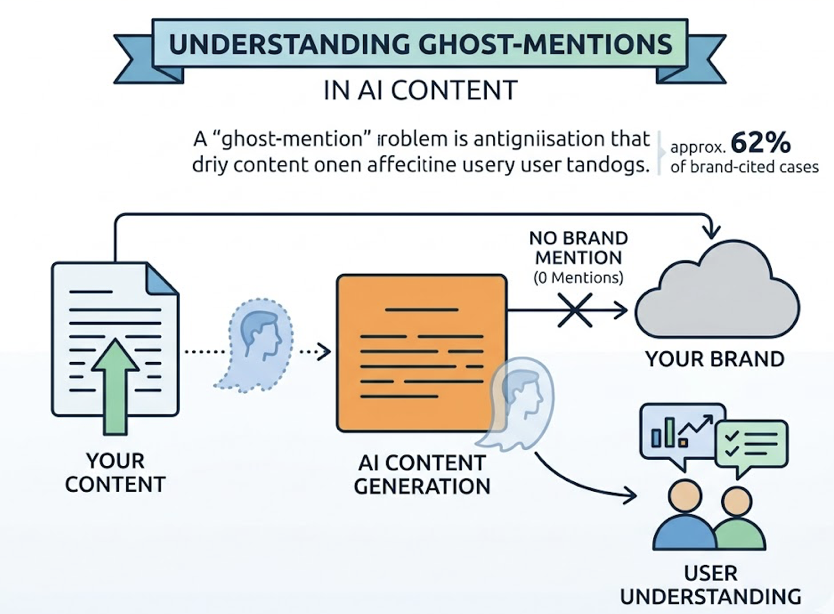
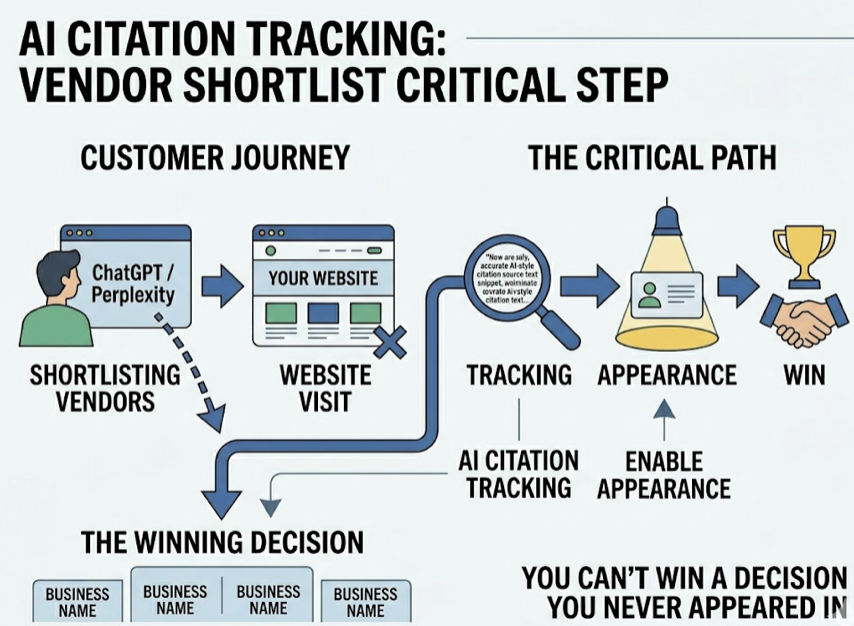
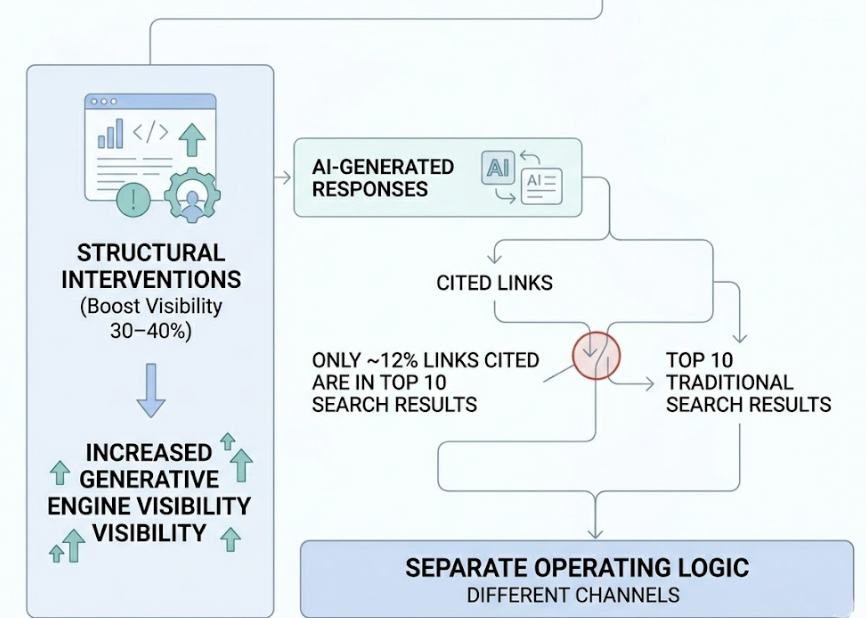
Your Google rankings are solid. Your content calendar is consistent. Your domain authority keeps climbing. Then a potential customer opens ChatGPT, types “best tool for [your category],” and gets a confident five-item list. Your brand isn’t on it.
That’s not an SEO problem. It’s a signal that SEO and AI search operate on different logic entirely. And most marketers don’t realize there are now two distinct disciplines sitting above SEO: AEO and GEO. They’re not synonyms, and confusing them leads to wasted effort.
Three Terms, Three Different Jobs
The fastest way to understand these three disciplines is by what each one is actually trying to accomplish, not how they’re defined in a blog post.
| Dimension | SEO | GEO | AEO |
|---|---|---|---|
| Target Platform | Google, Bing, Yahoo | ChatGPT, Gemini, Perplexity, Claude | Voice assistants, Featured Snippets, AI Overviews |
| Optimization Object | Webpages and domain authority | Citations, brand mentions, narrative synthesis | Direct answers, “Position Zero,” extractable facts |
| Primary Logic | Lexical and technical relevance | Recommendation and brand authority | Immediate information extraction |
| Success Metric | Organic traffic, SERP rank, CTR | Citation frequency, Share of Model, brand sentiment | Featured answer wins, voice search selection, zero-click impressions |
These aren’t competing strategies. They’re layers. SEO gets you found during deep research. AEO makes you the immediate answer to a direct question. GEO makes you the trusted recommendation inside a longer AI-generated response.
Get the layer wrong and you’re optimizing for an outcome you weren’t even targeting.
SEO Is Still Alive. Just Not in the Room It Used to Own.
Traditional SEO hasn’t died. But its territory has shrunk.
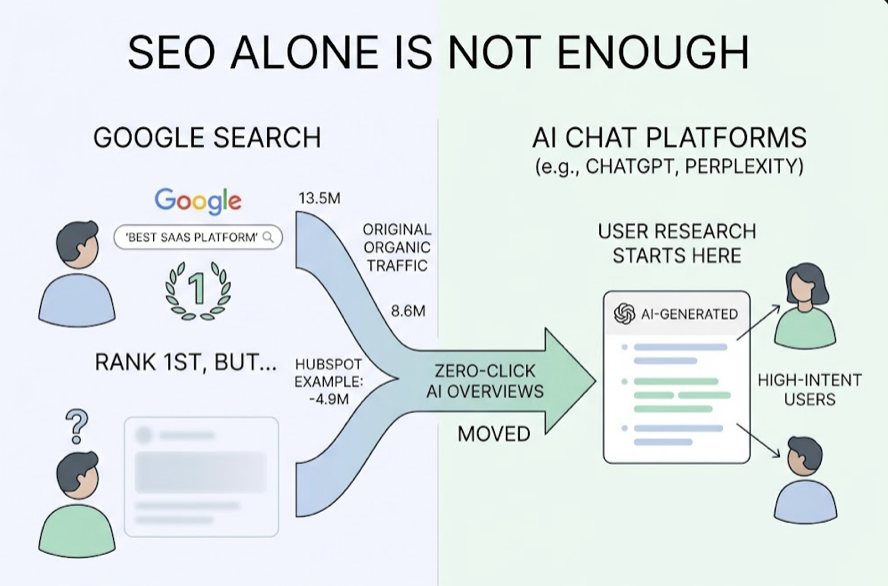
By late 2025, AI Overviews were appearing on nearly 49.92% of all search results, pushing traditional organic listings down the page by an average of 1,562 to 1,630 pixels. For positions 1 through 5, click-through rates dropped 58% to 61%. Before AI Overviews, position 1 historically captured around 28% of clicks. That number has been cut to single digits for informational queries.
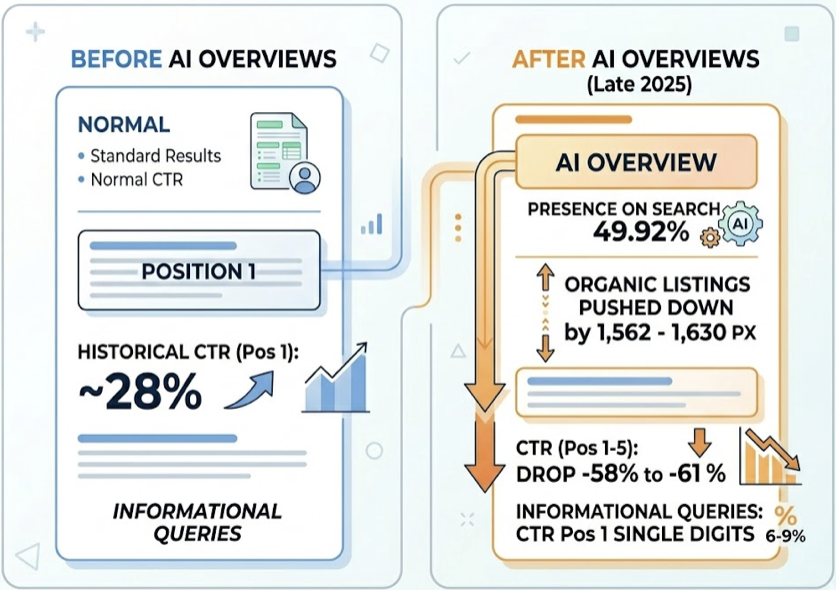
Zero-click searches climbed from 56% to 69% between 2024 and 2025. Users are finding sufficient answers in AI-generated summaries and stopping there.
SEO still matters. But its role has shifted. In 2026, ranking in the top 10 isn’t the final destination. It’s the entry requirement to be considered as a source for AI citation. About 92.36% of AI Overview citations come from domains already ranking in the top 10. If you’re not ranking, you’re not even in the pool.
That’s the boundary. SEO gets you into the pool. GEO and AEO determine whether you get picked.
GEO Is What Happens When AI Generates the Answer
Generative Engine Optimization works differently from anything SEO practitioners are used to.
In a traditional SEO model, the machine indexes your page and ranks the URL. In a GEO model, the AI doesn’t send users to your page. It reads a passage, evaluates its credibility against other sources, and writes your brand into a synthesized response. The “win” isn’t a click. It’s a citation, a mention, or a narrative inclusion.
Here’s what makes GEO operationally different:
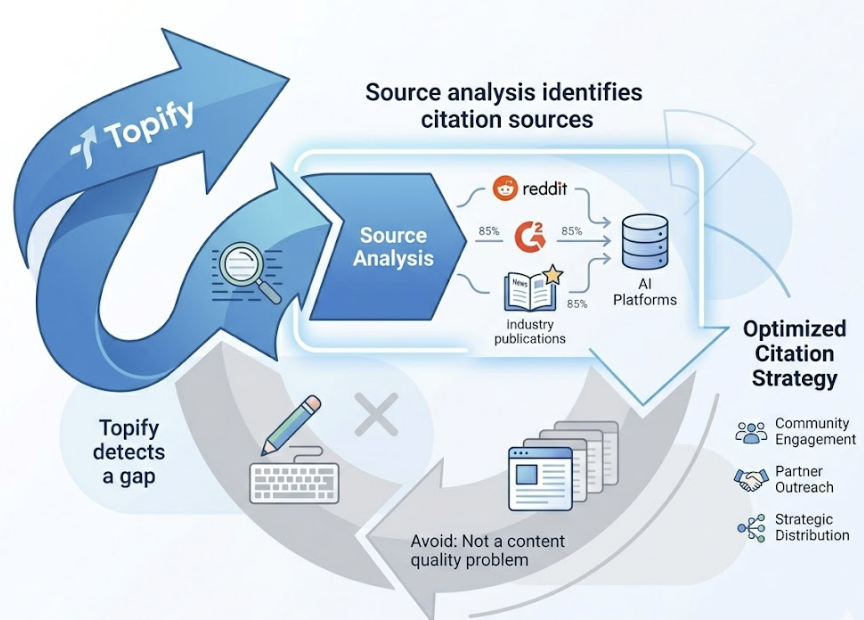
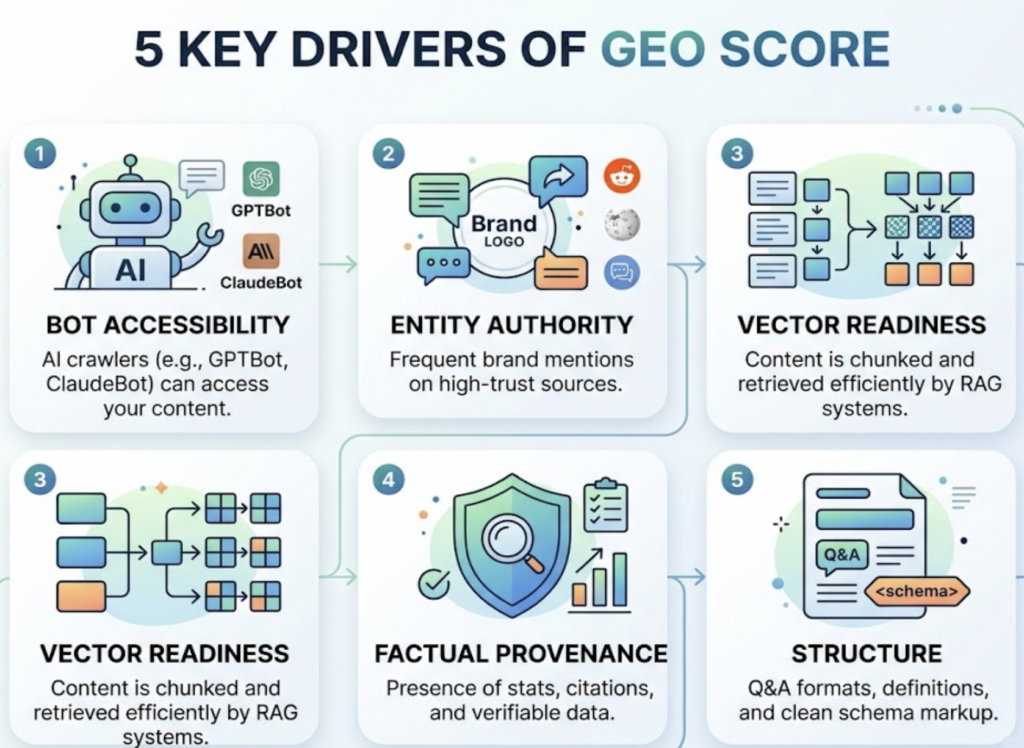
Entity consistency beats keyword density. AI systems don’t see websites; they recognize entities. Your brand name, description, service category, and positioning need to be identical across every surface the AI encounters: your blog, LinkedIn, Reddit, G2, industry publications. Inconsistency fragments the AI’s understanding of what you are and breaks the trust required for citation.
Structured content gets cited 2.8 times more often. Clear headings, bullet lists, and comparison tables reduce what researchers call “information friction.” An AI model parsing your content to form a response prefers content that’s already organized for extraction.
Third-party mentions drive model confidence. A Princeton study found that brand search volume has a 0.334 correlation with model confidence in recommendations. GEO isn’t just an on-page strategy. It’s an ecosystem play. Earned media, community engagement on Reddit and Quora, and consistent third-party reviews all feed the AI’s recognition logic.
GEO is also probabilistic. You’re not winning a single slot. You’re increasing the likelihood that your brand appears somewhere in a longer response, alongside competitors, when users ask complex multi-step questions.
AEO Isn’t GEO with a New Name
This is where most marketers lose the thread.
AEO, Answer Engine Optimization, has the same target audience as GEO (AI-mediated queries) but a completely different goal. GEO wants your brand to be the recommendation. AEO wants your content to be the answer.
That’s a different optimization target entirely.
AEO is binary. You either win the answer slot, the featured snippet, the voice assistant response, or you lose it. There’s no partial credit. It’s designed for direct factual queries: “What is AEO?” “How does [product category] work?” “What’s the difference between X and Y?”
The content requirements reflect this:
- Answer placement in the first 40-60 words. AI systems extracting a direct answer don’t scroll. The answer needs to be in the opening of the section, not buried three paragraphs in.
- Schema markup for extraction signals. FAQPage and HowTo schema explicitly tell machines where the answer lives.
- Simpler sentence structures. A Flesch readability score of 60-70 reduces the risk of AI models misinterpreting context during summarization.
AEO targets voice assistants (Alexa, Siri), Google’s featured answer boxes, and the zero-click response at the top of an AI Overview. GEO targets ChatGPT, Gemini, and Perplexity when users are doing multi-step conversational research.
Different platform. Different query type. Different content strategy.
Where They Overlap and Where They Don’t
All three disciplines share a technical foundation. Fast load speeds, mobile responsiveness, and strong E-E-A-T signals (Experience, Expertise, Authoritativeness, Trustworthiness) are table stakes across the board.
The divergence starts in how you research, what you produce, and how you measure results.
| Operation | SEO Focus | GEO Focus | AEO Focus |
|---|---|---|---|
| Research | Keyword volume and difficulty | Conversational prompts | Question intent: How, Why, What |
| Content | Page-level depth | Passage-level synthesis | Concise fact extraction |
| Technical | Site speed, XML sitemaps | Robots.txt / LLMs.txt access | FAQ / HowTo schema |
| Monitoring | Google Search Console rankings | AI citation frequency | Answer slot ownership |
| Authority | Backlinks, domain rating | Third-party reviews, entity mentions | Niche expertise, featured snippets |
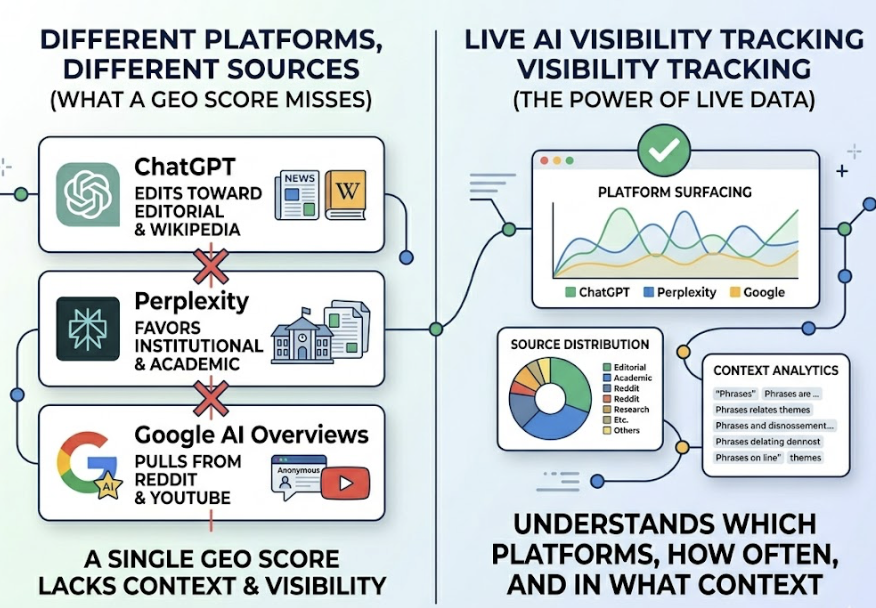
The critical shift is in monitoring. SEO results are visible in Google Search Console. GEO and AEO performance happens in the “black box” of AI models. You don’t see it in your analytics unless you’re explicitly tracking it.
80% of LLM citations come from sources that don’t rank in the top 100 for the original keyword. That statistic matters because it means GEO and SEO authority are decoupled. You can rank on page one of Google and still be invisible to ChatGPT. You can be cited frequently by Perplexity and barely appear in Google’s top 50.
These are different ecosystems, even when they intersect.
What This Means for Your 2026 Strategy
The right allocation depends on where your audience’s decision-making process actually happens.
If your category’s users still rely primarily on Google for research, SEO remains the priority. But ignoring GEO is a compounding risk: the more queries shift to conversational AI, the more invisible you become to users in the research phase, even while your Google rankings hold steady.
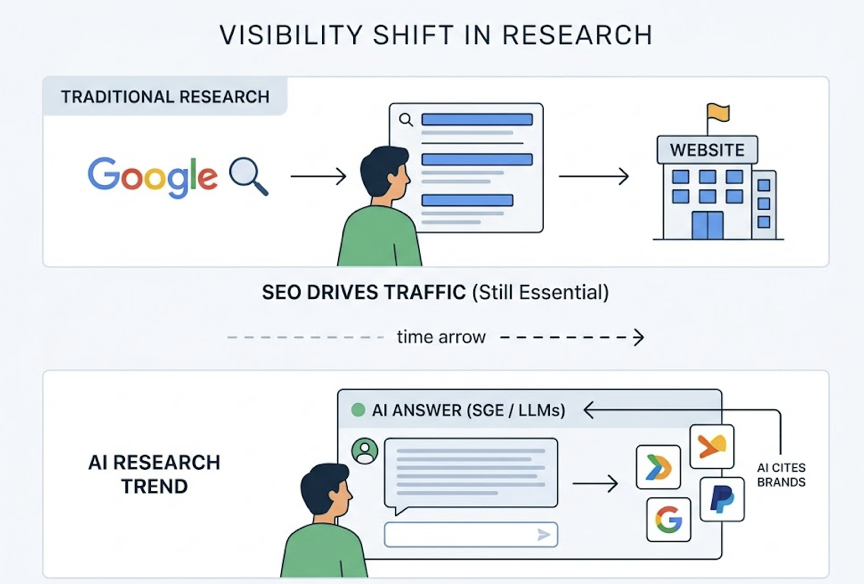
If your category is in SaaS, B2B, or complex e-commerce, AEO and GEO are no longer experimental channels. They’re core brand visibility strategy. Visitors arriving from AI recommendations convert at 14.2%, compared to the 2.8% benchmark for traditional organic traffic. That conversion gap alone justifies the resource allocation.
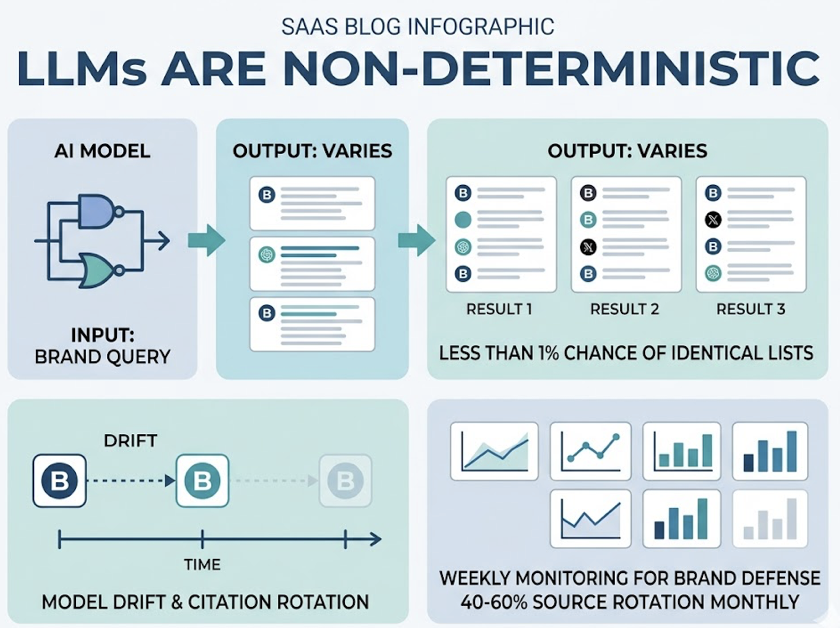
The challenge is measurement. Traditional analytics tools weren’t built to track AI citations. There are no impressions logged when ChatGPT mentions your brand. No click recorded when Gemini recommends your product. The same brand can experience a 46-fold gap in citation rates across different AI platforms, meaning high visibility on one model and near-zero visibility on another, with no signal of that gap in your existing dashboards.
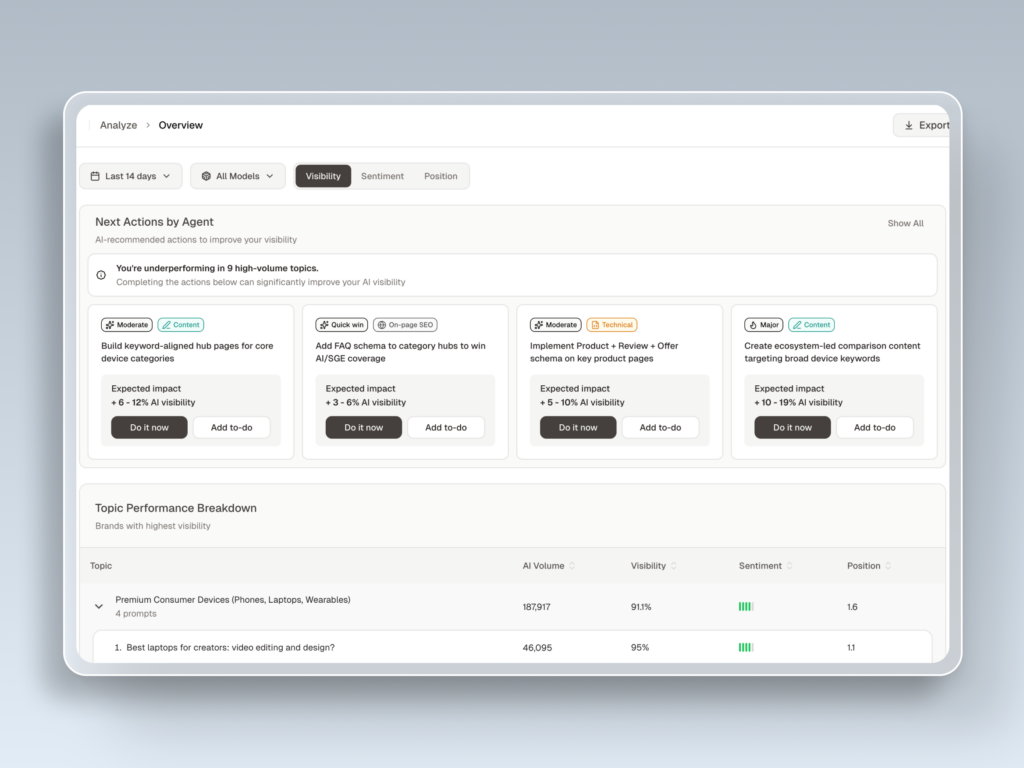
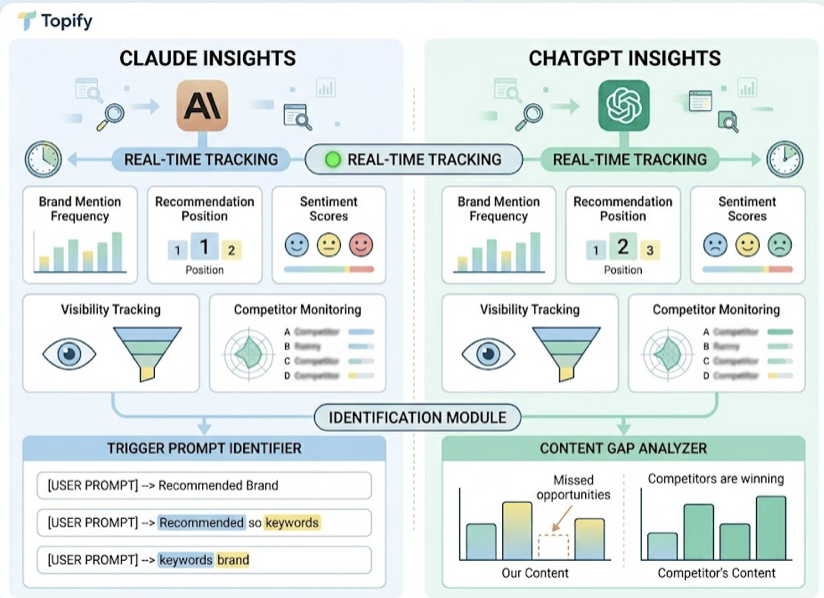
Topify addresses this directly by monitoring brand presence across ChatGPT, Perplexity, Gemini, Claude, and DeepSeek simultaneously. It tracks the seven metrics that matter for AI visibility: visibility, sentiment, position, volume, mentions, intent, and Conversion Visibility Rate (CVR). When the system identifies an answer gap, a scenario where a competitor is being recommended and your brand is invisible, it can surface the specific sources the AI is using to form that response and flag where the citation chain breaks down.
For teams that have been optimizing for SEO alone, this level of visibility is genuinely new information. It answers the question your current toolset can’t: not “how does Google see us,” but “what does AI say about us, and why?”
Conclusion
SEO, GEO, and AEO aren’t three names for the same discipline. They target different platforms, serve different query types, and require different operational focus. Treating them as interchangeable is how brands end up with strong Google rankings and zero presence in AI-generated recommendations.
In 2026, the marketers with the clearest path forward aren’t abandoning SEO. They’re building the two layers above it. Start by understanding which of your audience’s queries are already being resolved by AI, then map those to the discipline that governs that answer slot. The brands winning in AI search aren’t doing more SEO. They’re doing a different kind of work entirely.
FAQ
Q: Is AEO just another word for GEO?
A: No. Both target AI-mediated queries, but AEO focuses on providing the answer itself through direct extraction, while GEO focuses on earning brand mentions within a synthesized narrative. AEO targets voice assistants and featured snippets. GEO targets LLM-driven chat and summaries. The content format, target platform, and success criteria are all different.
Q: Do I need to choose one or run all three?
A: The modern strategy runs all three simultaneously. They’re layers, not alternatives. SEO builds the trust foundation and keeps you in the citation pool for AI Overviews. AEO captures users seeking direct answers. GEO captures users engaged in multi-step conversational research. Skipping any layer creates a visibility gap somewhere in the user journey.
Q: How do I know if my brand shows up in AI answers?
A: Standard analytics won’t tell you. AI citations don’t generate trackable clicks or impressions in Google Search Console. You need a tool built specifically to run automated simulations across LLM APIs and record brand mentions, sentiment, and citation frequency. Platforms like Topify track this across multiple AI models simultaneously and surface the sources driving or blocking your AI visibility.
Q: My SEO rankings are strong. Does that mean my GEO is strong too?
A: Not necessarily. While about 92.36% of AI Overview citations come from top-10 domains, general LLM citation logic is more decoupled from traditional rankings. Research shows 80% of LLM citations come from sources that don’t rank in the top 100 for the original keyword. Strong SEO authority is a useful signal, but it doesn’t guarantee AI visibility across ChatGPT, Gemini, or Perplexity.