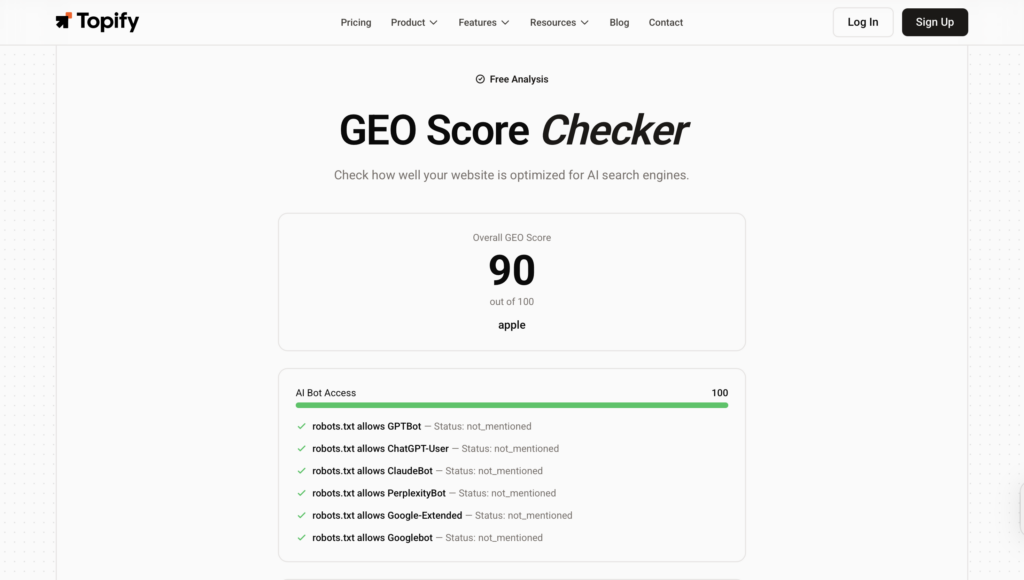
ChatGPT now handles roughly 2 billion queries a day, and the citation pool feeding those answers is unusually small. Five domains pull in 38% of all AI citations. The top 20 control 66%. If your brand isn’t inside that pool for the prompts your buyers actually ask, you don’t show up at all.
The blue link era was forgiving. The answer engine era isn’t.
Most marketing teams know their Google ranking for every priority keyword. Almost none know their answer inclusion rate inside ChatGPT, Gemini, Perplexity, or AI Overviews. That’s the gap an AEO audit closes.
What an AEO Audit Actually Measures (and Why It’s Not SEO)
An AEO audit is a diagnostic for how AI systems retrieve, synthesize, and attribute your brand inside generated answers. It’s not a ranking report. It’s a citation report. The goal isn’t to be on page one. It’s to be the answer.
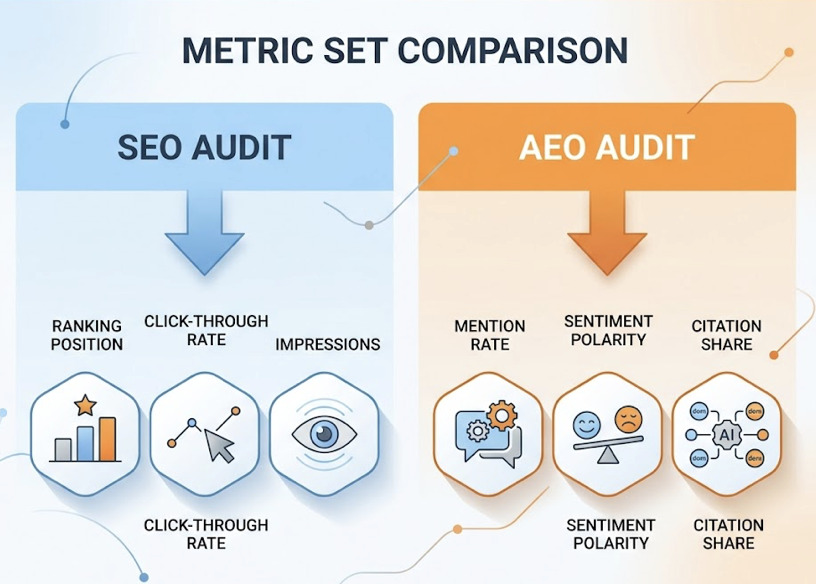
The metric set is different too. SEO audits live and die by ranking position, click-through rate, and impressions. AEO audits track three things: mention rate (does the AI bring you up), sentiment polarity (how does it describe you), and citation share (which domains are feeding the AI’s understanding of you).
That shift matters because the underlying logic changed. Search engines run deterministic logic, where a keyword maps to a ranked list. Answer engines run probabilistic logic, where the model synthesizes a response from training data plus real-time retrieval. You can’t optimize the second one with the playbook for the first.
Without a baseline audit across all three dimensions, every dollar spent on AEO is a guess.
Three Signs Your Brand Needs an AEO Audit This Quarter
The trap most marketing leaders fall into is the stability trap. Traffic looks fine on the surface. Underneath, AI is intercepting buyers before they reach your site. Three signals usually show up first.
Signal 1: Stable traffic, declining conversions. Your informational pages still rank. Impressions are flat or up. But trial signups and demo requests are sliding. That’s because Google AI Overviews are answering the question on the SERP itself. Seer Interactive found that organic CTR for informational queries with AI Overviews dropped from 1.76% to 0.61%, a 61% collapse. If your content is feeding the answer without getting credit, you’re funding a competitor’s growth.
Signal 2: Competitors keep showing up in “best for” prompts. You don’t. AI platforms typically return a shortlist of three to five vendors for commercial prompts. In B2B SaaS categories, 60-80% of AI answers cite the same dominant cohort of 3-5 brands. Being the seventh option doesn’t get you a chance. It gets you erased.
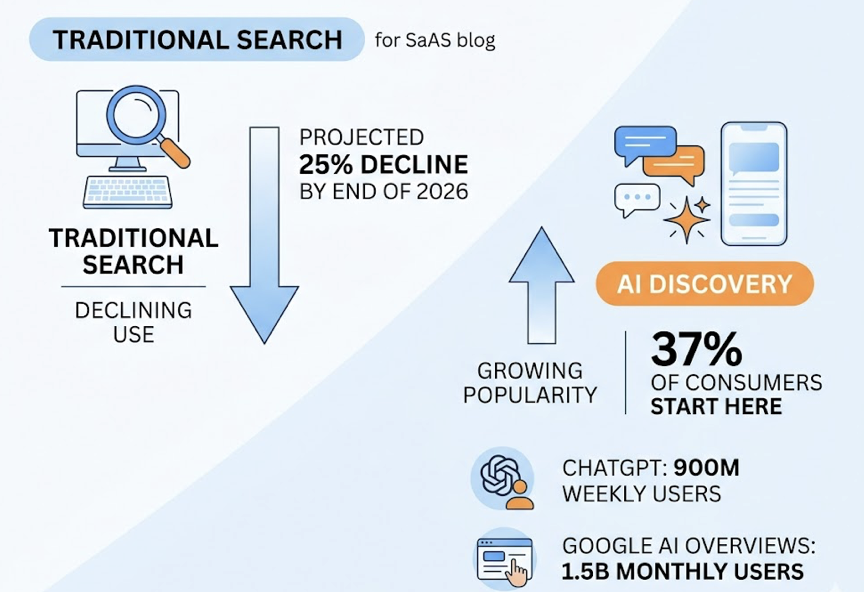
Signal 3: You have no idea how AI describes you. The AI doesn’t just list you. It characterizes you. “Affordable but limited.” “Powerful but complex.” “Good for small teams, weak at scale.” Those phrases shape which prompts you’re eligible to win. Gartner expects search volume to drop 25% by 2026, with that traffic shifting to AI surfaces. If you can’t audit your synthetic narrative, you can’t fix it.
If any of these sound familiar, you’re already late.
Step 1: Build the Prompt List That Reflects Real Buyer Intent
The audit is only as useful as the prompt bank behind it. Conversational AI queries average 23 words. Traditional search queries average 4. You can’t audit AEO with your old keyword list.
Build the bank around buyer journey, not topic clusters. Aim for 30 to 50 prompts as a minimum sample. Cover three intent layers:
- Informational: “What’s the best way to optimize B2B content for AI search?”
- Comparative: “How does [your category] handle enterprise-scale data?”
- Evaluation: “What are the risks of using [your tool type] for [specific use case]?”
Skip the definition trap. “What is X” prompts are high-volume but low-conversion. Users get the definition and bounce. The prompts that actually move pipeline are commercial: “best X for Y,” “compare X and Z,” “is X worth it for [persona].” AI search visitors arriving from commercial prompts convert at 4.4x to 23x the rate of traditional organic traffic, because the AI has already pre-qualified them.
Also account for query fan-out. AI systems often expand a single prompt into several sub-questions to build their answer. A buyer asking about “best CRMs for real estate” may silently trigger sub-answers about pricing, integrations, and onboarding time. Your audit needs to test those sub-prompts too, not just the headline question.
Step 2: Test Across ChatGPT, Gemini, Perplexity, and AI Overviews
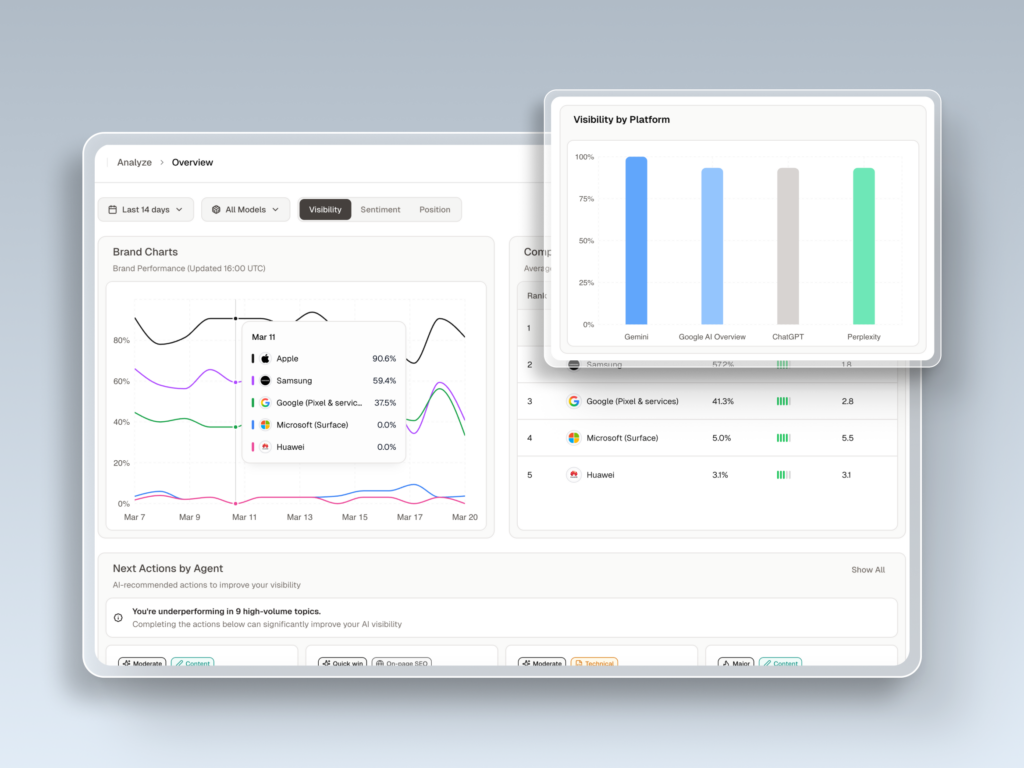
Single-platform audits will mislead you. Only 11% of businesses mentioned by one AI platform appear on a second platform for the same query. Visibility on ChatGPT tells you almost nothing about visibility on Perplexity or AI Overviews.
Each platform has its own citation bias, driven by retrieval logic and training data:
| Platform | Citation Logic | Top Source Types |
|---|---|---|
| ChatGPT | Editorial, reference-heavy | Wikipedia, Forbes, TechRadar, LinkedIn |
| Perplexity | Community and UGC-focused | Reddit, G2, Quora, industry forums |
| Gemini | Google ecosystem, social | YouTube, Reddit, Wikipedia, Medium |
| AI Overviews | Hybrid social plus authority | YouTube, Reddit, LinkedIn, Facebook |
That’s the gap most brands still can’t see.
Manual spot-checking has limits. AI responses are probabilistic, so the same prompt run three times can return three different citation sets. AI Mode in particular only overlaps with itself 9.2% of the time across repeated tests. Manual testing also can’t normalize for geography, browser memory, or hallucinated facts where the AI confidently misrepresents your pricing or features.
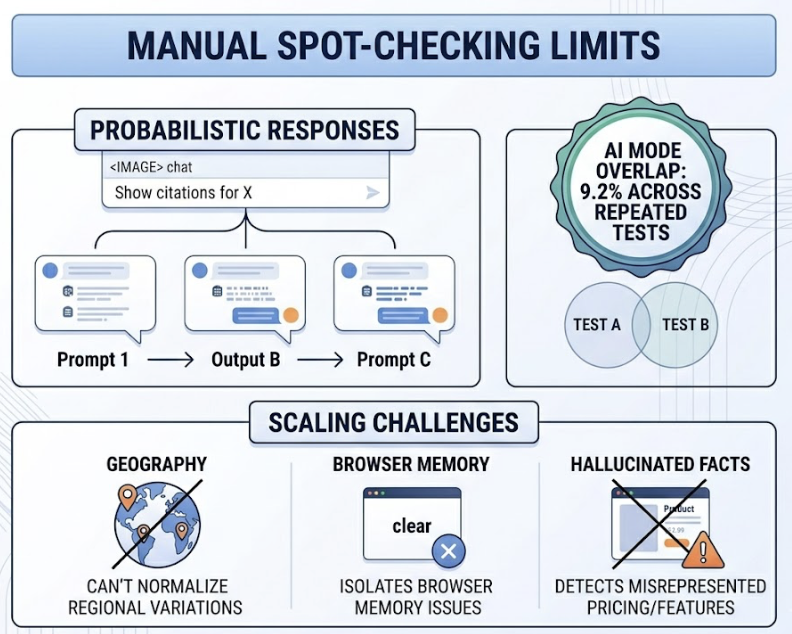
The fix is to run every test in clean, non-personalized environments. Incognito mode. Cleared chat history. Multiple regions if your buyers span them. Without that, the baseline is noise.
Step 3: Score Visibility, Sentiment, and Citation Sources
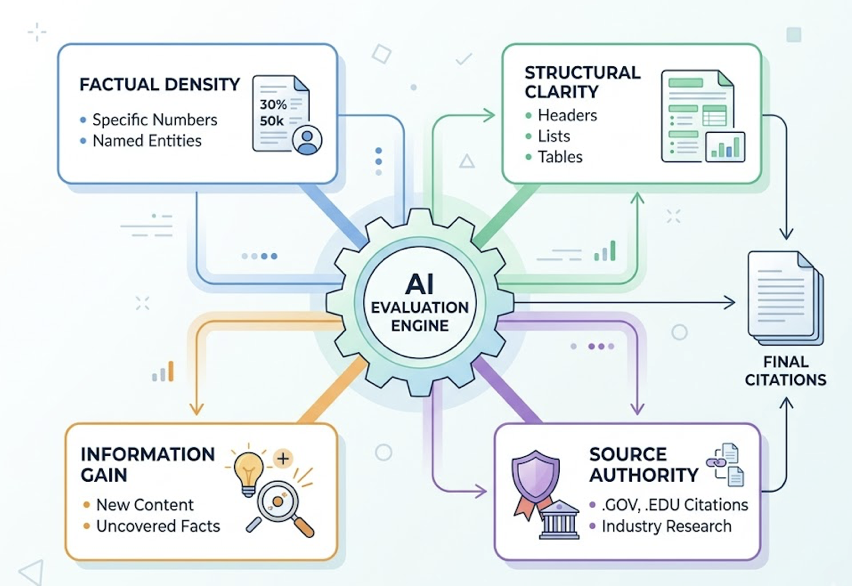
A useful AEO audit doesn’t stop at “yes, we got mentioned.” It scores three dimensions at once.
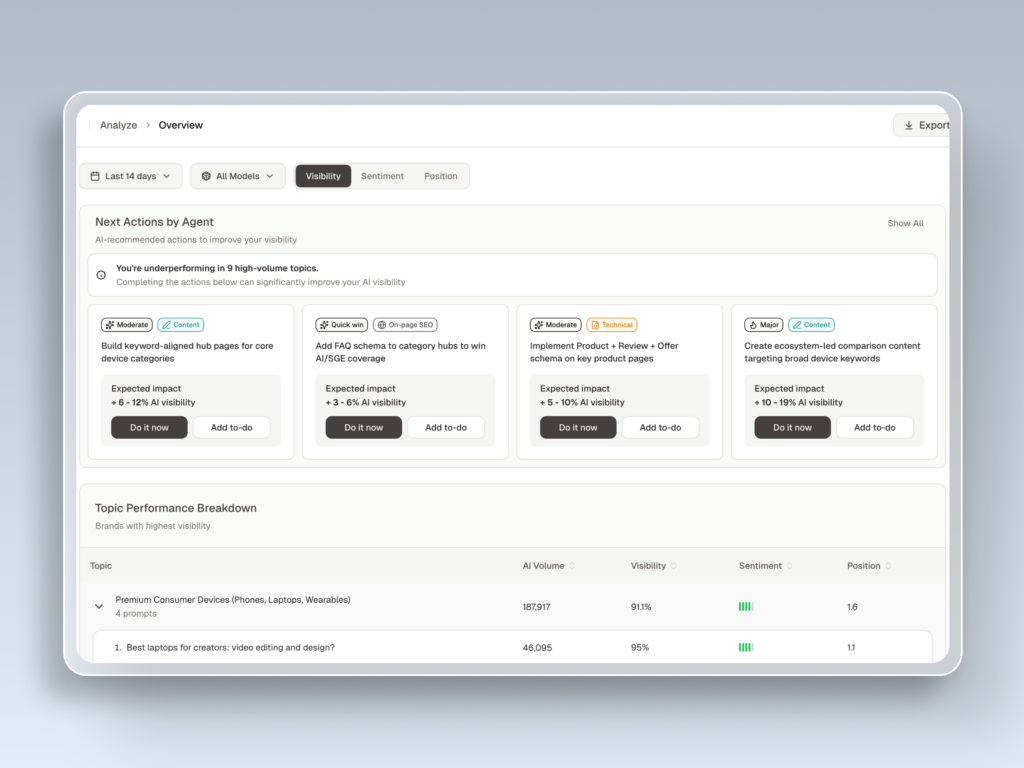
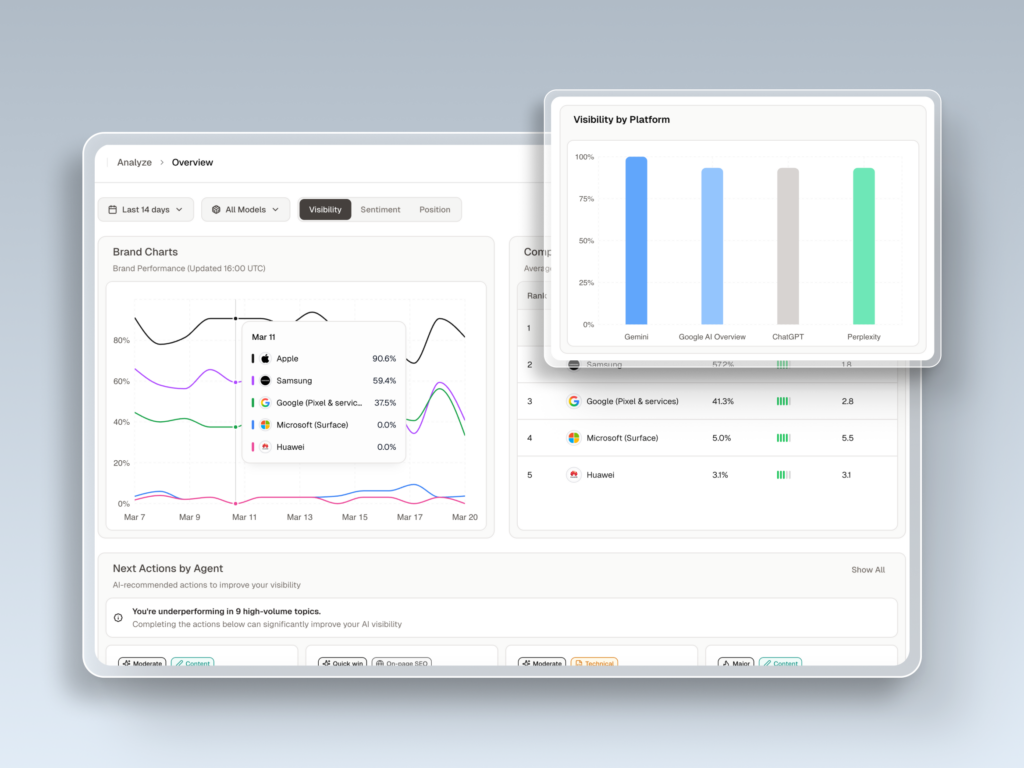
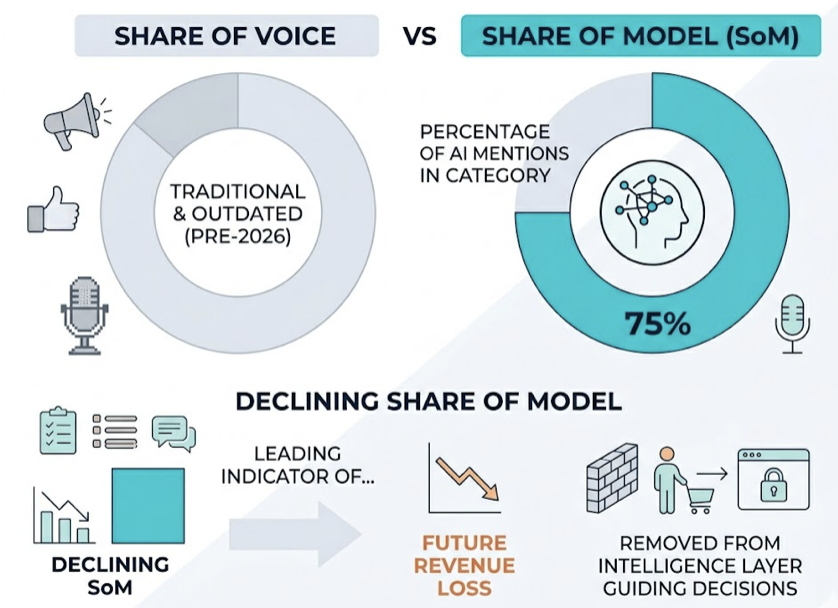
Visibility (Share of Model). This is the percentage of tracked prompts where the brand is mentioned. A 30% citation rate is a strong benchmark for established B2B brands on category-defining prompts. Distinguish between a mention (your name appears in the answer) and a citation (the AI links to your domain as a source). Citations drive referral traffic. Mentions drive recall. Both matter, but for different reasons.
Sentiment. Score the polarity of how AI describes you on a -100 to +100 scale. A brand with high visibility and negative sentiment is dealing with hallucinated reputation damage, where AI summarizes outdated complaints from old forum threads. The audit should pull the actual adjectives the AI uses. “Reliable” and “scalable” are wins. “Pricey” and “complex” tell you which prompts you’re losing before you even compete.
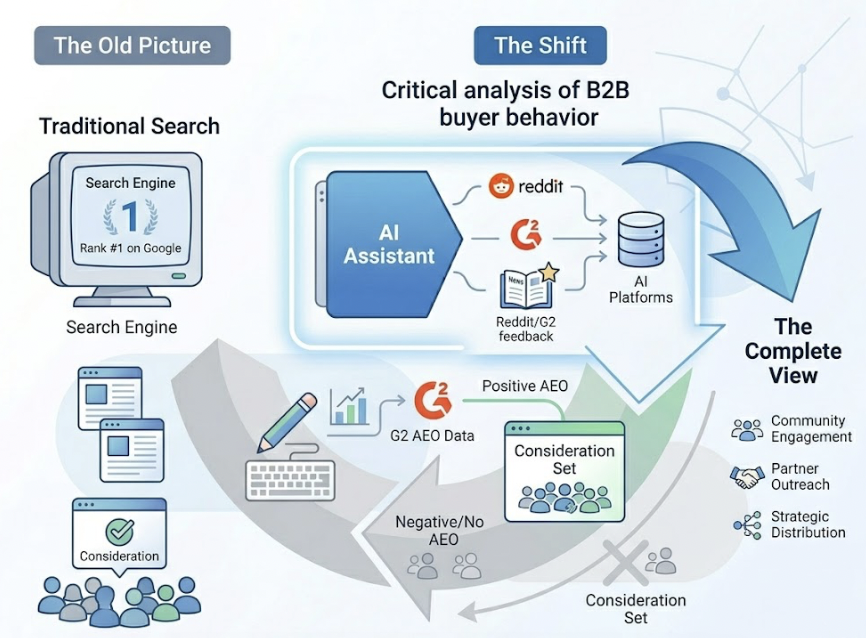
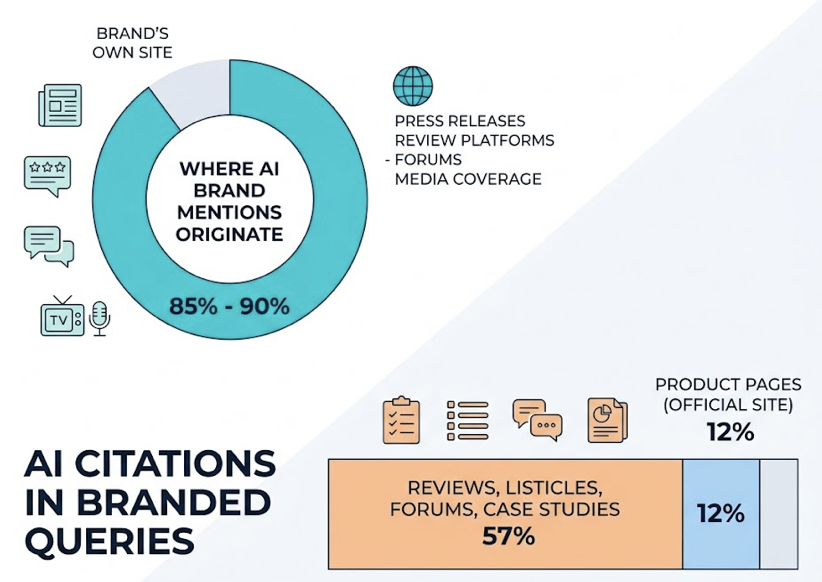
Source influence. Reverse-engineer the citations to find which third-party domains are shaping the AI’s answer. The data here is striking: 82-85% of AI citations come from third-party domains, not the brand’s own site. Community sites like Reddit and Quora account for 40-47% of citations. Reference sites like Wikipedia hold 7.8-11%. B2B platforms like G2 carry significant weight in commercial categories. If your audit only looks at your blog’s performance, you’re missing where the answer actually comes from.
A brand that overweights its own site and underweights Reddit, G2, and Wikipedia will consistently misread its real position in the AI ecosystem.
Common Mistakes That Make AEO Audits Useless
Most failed audits fail for the same three reasons.
The snapshot fallacy. Treating the audit as a one-time report is the most common mistake. AI model outputs aren’t stable like SERPs. Top citation sources can shift 40% month-over-month, a phenomenon often called citation drift. A brand visible in June can disappear in July after a model update. The audit only matters if it becomes the baseline for a time-series, not a one-off slide deck.
Auditing yourself in a vacuum. A synthesized answer has one top recommendation. Measuring your visibility without measuring competitors gives you no strategic context. You need Share of Model relative to your top three rivals, not just your own number. Otherwise you can’t tell if you’re gaining or losing ground in the buyer’s mind.
Reports without actions. This is the costliest one. An AEO audit that lists data without identifying answer gaps is a report, not a strategy. The real job of the audit is to show which specific prompts your competitors are winning, which third-party domains are feeding their citations, and which content gaps you need to close. If your technical docs are getting cited but your marketing blog isn’t, the action isn’t “publish more posts.” It’s restructure the blog for machine extractability. Audits without actions decay into spreadsheets nobody opens twice.
Why Manual AEO Audits Break After the First Report
Manual audits build intuition. They don’t scale. Most teams hit the wall after the first or second iteration, and the reasons are structural.
The first issue is prompt explosion. Covering a real buyer journey across multiple personas and geographies usually means tracking 100+ prompt variations. Querying five AI platforms manually, recording the responses, and scoring sentiment by hand is hundreds of hours of work that nobody has.
The second is data standardization. Manual scoring is subjective. Without an NLP engine to grade sentiment and tag citations consistently, the report becomes a pile of anecdotes. Two analysts looking at the same answer will disagree on whether the framing is positive or neutral.
The third is the retrievability gap. A manual audit can tell you that you’re not being cited. It can’t tell you why. It can’t reverse-engineer millions of source URLs to find which structural patterns, schema implementations, or third-party mentions are driving citations for your competitors. That’s not a willpower problem. It’s a tooling problem.
This is where teams move to a platform like Topify, which runs AEO audits as a continuous system rather than a one-time report. Topify covers ChatGPT, Gemini, Perplexity, and AI Overviews in parallel, scoring visibility, sentiment, and citation sources on the same prompt bank week over week. Instead of a 40-hour manual sprint, the baseline audit happens in the background and updates as model behavior drifts.
How Topify Turns a One-Time AEO Audit into Ongoing Intelligence
Three capabilities matter most for moving from audit to intelligence.
High-Value Prompt Discovery surfaces the prompts that actually drive citation value in your category, instead of leaving you to guess. The bank stays grounded in the language buyers use inside the AI interface, not the language your team uses in planning docs.
Dynamic Competitor Benchmarking tracks Share of Model and sentiment for your top rivals on the same prompts you’re monitoring. You see which competitors are winning specific prompts, what adjectives the AI is attaching to them, and where their sentiment is weak enough to contest.
Source Analysis reverse-engineers the third-party domains feeding the AI’s answers. If your category leans on Reddit threads and G2 reviews, the audit tells you exactly which communities and review categories deserve PR and content investment. AEO becomes less of a content task and more of a brand authority task.
That’s the shift. Not running the audit once. Running it as the operating layer.
Conclusion
A solid AEO audit is uncomfortable for most marketing leaders. The “rankings equal AI visibility” assumption almost never holds up under empirical testing. Strong SEO performance can coexist with near-zero citation share in synthesized answers.
The roadmap is simple in structure, hard in execution. Build a 30-50 prompt bank that mirrors real buyer intent. Test it across ChatGPT, Gemini, Perplexity, and AI Overviews in clean environments. Score visibility, sentiment, and citation sources together, not in isolation. Then move from manual spot-checks to continuous monitoring so you catch model drift and competitor moves in time to act on them.
A single AI citation in a high-intent prompt is now worth more than a thousand low-intent clicks. The brands that measure that visibility this quarter will own the recommendations next year.
FAQ
What’s the difference between an AEO audit and an SEO audit?
An SEO audit measures how well a page ranks in a list of links for a keyword. An AEO audit measures how often, how favorably, and from which sources a brand gets cited in AI-generated answers across conversational prompts.
How often should I run an AEO audit?
A full audit should run at least quarterly because of citation drift, where top AI sources shift 40% month-over-month. Continuous automated monitoring is the better default, with deeper analysis layered on top each quarter.
How many prompts should I test in an AEO audit?
30 to 50 prompts is the minimum for a statistically meaningful baseline. Cover all three buyer stages: awareness, consideration, and decision. Going below 30 risks anecdotal results.
Can I run an AEO audit for free?
You can spot-check on free versions of ChatGPT or Perplexity, and tools like the HubSpot AEO Grader give a one-time score. Free options can’t track competitors, score sentiment consistently, or run time-series analysis, which is where the strategic value sits.
Which AI platforms matter most for AEO visibility?
ChatGPT, Perplexity, Google AI Overviews including AI Mode, and Gemini cover over 90% of the conversational search market today. Skipping any of the four leaves a meaningful blind spot in the audit.