Most model updates don’t require marketers to change anything. Claude 4.7 is different.
Released on April 16, 2026, Claude Opus 4.7 introduced a “Hybrid Reasoning” architecture that doesn’t just generate smarter outputs. It changes how AI systems evaluate, cross-reference, and ultimately recommend brands to users. If your content strategy was built around Claude 4.5 or 4.6 behaviors, some of those assumptions no longer hold.
Here’s what actually shifted, and what it means for your team.
The Core Upgrade: From Generative to Hybrid Reasoning
Claude 4.5 and 4.6 were generative models. They produced text by predicting what should come next. Claude 4.7 introduces what Anthropic calls “Adaptive Thinking,” a unified architecture where reasoning runs inside the model rather than as a separate post-processing step.
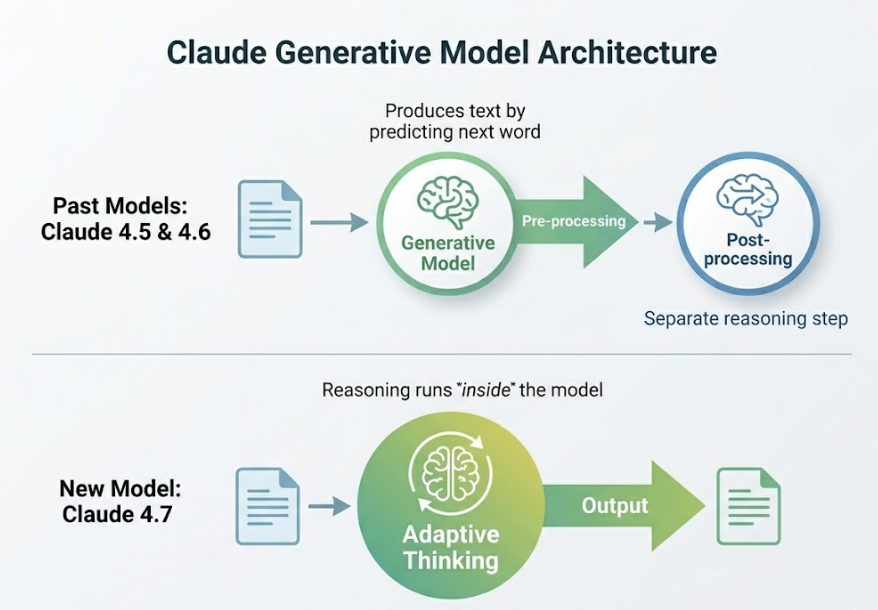
In practice, this means Claude 4.7 can toggle between fast responses for simple queries and deep, multi-step reasoning for complex ones. The model doesn’t just write an answer. It checks its own logic before delivering it.
For marketers, the downstream effect is significant: AI outputs are now more consistent, better at following complex briefs, and less prone to generating “confident but wrong” content.
| Feature | Claude 4.5/4.6 | Claude 4.7 |
|---|---|---|
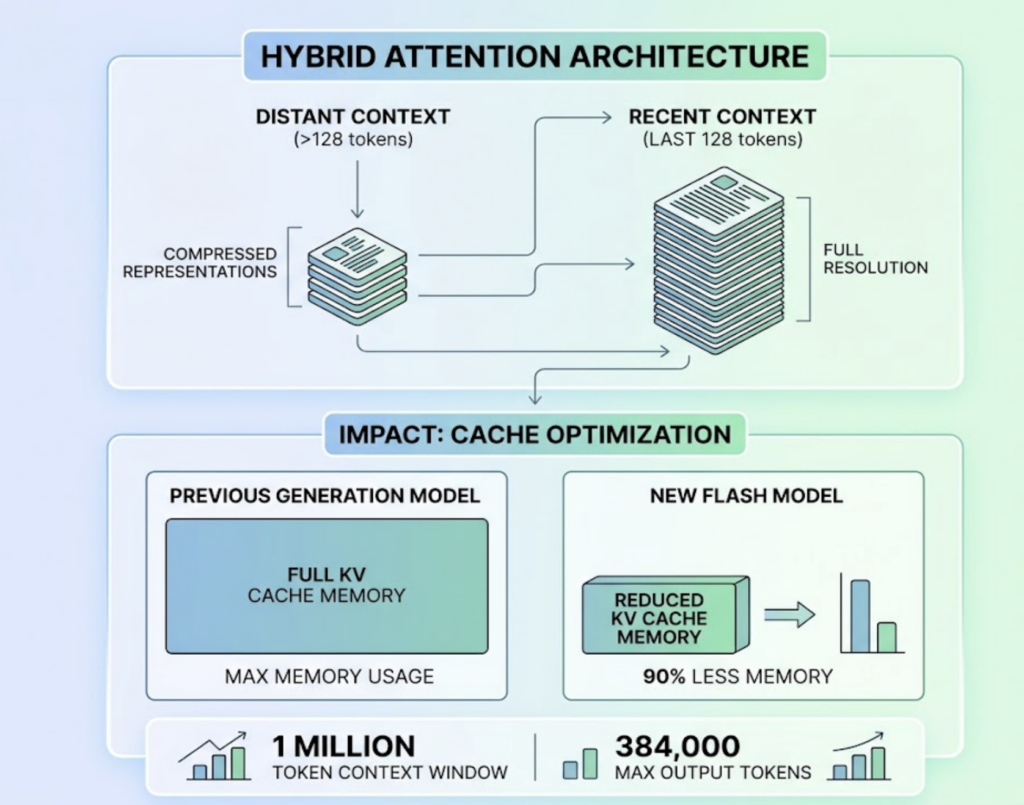
| Context Window | 200,000 tokens (4.5) / 1M (4.6) | 1,000,000 tokens |
| Reasoning Architecture | Generative | Hybrid (Adaptive Thinking) |
| Instruction Following | Interprets “spirit” of prompt | Literal, precise |
| Self-Verification | Manual (prompt-required) | Built-in at “xhigh” effort level |
| Visual Resolution | ~1.15 megapixels | ~3.75 megapixels |
The context window alone is worth noting. Claude 4.7 carries 1 million tokens into every session. That’s enough to load an entire brand content archive and maintain stylistic consistency across a full campaign, without resetting or chunking.
Instruction Following Got More Literal. That’s a Double-Edged Change.
This is the update most marketing teams will feel first.
Claude 4.5 would often interpret the “spirit” of an ambiguous prompt. Ask for “a casual product description” and it would reasonably infer your tone preferences from context. Claude 4.7 doesn’t do that. It follows what you wrote, not what you meant.
That’s not a flaw. It’s a design choice that removes a layer of unpredictability from high-volume automation.
But it does require prompt audits. Prompts written for 4.5 often rely on the model’s ability to fill in unstated assumptions. Those prompts may return “flatter” results in 4.7: technically correct, creatively inert.
The fix is straightforward. Use XML tags to separate instructions from content. Provide a positive example and a negative example. Specify formatting explicitly. Claude 4.7 rewards precision and returns proportionally better outputs when it gets it.
This is a one-time adjustment. Teams that update their prompt libraries now will build a more stable, repeatable content production system in the process.
Visual Reasoning Jumped 3x. Here’s Where That Matters.
Claude 4.5 processed images at roughly 1.15 megapixels. Claude 4.7 handles up to 3.75 megapixels, a 3x increase in resolution support.
The XBOW visual acuity benchmark reflects this directly: Claude 4.7 scored 98.5% versus 54.5% for Claude 4.6, a 44-point gap.
For marketing workflows, this unlocks three practical capabilities:
Creative asset auditing: You can now submit full Figma frames or high-resolution web screenshots for layout review. Claude 4.7 can catch small text legibility issues, spacing inconsistencies, and hierarchy problems that earlier models would miss.
Dense document extraction: Complex charts, multi-series graphs, and financial tables can be accurately read and summarized. This is particularly useful for competitive intelligence reports or media performance reviews.
Visual brand consistency checks: The model can compare a draft asset against a brand style guide with enough precision to flag icon placement and logo sizing that fall outside spec.
None of this replaces a human designer. But it meaningfully reduces the manual review loop for teams producing high volumes of creative assets.
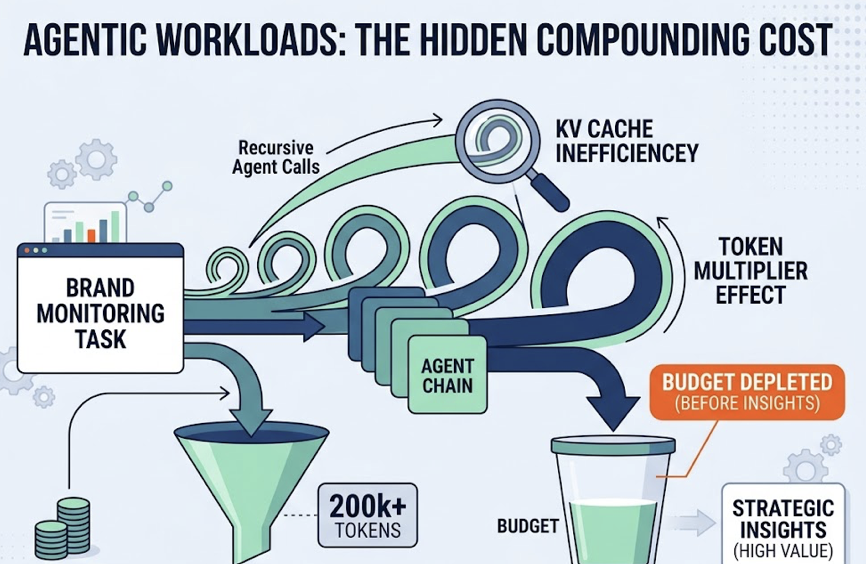
The Cost Reality: Same Price, Potentially Higher Bill
Anthropic kept the sticker price unchanged at $5/$25 per million input/output tokens for Opus 4.7. The catch is a redesigned tokenizer.
The new tokenizer was built to improve multilingual handling for non-Latin scripts. As a side effect, the same volume of English text and code now tokenizes at roughly 1.1x to 1.35x the rate of the 4.5 era tokenizer. That’s an effective cost increase of 10% to 35% per task, without any change to the listed rate.
For teams running high-volume content automation, that gap adds up.
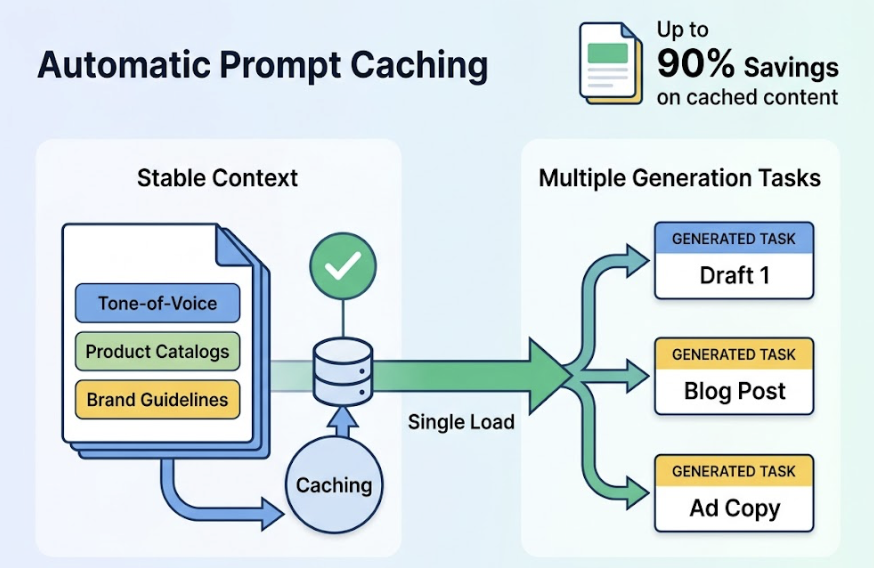
The mitigating factor is Automatic Prompt Caching, introduced in early 2026. You can now cache large context blocks automatically as the conversation grows: tone-of-voice documents, product catalogs, brand guidelines. Anthropic reports up to 90% savings on cached content. Teams that structure their workflows to load stable brand context once, then run multiple generation tasks against it, can offset much of the tokenizer cost increase.
How Claude 4.7 Changes Brand Recommendations in AI Search
This is where the model upgrade stops being a tool question and becomes a visibility question.
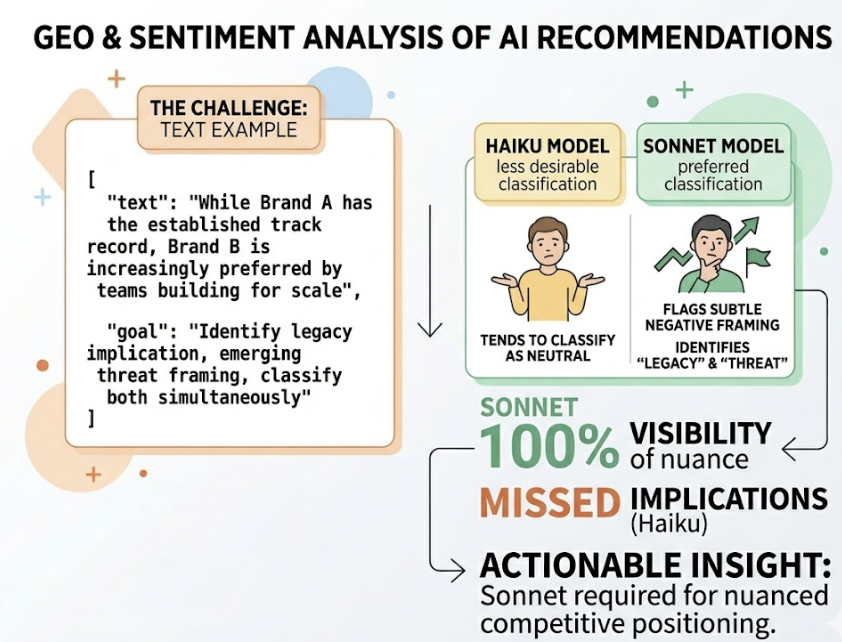
Claude 4.7 carries a higher “honesty” profile than its predecessors. It’s less prone to sycophancy: agreeing with users or making confident brand recommendations without strong third-party evidence. The model requires meaningful citation coverage before it will consistently recommend a brand in a professional context.
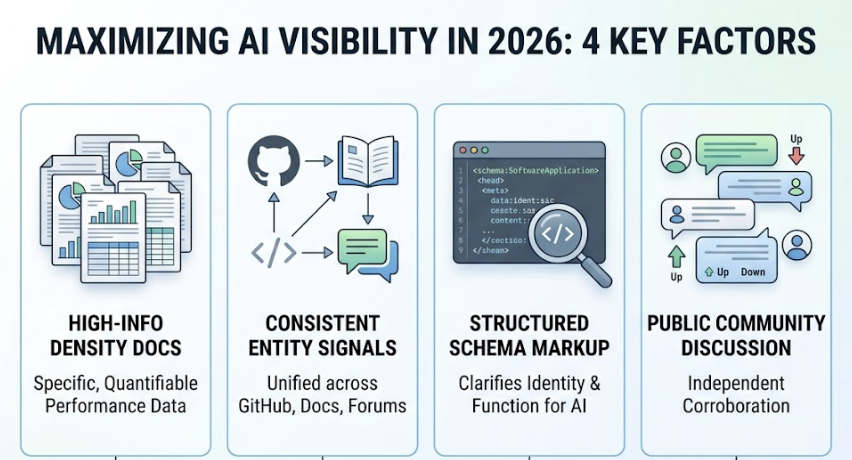
In concrete terms, this means brands that were “riding” on weak AI visibility are now more exposed. Claude 4.7 cross-references third-party sources more rigorously. If your brand lacks coverage on authoritative forums, review platforms, or industry publications, it becomes harder for the model to include you confidently in a recommendation.
That’s not a bug. It’s what “less hallucination” actually looks like from the brand side.
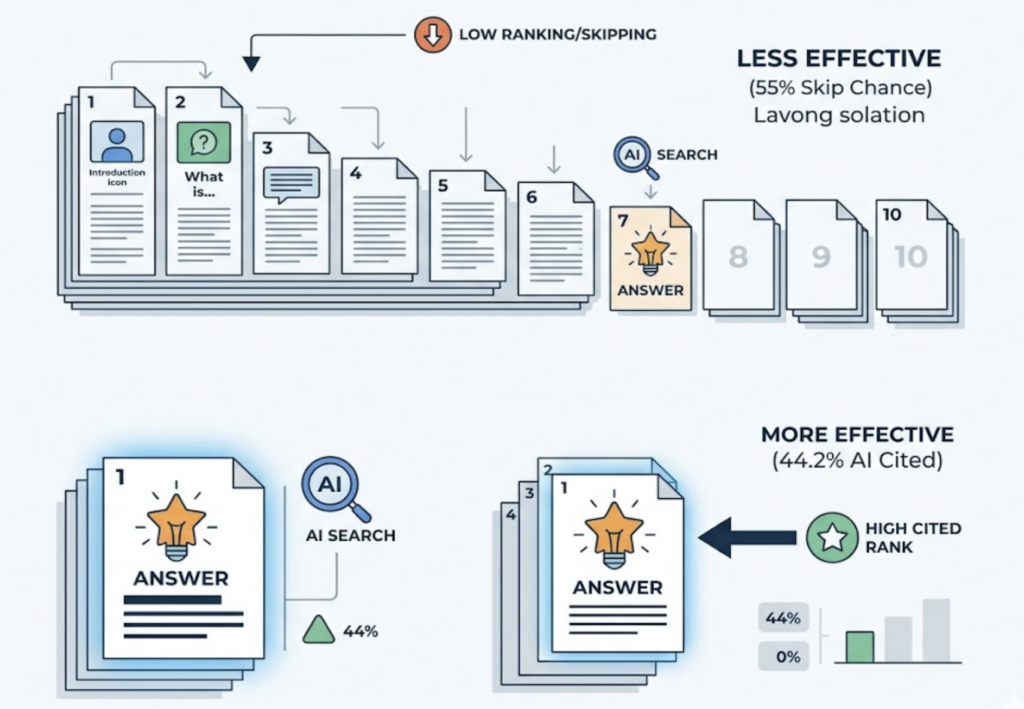
Research suggests that 82% to 85% of AI citations come from third-party media, review sites, and community platforms, not from a brand’s own website. Claude 4.7’s improved reasoning means it relies on that third-party signal pool even more heavily than earlier versions.
3 Things Marketers Should Adjust After Claude 4.7
1. Audit your high-value prompt library.
Prompts written for Claude 4.5 or 4.6 often depended on the model’s ability to “read between the lines.” Run your top 10 most-used automation prompts through 4.7 and compare outputs. Look specifically for where creative flair has been replaced by mechanical compliance. Add explicit tone guidance, use XML tags, and include formatting examples.
2. Check which sources Claude 4.7 cites for your category.
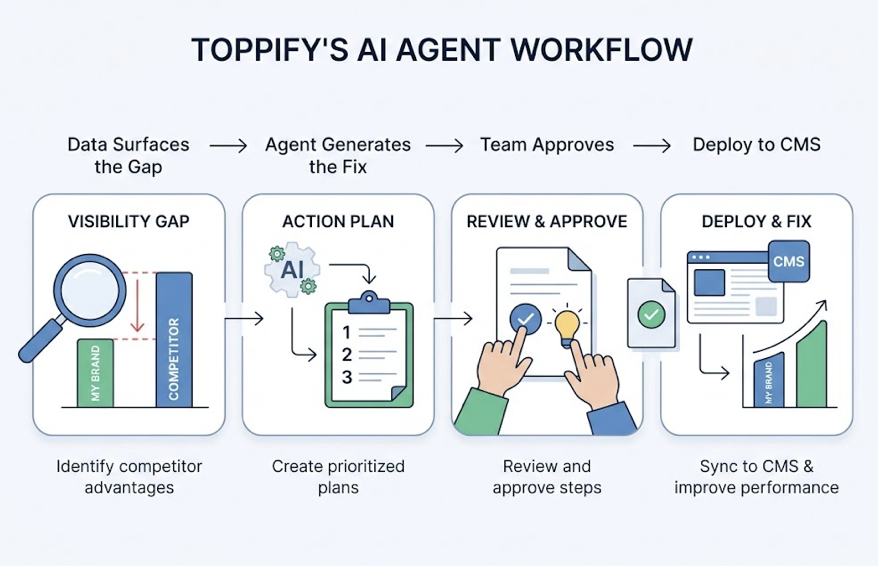
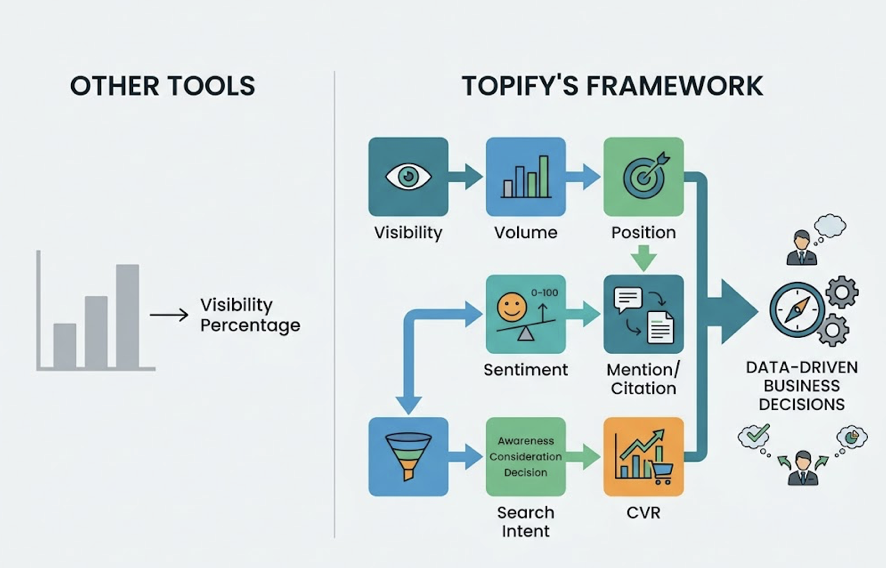
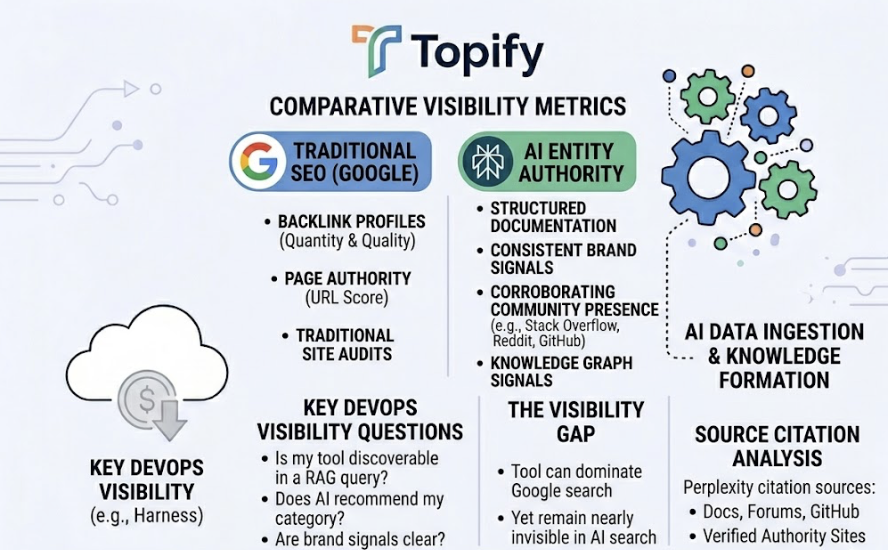
Use a GEO platform like Topify to reverse-engineer the sources Claude and other AI platforms are pulling when they discuss your brand’s product category. If competitors are being cited from sources you’re absent from (specific Reddit threads, niche review sites, industry blogs), that’s your earned media gap. Topify’s Source Analysis feature maps the exact URLs driving AI perception of your brand, so you can prioritize where to publish next.
3. Set up visibility monitoring before the next model update.
Claude 4.7 won’t be the last significant release this year. Each major update can shift “Model Drift,” where AI preference for a brand changes overnight due to updated internal weights. Topify’s Visibility Tracking monitors your brand’s mention rate across ChatGPT, Claude, Gemini, and Perplexity simultaneously, and flags unusual shifts in Sentiment Velocity before they affect conversion. Weekly monitoring is the minimum for a brand category with active competitors.
Is It Worth Upgrading? The Honest Take
Not every use case benefits equally from Claude 4.7.
| Use Case | Recommended Model | Rationale |
|---|---|---|
| High-volume content drafts | Sonnet 4.6 | Better speed-to-cost ratio |
| Complex campaign briefs | Opus 4.7 | Agentic persistence, consistent instruction following |
| Brand sentiment monitoring | Opus 4.7 | Superior reasoning for nuanced analysis |
| Deep document QA (100k+ tokens) | Opus 4.6 | Better recall accuracy above 100k tokens |
| Competitive SEO research | Opus 4.7 | Loop resistance and tool-calling reliability |
For most marketing teams, a hybrid approach works best. Use Opus 4.7 for strategic tasks: research briefs, campaign architecture, and brand voice analysis. Use Sonnet 4.6 for execution-heavy volume work like social copy and email sequences.
That’s not a compromise. It’s actually how Anthropic intends the model family to be used.
Conclusion
Claude 4.7 is not a minor iteration. The shift to Hybrid Reasoning, the 3x visual acuity improvement, and the stricter instruction fidelity represent a meaningful change in how AI processes and evaluates marketing inputs.
The more important implication is at the brand recommendation level. A model that hallucinates less and cross-references more aggressively raises the bar for what it takes to appear in an AI-generated recommendation. That’s a GEO challenge as much as it is a content challenge.
Brands that track their AI visibility systematically, and adjust their earned media strategy based on what the model is actually citing, are the ones that will hold their position as the reasoning quality of these models continues to improve. Tools like Topify exist precisely to make that monitoring systematic rather than reactive.
The window to build that foundation before the next major release is now.
FAQ
Is Claude 4.7 significantly better than 4.5 for content marketing?
Claude Opus 4.7 provides a meaningful upgrade in consistency and adherence to complex briefs. Its increased literalness may require more detailed prompting to achieve the creative range that was easier to access in 4.5. For marketers managing long-form content or complex multi-session campaigns, 4.7’s agentic persistence and 1M token context window make it the stronger choice for maintaining coherence across extended workflows.
Does Claude 4.7 change how AI platforms recommend brands?
Yes. Claude 4.7 has a higher “honesty” profile and better cross-referencing capability, which means it requires stronger third-party validation before confidently recommending a brand. Brands that were benefiting from weaker AI citation logic in earlier models may see their visibility shift.
Should I update my prompts after switching to Claude 4.7?
Yes. Prompts written for 4.5 or 4.6 often assumed the model would interpret unstated intent. Claude 4.7 follows instructions literally. Audit your prompt library and add explicit formatting requirements, XML tags, and positive/negative examples where you relied on implied context before.
How do I measure if Claude 4.7 affects my brand’s AI visibility?
Standard SEO tools are not built to track AI outputs. Use a GEO-specific platform like Topify to monitor your Share of Sentiment and brand mention rate across multiple AI platforms. Tracking Sentiment Velocity during the weeks following a major model release like Claude 4.7 is particularly important for catching early drift before it compounds.