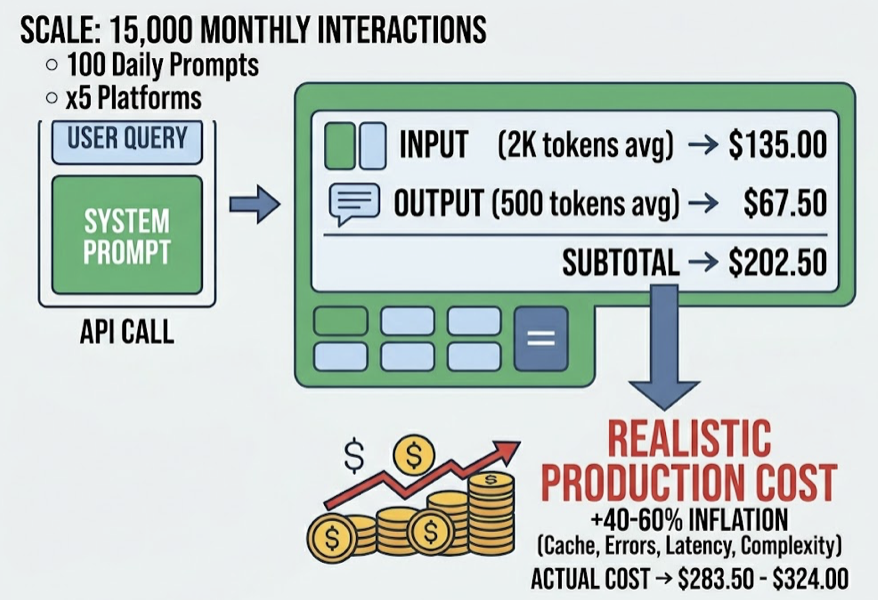
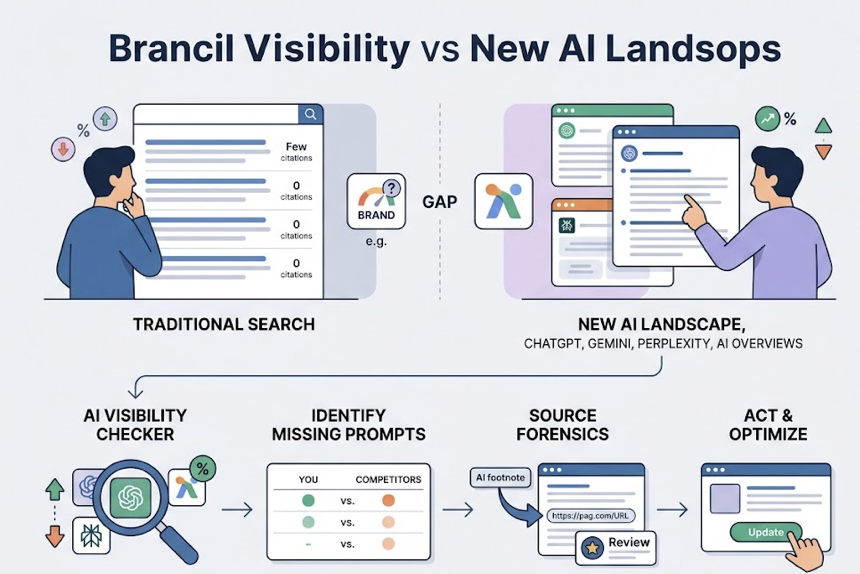
Your content ranks on Google. Your domain authority is solid. And yet ChatGPT, Perplexity, and Gemini never mention your brand.
That’s not a content quality problem. That’s a measurement problem.
You’ve been optimizing for a system that no longer controls the majority of high-intent discovery, and until now, you haven’t had a number that tells you exactly how far behind you are. The GEO Score fixes that.
GEO Score Is Not an SEO Metric. Here’s What Makes It Different.
A GEO Score is a 0-100 composite rating that measures how likely AI search engines are to cite your content when generating answers. It’s built specifically for generative engines like ChatGPT, Claude, Perplexity, and Gemini, which operate on fundamentally different logic than traditional search.
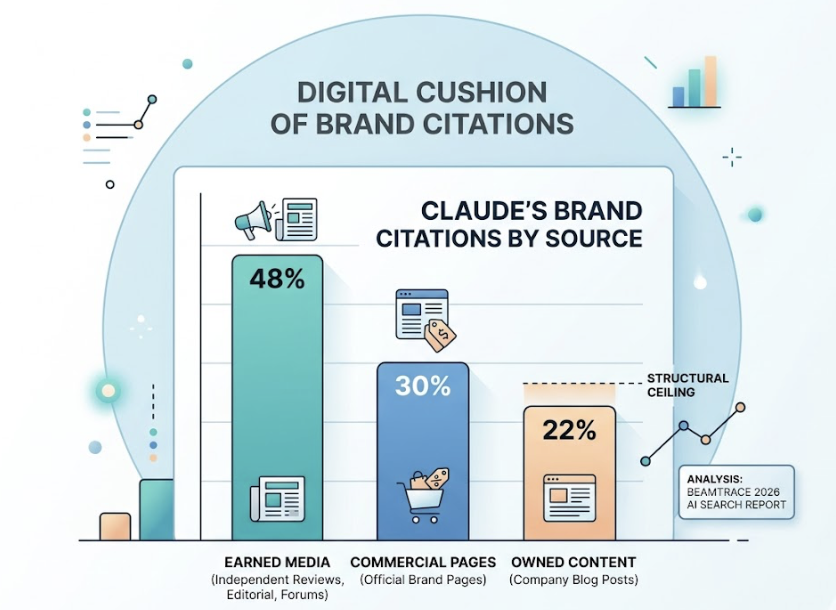
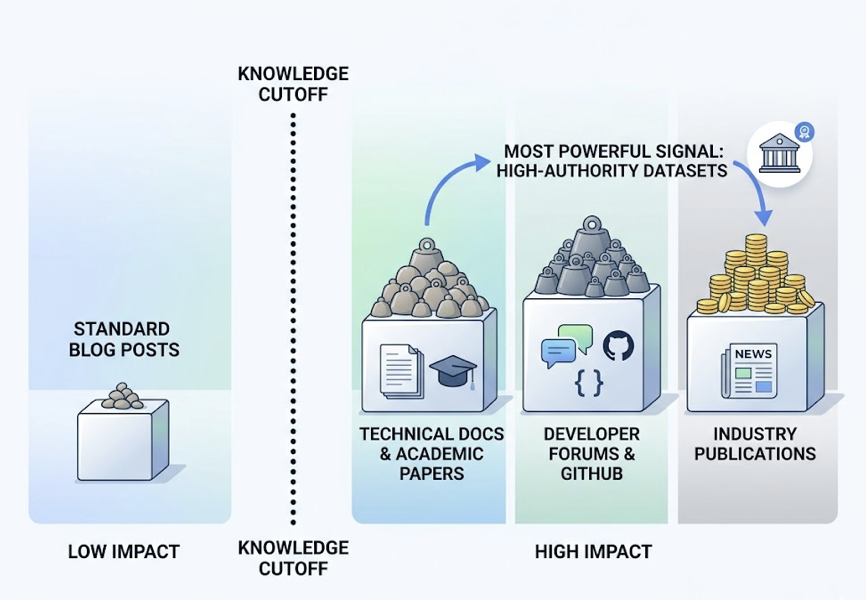
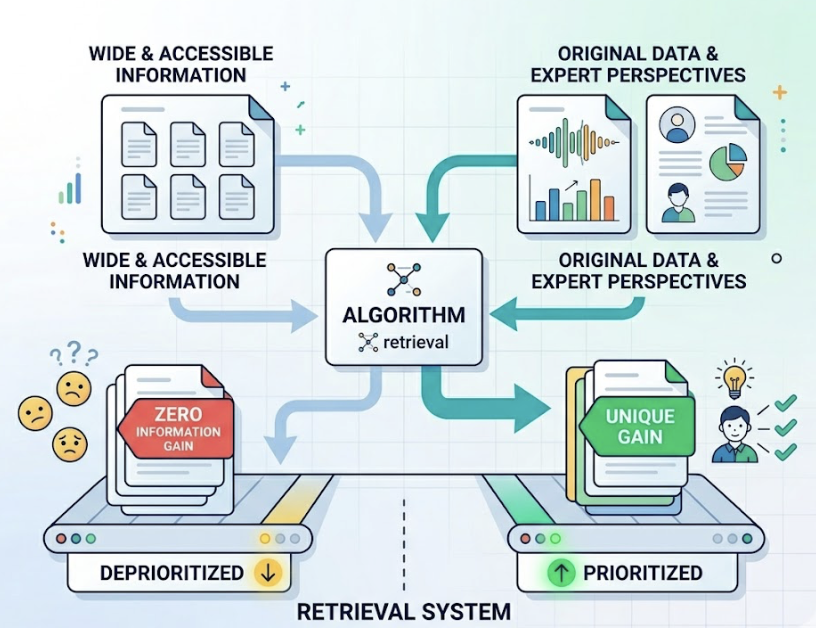
Here’s the gap most marketing teams don’t see: roughly 73% of brands ranking on Google’s first page have zero mentions in AI-generated responses for the same queries. Only 17% of AI Overview citations overlap with top-tier organic rankings. High SEO performance and high AI visibility are not the same thing.
The core difference comes down to how each system decides what to show. Traditional SEO ranks a list of links based on keyword matching and backlink graphs. Generative engines don’t produce ranked lists. They select one authoritative answer. If you’re not in that answer, you’re functionally invisible, regardless of where you sit in organic results.
| Dimension | Traditional SEO | GEO |
|---|---|---|
| Primary Goal | Rank pages in a link list to drive clicks | Be selected and cited as a source in an answer |
| Success Metric | Position, impressions, CTR | Citation frequency, brand mention rate, Share of Voice |
| Visibility Model | Gradient (Position 1 beats Position 5) | Binary: included in the answer or excluded |
| Trust Signal | Backlink volume and domain authority | Entity clarity, factual density, consensus verification |
| User Interaction | Clicks to external websites | Answers consumed within the AI interface |
That binary nature is exactly what the GEO Score measures: not your position in a list, but your probability of being selected as a source at all.
The 4 Dimensions That Make Up Your Score
The 0-100 rating is built from four dimensions. Each reflects a different stage of how AI engines evaluate and use your content.
Technical Foundation
AI crawlers like GPTBot and PerplexityBot don’t browse the way humans do. They need explicit access in your robots.txt, fast load times, and content that renders without JavaScript dependencies. Pages with a Largest Contentful Paint above 4 seconds are 72% less likely to be cited due to retrieval timeouts alone. Schema markup in JSON-LD acts as a direct feed to RAG engines, reducing the AI’s cognitive load and cutting hallucination risk.
AI Readability
Generative models favor what researchers call “atomic knowledge blocks”: self-contained passages of 150 to 300 words that make sense even when extracted out of context. Leading with a direct answer in the first 40 to 60 words improves citation probability by 27%, according to a Princeton study. Clear H2/H3 hierarchies and comparison tables give AI models structured data they can efficiently reassemble.
Content Quality
For an LLM, quality isn’t about writing style. It’s about the ratio of verifiable data points to filler. The leading benchmark is one cited fact per 80 words of prose. The original GEO research found that adding statistics and expert quotations was the single most reliable strategy to boost AI visibility, achieving a 30 to 40% improvement across all tested models. Replacing vague statements with statistical anchors is the difference between content that gets cited and content that gets skipped.
Authority and Trust
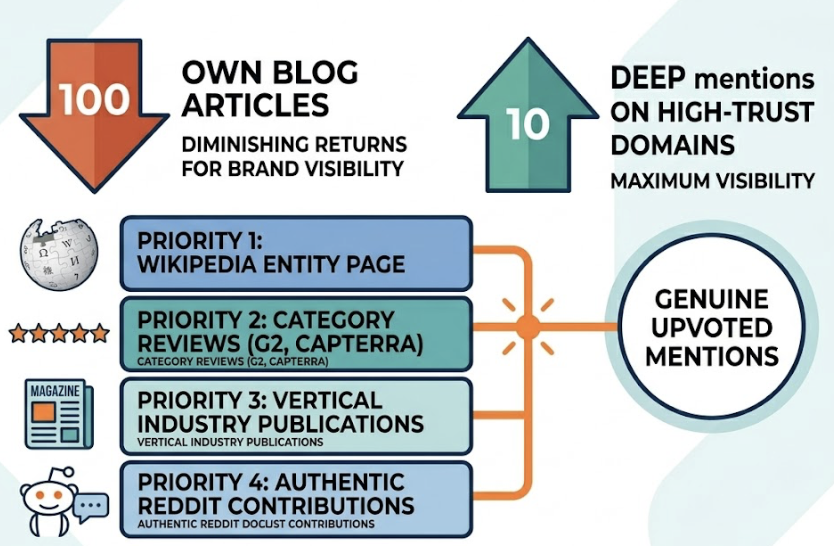
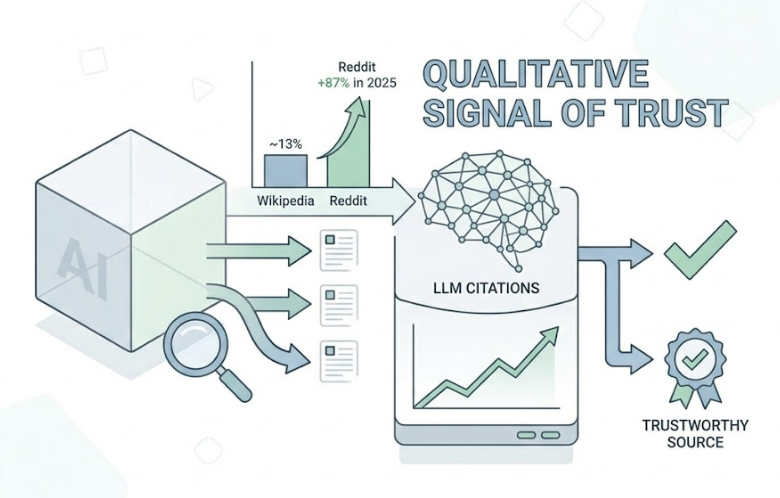
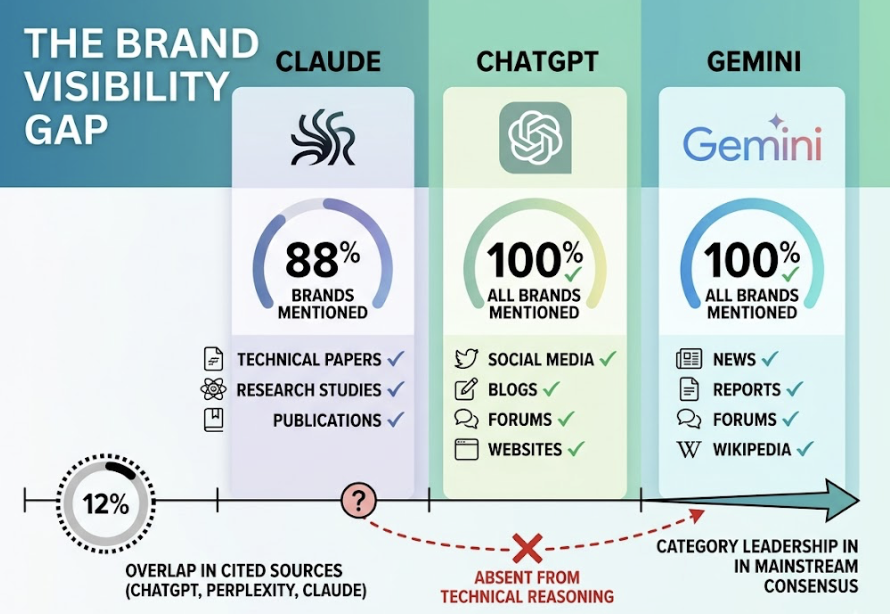
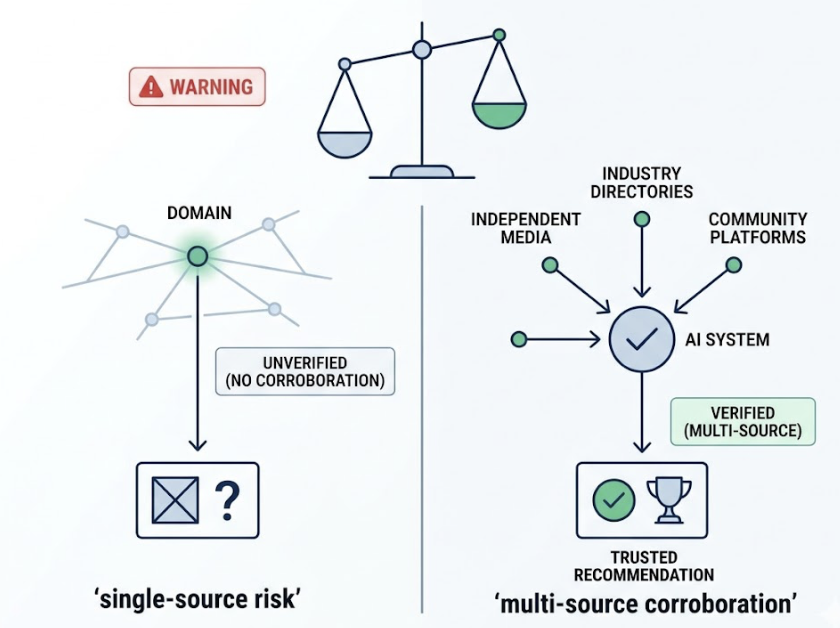
AI models evaluate trustworthiness through E-E-A-T signals: Experience, Expertise, Authoritativeness, and Trustworthiness. In 2026, 96% of AI citations originate from sources with demonstrably strong E-E-A-T. Brand mentions on platforms like LinkedIn, YouTube, and Wikipedia are 3x more predictive of AI citations than traditional backlinks. Consistent entity data across the web reinforces recognition.
Content quality and AI readability together typically account for more than half the composite score.
Scoring Below 70? That Number Isn’t Random.
The 70 mark reflects the statistical threshold at which consistent citation across major AI engines becomes likely. It’s the single most actionable benchmark in a GEO audit.
Scores between 0 and 49 indicate fundamental structural or technical problems. AI systems generally treat brands in this range as unrecognizable or untrustworthy. Common causes: blocking AI crawlers in robots.txt, or producing purely narrative content with no extractable facts.
Scores between 50 and 69 represent fragmented presence. The site has a foundation, but significant gaps remain. Citation is sporadic. A brand might appear in some query runs and disappear in others, often because entity signals are inconsistent across third-party platforms.
Scores between 70 and 89 cross the visibility threshold. Content is well-optimized, factual density is solid, and AI engines recognize the brand as an authority. Minor updates like refreshing data every 30 days are typically enough to push toward dominance.
Scores of 90 and above reflect best-in-class optimization. AI engines treat these sources as “grounding sources” and tend to surface them first or second.
The stakes are concrete. Research into AI shortlists shows that 71% of all product recommendations go to the top 3 brands identified by the model. Brands below the 70-point threshold get eliminated from consideration before a user ever visits their website.
Invisible to AI means invisible to the decision.
ChatGPT Has 900M Weekly Users. Are You in Their Answers?
The urgency around GEO Scores isn’t driven by speculation. It’s driven by adoption numbers that have already restructured how people find information.
ChatGPT reached 800 to 900 million weekly active users, doubling its scale in under a year. Perplexity processed 780 million queries monthly, a 239% increase in volume over ten months. Google AI Overviews now engage 2 billion monthly users across 200 countries, appearing in 25 to 50% of all searches.
The result is a zero-click reality. 93% of queries in Google’s AI Mode and 82% of ChatGPT Search interactions end without a click to an external website. If your brand isn’t cited in the generated response, the user never sees you.
The B2B numbers are especially stark. 73% of B2B buyers now use AI tools throughout their purchase research process. 47% of consumers say AI-generated summaries influence which brands they trust first. 25% of B2B buyers already use generative AI over traditional search for early-stage vendor research.
Brands that wait until AI search accounts for most of their traffic to start measuring GEO will be years behind in building the citation authority required to compete.
How to Check Your GEO Score in Under 30 Seconds
The GEO Score Checker is the fastest way to get a full AI visibility diagnostic. Enter a URL, and the tool runs live LLM API queries and vector analysis to evaluate your content the same way AI models do.
Within 30 seconds you get a composite 0-100 score, granular breakdowns across all four dimensions, a priority improvement roadmap with specific fixes ranked by impact, and a competitor benchmarking comparison against 3 to 5 rivals.
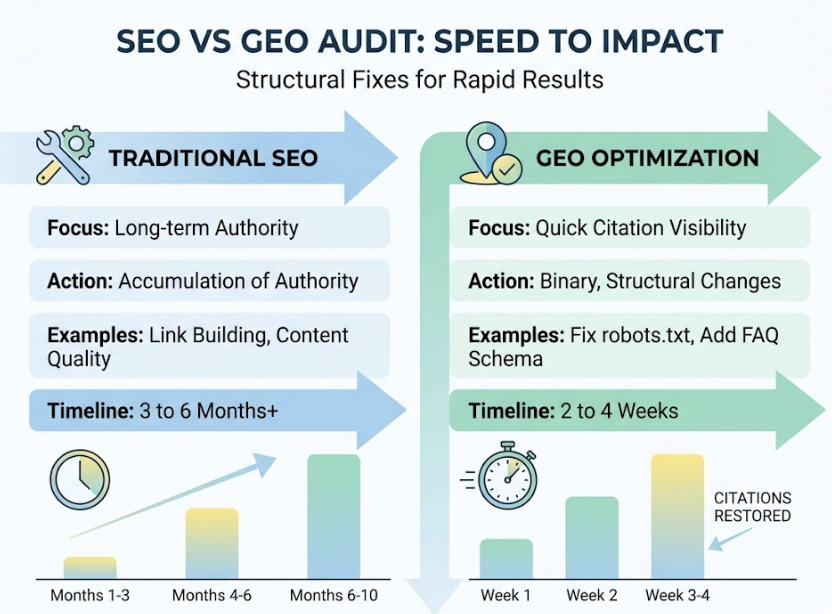
Unlike traditional SEO audits that surface dozens of low-priority issues, the results are designed around what actually moves citation rates. Correcting a robots.txt error or adding FAQ schema can restore citation visibility within a single crawl cycle: often 2 to 4 weeks for real-time engines like Perplexity. That’s one of the key practical advantages of GEO work. Many of the highest-impact changes are structural and binary, not the slow accumulation of authority over months.
Your GEO Score Is a Snapshot. AI Visibility Isn’t.
Checking your score once is a useful starting point. Treating it as a stable truth is where teams go wrong.
Only 30% of brands stay visible from one AI answer to the next for the same prompt. 40 to 60% of cited domains change within a single month, a pattern researchers call “citation drift.” Over six months, that drift rate climbs to 70 to 90%.
A score of 82 this week doesn’t mean you’ll hold that position next month. Competitors publish fresher data. AI model weights shift. Third-party sources that once anchored your authority get displaced by newer content.
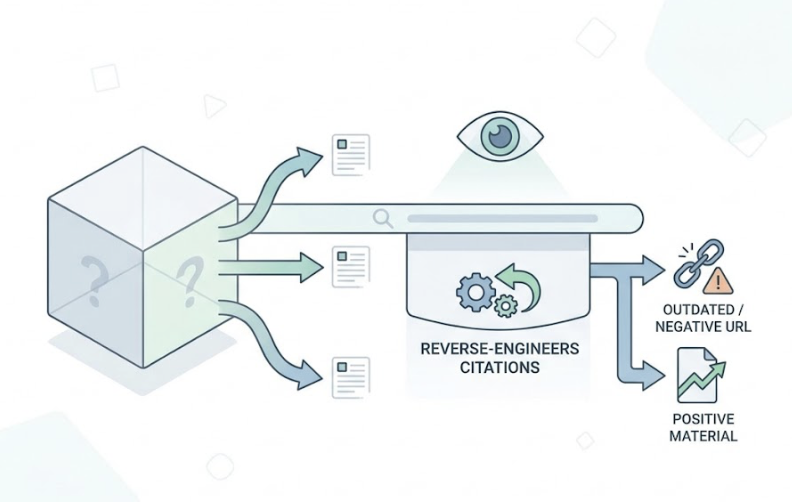
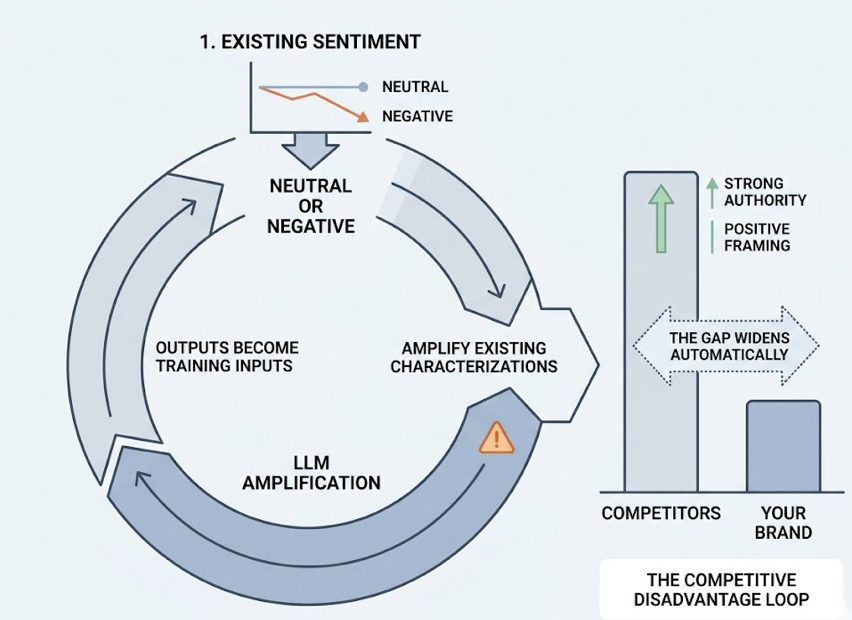
That’s the gap between knowing your score and maintaining AI visibility. Topify addresses this with cross-platform brand monitoring that runs rolling tracking across prompt libraries rather than one-time audits. The platform tracks sentiment shifts over time (the difference between “reliable enterprise choice” and “cost-effective but slow” carries real positioning weight), surfaces competitor displacement alerts when a rival captures your citation position, and runs source attribution analysis to identify which third-party domains are shaping how AI models describe your brand.
Knowing your GEO Score is step one. Making sure your brand keeps appearing in AI recommendations as the landscape shifts is the ongoing work.
What Is a GEO Score? Your 0-100 AI Visibility Rating
Your content ranks on Google. Your domain authority is solid. And yet ChatGPT, Perplexity, and Gemini never mention your brand.
That’s not a content quality problem. That’s a measurement problem.
You’ve been optimizing for a system that no longer controls the majority of high-intent discovery, and until now, you haven’t had a number that tells you exactly how far behind you are. The GEO Score fixes that.
GEO Score Is Not an SEO Metric. Here’s What Makes It Different.
A GEO Score is a 0-100 composite rating that measures how likely AI search engines are to cite your content when generating answers. It’s built specifically for generative engines like ChatGPT, Claude, Perplexity, and Gemini, which operate on fundamentally different logic than traditional search.
Here’s the gap most marketing teams don’t see: roughly 73% of brands ranking on Google’s first page have zero mentions in AI-generated responses for the same queries. Only 17% of AI Overview citations overlap with top-tier organic rankings. High SEO performance and high AI visibility are not the same thing.
The core difference comes down to how each system decides what to show. Traditional SEO ranks a list of links based on keyword matching and backlink graphs. Generative engines don’t produce ranked lists. They select one authoritative answer. If you’re not in that answer, you’re functionally invisible, regardless of where you sit in organic results.
| Dimension | Traditional SEO | GEO |
|---|---|---|
| Primary Goal | Rank pages in a link list to drive clicks | Be selected and cited as a source in an answer |
| Success Metric | Position, impressions, CTR | Citation frequency, brand mention rate, Share of Voice |
| Visibility Model | Gradient (Position 1 beats Position 5) | Binary: included in the answer or excluded |
| Trust Signal | Backlink volume and domain authority | Entity clarity, factual density, consensus verification |
| User Interaction | Clicks to external websites | Answers consumed within the AI interface |
That binary nature is exactly what the GEO Score measures: not your position in a list, but your probability of being selected as a source at all.
The 4 Dimensions That Make Up Your Score
The 0-100 rating is built from four dimensions. Each reflects a different stage of how AI engines evaluate and use your content.
Technical Foundation
AI crawlers like GPTBot and PerplexityBot don’t browse the way humans do. They need explicit access in your robots.txt, fast load times, and content that renders without JavaScript dependencies. Pages with a Largest Contentful Paint above 4 seconds are 72% less likely to be cited due to retrieval timeouts alone. Schema markup in JSON-LD acts as a direct feed to RAG engines, reducing the AI’s cognitive load and cutting hallucination risk.
AI Readability
Generative models favor what researchers call “atomic knowledge blocks”: self-contained passages of 150 to 300 words that make sense even when extracted out of context. Leading with a direct answer in the first 40 to 60 words improves citation probability by 27%, according to a Princeton study. Clear H2/H3 hierarchies and comparison tables give AI models structured data they can efficiently reassemble.
Content Quality
For an LLM, quality isn’t about writing style. It’s about the ratio of verifiable data points to filler. The leading benchmark is one cited fact per 80 words of prose. The original GEO research found that adding statistics and expert quotations was the single most reliable strategy to boost AI visibility, achieving a 30 to 40% improvement across all tested models. Replacing vague statements with statistical anchors is the difference between content that gets cited and content that gets skipped.
Authority and Trust
AI models evaluate trustworthiness through E-E-A-T signals: Experience, Expertise, Authoritativeness, and Trustworthiness. In 2026, 96% of AI citations originate from sources with demonstrably strong E-E-A-T. Brand mentions on platforms like LinkedIn, YouTube, and Wikipedia are 3x more predictive of AI citations than traditional backlinks. Consistent entity data across the web reinforces recognition.
Content quality and AI readability together typically account for more than half the composite score.
Scoring Below 70? That Number Isn’t Random.
The 70 mark reflects the statistical threshold at which consistent citation across major AI engines becomes likely. It’s the single most actionable benchmark in a GEO audit.
Scores between 0 and 49 indicate fundamental structural or technical problems. AI systems generally treat brands in this range as unrecognizable or untrustworthy. Common causes: blocking AI crawlers in robots.txt, or producing purely narrative content with no extractable facts.
Scores between 50 and 69 represent fragmented presence. The site has a foundation, but significant gaps remain. Citation is sporadic. A brand might appear in some query runs and disappear in others, often because entity signals are inconsistent across third-party platforms.
Scores between 70 and 89 cross the visibility threshold. Content is well-optimized, factual density is solid, and AI engines recognize the brand as an authority. Minor updates like refreshing data every 30 days are typically enough to push toward dominance.
Scores of 90 and above reflect best-in-class optimization. AI engines treat these sources as “grounding sources” and tend to surface them first or second.
The stakes are concrete. Research into AI shortlists shows that 71% of all product recommendations go to the top 3 brands identified by the model. Brands below the 70-point threshold get eliminated from consideration before a user ever visits their website.
Invisible to AI means invisible to the decision.
ChatGPT Has 900M Weekly Users. Are You in Their Answers?
The urgency around GEO Scores isn’t driven by speculation. It’s driven by adoption numbers that have already restructured how people find information.
ChatGPT reached 800 to 900 million weekly active users, doubling its scale in under a year. Perplexity processed 780 million queries monthly, a 239% increase in volume over ten months. Google AI Overviews now engage 2 billion monthly users across 200 countries, appearing in 25 to 50% of all searches.
The result is a zero-click reality. 93% of queries in Google’s AI Mode and 82% of ChatGPT Search interactions end without a click to an external website. If your brand isn’t cited in the generated response, the user never sees you.
The B2B numbers are especially stark. 73% of B2B buyers now use AI tools throughout their purchase research process. 47% of consumers say AI-generated summaries influence which brands they trust first. 25% of B2B buyers already use generative AI over traditional search for early-stage vendor research.

Brands that wait until AI search accounts for most of their traffic to start measuring GEO will be years behind in building the citation authority required to compete.
How to Check Your GEO Score in Under 30 Seconds
The GEO Score Checker is the fastest way to get a full AI visibility diagnostic. Enter a URL, and the tool runs live LLM API queries and vector analysis to evaluate your content the same way AI models do.
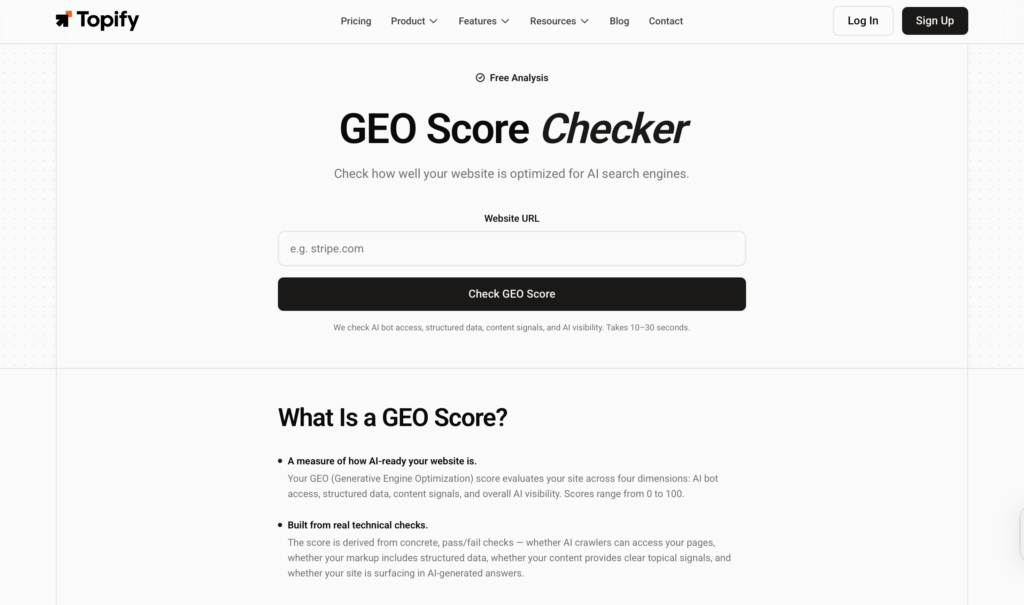
Within 30 seconds you get a composite 0-100 score, granular breakdowns across all four dimensions, a priority improvement roadmap with specific fixes ranked by impact, and a competitor benchmarking comparison against 3 to 5 rivals.
Unlike traditional SEO audits that surface dozens of low-priority issues, the results are designed around what actually moves citation rates. Correcting a robots.txt error or adding FAQ schema can restore citation visibility within a single crawl cycle: often 2 to 4 weeks for real-time engines like Perplexity. That’s one of the key practical advantages of GEO work. Many of the highest-impact changes are structural and binary, not the slow accumulation of authority over months.
Your GEO Score Is a Snapshot. AI Visibility Isn’t.
Checking your score once is a useful starting point. Treating it as a stable truth is where teams go wrong.
Only 30% of brands stay visible from one AI answer to the next for the same prompt. 40 to 60% of cited domains change within a single month, a pattern researchers call “citation drift.” Over six months, that drift rate climbs to 70 to 90%.
A score of 82 this week doesn’t mean you’ll hold that position next month. Competitors publish fresher data. AI model weights shift. Third-party sources that once anchored your authority get displaced by newer content.
That’s the gap between knowing your score and maintaining AI visibility. Topify addresses this with cross-platform brand monitoring that runs rolling tracking across prompt libraries rather than one-time audits. The platform tracks sentiment shifts over time (the difference between “reliable enterprise choice” and “cost-effective but slow” carries real positioning weight), surfaces competitor displacement alerts when a rival captures your citation position, and runs source attribution analysis to identify which third-party domains are shaping how AI models describe your brand.
Knowing your GEO Score is step one. Making sure your brand keeps appearing in AI recommendations as the landscape shifts is the ongoing work.
Conclusion
A GEO Score gives you something that’s been missing from most marketing stacks: a number that reflects how AI engines actually see your brand. Not how you rank in a list, but whether you’re selected as a trusted source in the answers that now drive discovery and purchasing decisions.
The 70-point threshold is where AI visibility becomes consistent. Below it, your brand’s presence is sporadic at best. Above it, you’re in contention for the AI shortlists that 71% of product recommendations flow through.
Check your score with the GEO Score Checker. Understand which of the four dimensions is holding you back. Then build toward the monitoring cadence that keeps you visible as AI recommendations continue to shift.
FAQ
What’s a good GEO score? A score of 70 or higher is the threshold for consistent AI visibility. Scores above 85 are typical of category leaders who publish definitive data and structured, extraction-ready content. Market leaders in 2026 generally maintain averages above 85 across their target prompt sets.
How is a GEO score different from domain authority?
Domain authority measures backlink strength to predict search ranking potential. GEO Score measures content clarity, factual density, and structural extractability to predict citation probability in AI-generated answers. There’s often a negative correlation between the two: high-DA sites frequently score poorly on GEO because they’re built for click-through, not AI extraction.
How often should I check my GEO score?
Monthly is the minimum. Weekly automated tracking is the recommended cadence in competitive categories, given that 40 to 60% of cited domains shift within a single month. A one-time audit tells you where you stand today, not where you’ll be when your competitor refreshes their data next week.
Can a high GEO score guarantee AI citation?
No. LLM outputs are probabilistic by nature, and no tool can guarantee a specific outcome. A high GEO Score maximizes the probability of selection and helps ensure that when your brand is cited, the information presented is accurate and favorable.
What’s the fastest way to improve a low GEO score?
Technical and structural fixes offer the highest return. Rewriting the first 100 words of a page to lead with a direct, fact-dense answer and implementing FAQPage schema typically restore citation visibility within weeks. Unblocking AI crawlers in robots.txt is often the single highest-impact binary fix, with results visible within one crawl cycle.