search platforms like ChatGPT, Perplexity, and Gemini. The Tracking Layer monitors AI outputs and citations. The Reasoning Layer analyzes data and formulates strategy. The Execution Layer generates and deploys optimized content. These layers operate in a closed loop, so the system adapts to algorithmic changes without manual data transfers.
Q: How is an AEO agent different from AEO tools?
A: An AEO tool performs a single function, like tracking mentions or generating content. An AEO agent links those functions together through automated reasoning. With tools, a human bridges every gap. With an agent, data flows from observation to strategy to action to measurement in a continuous cycle.
Q: What does the tracking layer need to measure?
A: At minimum: Visibility Rate (how often your brand appears), Position (where you rank in the AI’s list), Sentiment (how the AI frames your brand), Citation Sources (which third-party domains the AI references), and CVR (the probability an AI mention drives a conversion). Coverage has to span multiple platforms, since only 11% of cited domains overlap between ChatGPT and Perplexity.
Q: Can I build an AEO agent stack without coding?
A: Yes. Platforms like Topify and Conductor’s AgentStack provide pre-built architectures that integrate tracking, reasoning, and execution into a unified interface. One-click execution lets you translate tracking data into deployed content using plain-English commands, no API work or prompt engineering required.