Your keyword rankings look fine. But your traffic is dropping.
This is the situation more SEO and content teams are walking into in 2026. The disconnect isn’t a technical glitch. It’s a structural gap in how most keyword research tools are built. They were designed for Google. And Google, while still dominant, is no longer where a growing share of your audience starts their search.
Here’s what that means for your tool stack, and which keyword research software is actually worth running in this environment.
Most Keyword Research Software Gets One Big Thing Wrong
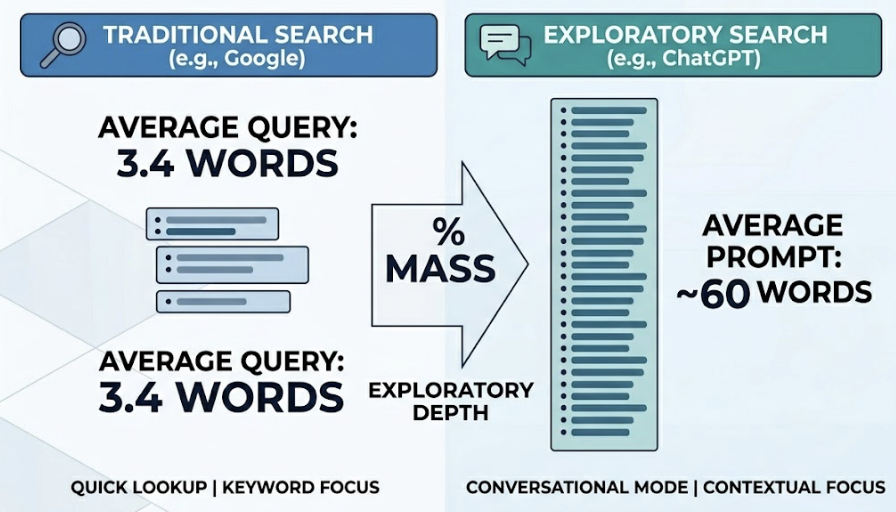
The average AI prompt is 7.22 words long. The average keyword these tools are built to track is 2-3 words. That’s not a small gap.
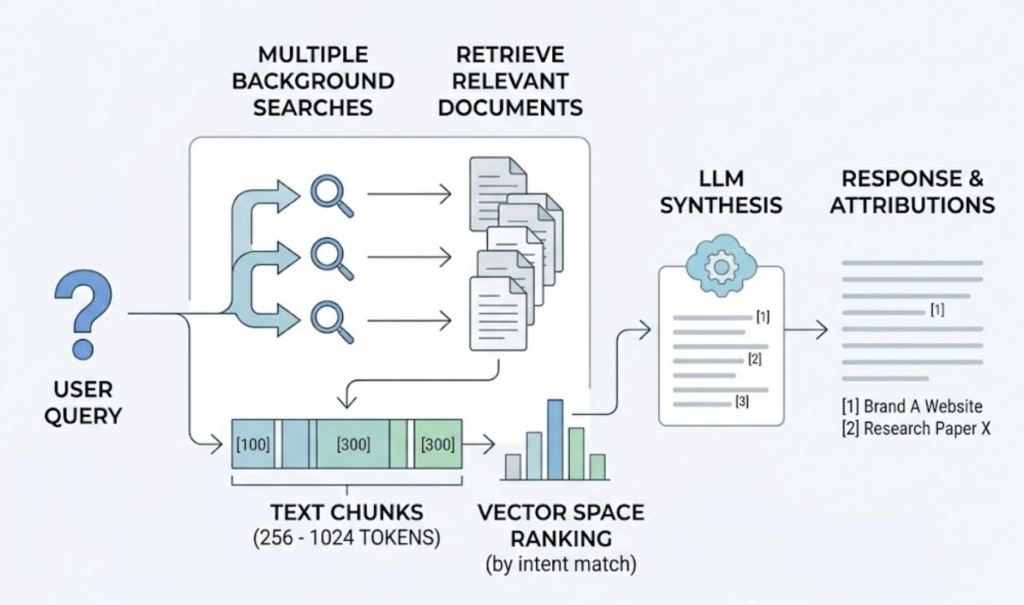
Traditional tools like Ahrefs, Semrush, and Moz pull from Google’s Keyword Planner and clickstream data. They’re excellent at what they were built for. But none of them natively track what’s happening inside ChatGPT, Gemini, or Perplexity, which is where a growing share of product discovery now happens.
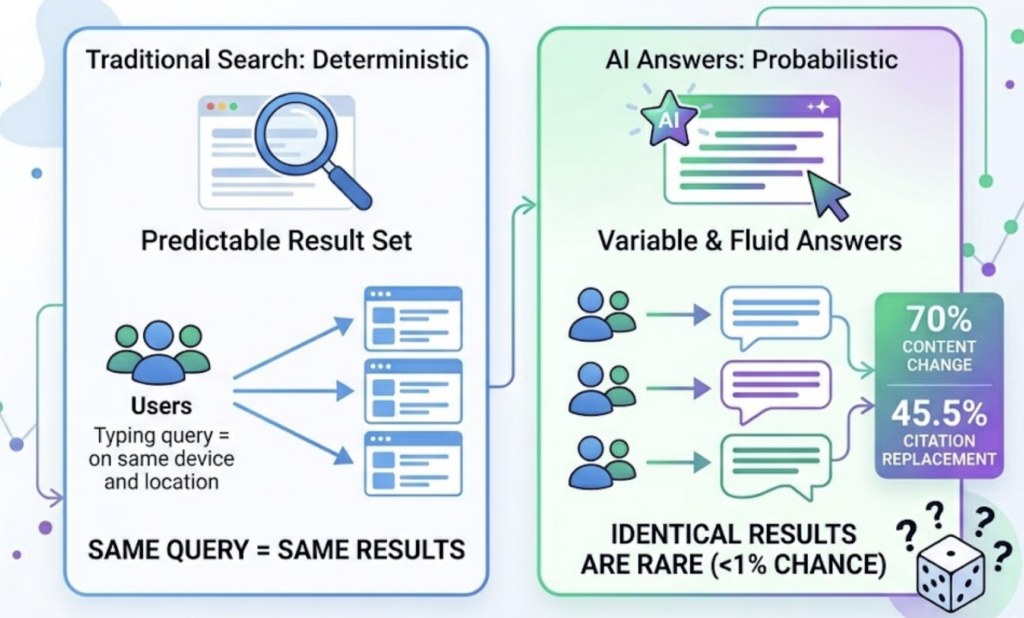
The numbers back this up. ChatGPT reached 900 million weekly active users by February 2026, up from 400 million in early 2025. Perplexity’s web traffic grew 370% year-over-year. Meanwhile, AI Overviews now trigger on approximately 48% of all tracked queries, and when they do, the average click-through rate for organic links drops by 34.5%. For some high-volume terms, that drop hits 64%.
That’s the structural problem. Your keyword research tool might tell you you’re ranking. It won’t tell you that an AI summary is absorbing the clicks before anyone reaches your result.
The 7 Keyword Research Tools Worth Your Time in 2026
Before going deeper on each, here’s a quick orientation across the full stack:
| Tool | Starting Price | Best For | AI Search Data |
|---|---|---|---|
| Topify | $99/mo | SEO/content teams, agencies | Yes (7 AI platforms) |
| Semrush | $139.95/mo | Enterprise marketing, PPC | Yes (via $99/mo add-on) |
| Ahrefs | $129/mo | Link building, competitor depth | Yes (via Brand Radar add-on) |
| Moz Pro | $39/mo | SMBs, beginners | Partial |
| Ubersuggest | $29/mo | Freelancers, small business | Minimal |
| Google Search Console | Free | Any site with Google traffic | Limited (Google AIO only) |
| Google Keyword Planner | Free (requires ad spend) | PPC teams | No |
The most important column isn’t price. It’s the last one.
#1: Topify — The Only Keyword Research Tool Built for AI Search
Every other tool on this list started as a Google-first platform that added AI features later. Topify is the exception. It was built to answer a different question: not “what does Google rank?” but “what does AI recommend?”
That distinction shapes the entire product. Topify’s High-Value Prompt Discovery continuously surfaces the specific natural-language prompts that drive AI recommendations across ChatGPT, Gemini, Perplexity, and four other major platforms. For a content team, this means you can see exactly which prompts are triggering competitor citations and identify where your content has a “citation gap.”
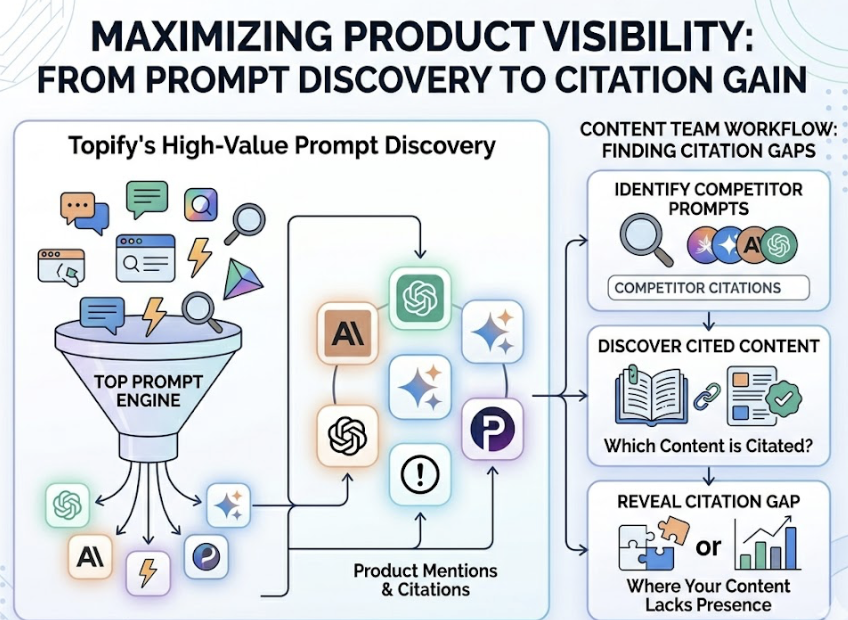
The AI Volume Analytics feature adds a layer that traditional keyword volume metrics can’t replicate. Instead of 12-month rolling Google averages, you’re looking at prompt frequency data drawn from actual AI search behavior. That’s a different dataset.
On the Basic plan at $99/mo, you get 100 tracked prompts and 9,000 AI answer analyses per cycle. For an agency already running Semrush or Ahrefs, Topify functions as the dedicated AI visibility layer that neither of those platforms was designed to provide.
The practical use case is straightforward. If 36% of informational searches in your category have already migrated to AI assistants, optimizing purely for Google rankings is a strategy with a shrinking ceiling.
#2: SEMrush — Still the Benchmark for Traditional Keyword Research
For teams with budget and a need for breadth, Semrush keyword research remains the standard. Its database covers 27.3 billion keywords globally, with 3.7 billion in the US alone. That density is hard to match for content clustering, intent mapping, and competitive PPC analysis.
The Keyword Magic Tool is the core engine here. It groups keywords by semantic similarity and intent type, which makes it genuinely useful for building out topic clusters rather than individual page targets.
On AI search, Semrush has retrofitted. Its AI Visibility Toolkit tracks brand mentions across ChatGPT and Gemini for a $99/month add-on. It integrates into the broader Share of Voice dashboards, which makes it convenient if your team is already running Semrush as the central reporting hub. That said, it’s an add-on, not a core architecture. The depth Topify offers at $99/mo as a standalone AI-native platform isn’t directly comparable.
The real consideration for agencies: once you add the AI toolkit and scale to full digital marketing capabilities, the total Semrush investment can exceed $265/month for a single user. That’s a legitimate cost for what you get, but it’s worth knowing upfront.
Best for: Agencies managing multi-client SEO + PPC + social reporting who need centralized dashboards.
#3: Ahrefs — Where Backlink Data Meets Keyword Intelligence
Ahrefs keyword research is built on a different foundation: its 35-trillion-link backlink index. That makes it the preferred tool for technical SEOs who think about rankings through the lens of domain authority and link equity.
The Keywords Explorer’s “Traffic Potential” metric is worth calling out specifically. Rather than raw search volume, it estimates the actual clicks a page is likely to receive, which accounts for click-through rates suppressed by AI features. That’s a more honest number in 2026.
Here’s a direct comparison on the dimensions that matter most:
| Dimension | Ahrefs | Semrush |
|---|---|---|
| Backlink Index | 35T links / 500M domains | 43T links / 390M domains |
| Keyword Database | 28.7B keywords | 27.3B keywords |
| Best Use Case | Link building, competitor depth | Content clustering, PPC |
| AI Solution | Brand Radar (from $199/mo) | AI Visibility Toolkit ($99/mo add-on) |
| Interface Style | Minimalist, data-focused | Data-dense, command-center |
Ahrefs’ Brand Radar pulls from 239 million real user prompts to show where a brand appears in AI responses. The limitation is pricing: the single-index plan runs $199/month, and a 6-platform bundle hits $699/month. That puts comprehensive AI coverage squarely in enterprise territory.
Best for: Content teams and technical SEOs with a strong link-building workflow who need precise competitor analysis.
Free Keyword Research Tools That Actually Work
Free tools won’t replace a paid research stack. But the right ones will carry you further than most people realize.
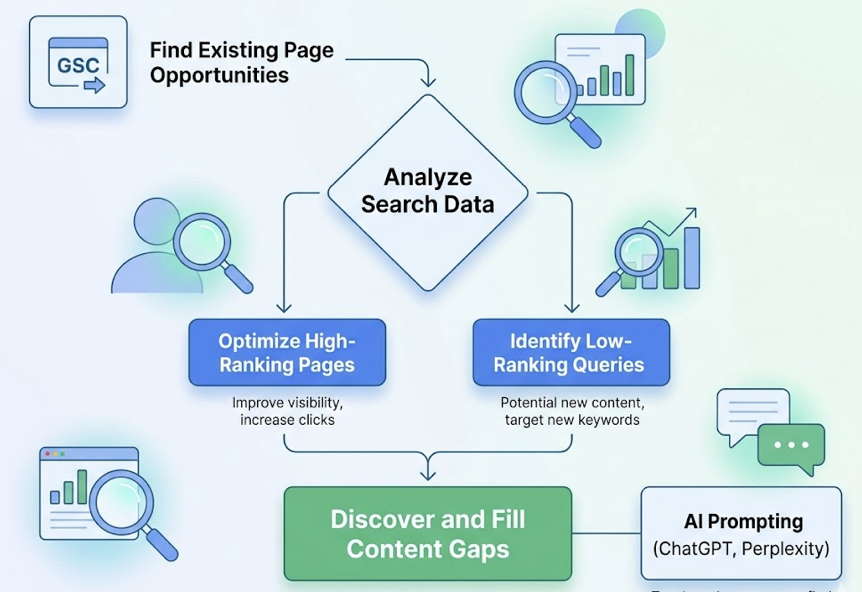
Google Search Console is the most underutilized free keyword research tool available. Because it pulls from Google’s actual internal logs, the click and impression data is more accurate than anything a third-party scraper can produce. In 2026, GSC added AI-powered querying, so you can now ask it directly: “Show me queries where my CTR dropped despite a top-3 ranking.” That’s not a generic export. That’s a diagnostic.
The limitation is structural. GSC is a post-click tool. It shows you performance data for keywords you already rank for. It won’t help you discover what you don’t yet target, and it has zero visibility into ChatGPT, Perplexity, or any non-Google platform.
Google Keyword Planner works as a commercial demand signal, but the volume ranges it shows (1K-10K rather than exact numbers) make it difficult to prioritize between similar-intent keywords unless you’re running consistent ad spend.
Ubersuggest’s free version gives you 3 web searches per day, or 40 per day via the Chrome extension. It’s a starting point for quick checks and light discovery. It’s not a competitive analysis tool.
For small businesses and startups who want to find keywords without a paid tool, the practical path is: GSC for existing-page optimization plus manual AI prompting to test how your brand and category appear in ChatGPT and Perplexity. That combination won’t give you volume data, but it will tell you where your content gaps are.
How to Pick the Right Keyword Research Tool for Your Situation
The four variables that actually drive this decision: budget, team scale, primary use case, and whether your audience is using AI search.
That last variable is more decisive than most teams treat it. Data shows that 30% of computer programming searches and 36% of general informational searches have already migrated to AI assistants. If you’re in SaaS, B2B tech, healthcare, or any research-heavy category, the “AI search layer” isn’t optional.
Here’s how the right stack typically maps to each scenario:
| Your Situation | Primary Tool | AI Search Layer |
|---|---|---|
| Solo founder / small business | Google Search Console + Ubersuggest (free) | Manual ChatGPT auditing |
| Content marketing team | Ahrefs Lite or Standard | Topify (for prompt gap analysis) |
| Digital marketing agency | Semrush Guru/Business | Topify (for client-facing AI visibility reporting) |
| E-commerce brand | Semrush or Ahrefs | Topify (for product discovery in AI shopping queries) |
| SaaS / B2B product | Ahrefs | Topify (AI citation tracking is core, not supplemental) |
The agency case deserves a note. Gartner projects traditional search traffic will fall 25% by end of 2026. Clients are starting to ask about AI visibility. Agencies that can’t report on it are running a gap that will become visible. Semrush handles the traditional reporting layer well. Topify fills the AI-native gap that Semrush’s add-on approaches but doesn’t fully address.
For content creators and smaller teams where budget is the binding constraint: start with GSC and one paid tool at the Lite tier. Add AI search coverage when your category’s migration becomes measurable in your own traffic data.
Conclusion
The honest answer to “which keyword research tool is most accurate?” is: accurate at what, exactly?
Semrush and Ahrefs are accurate for Google. They’re exceptional at it. But AI Overviews now trigger on 48% of tracked queries, and that rate exceeds 80% in categories like healthcare and B2B technology. The data those platforms can’t show you is increasingly where the competitive gap lives.
The practical recommendation for 2026: run a traditional tool for your Google infrastructure, and add a dedicated AI layer for the generative search dimension. That’s not a speculative hedge. It’s a response to where user behavior has already moved.
For teams ready to audit the AI search gap in their category, Topify’s prompt discovery and AI visibility tracking is the most direct starting point available.
FAQ
Q: Which keyword research tool is most accurate?
A: It depends on what you’re measuring. For Google search data, Ahrefs and Semrush are both highly reliable, with Ahrefs generally considered stronger on backlink and traffic potential accuracy, while Semrush offers more granular keyword segmentation. For AI search data, neither covers the full picture. Topify tracks prompt frequency and brand citations across 7 AI platforms, which traditional tools don’t measure at all. In 2026, “accuracy” has to be defined per channel, not as a single tool verdict.
Q: Free vs paid keyword research tools: when is free actually enough?
A: Free tools work well for two scenarios: optimizing content you already rank for, and validating demand before committing to a new topic. Google Search Console gives you real click and impression data directly from Google’s logs, which is more accurate than any paid scraper for your existing pages. Ubersuggest covers basic discovery with 3 free web searches per day. Where free tools break down is competitive intelligence. You can’t analyze competitor keyword gaps, track ranking changes over time, or access AI search data with free tools alone. For startups and solopreneurs, start free and add a paid tool when you have consistent publishing volume that justifies the investment.
Q: How do I use keyword tools to find content gaps?
A: The most direct path is Ahrefs’ Content Gap feature, which compares the keywords your competitors rank for against your own site and surfaces terms where you have no coverage. Semrush has a similar function under its Keyword Gap tool. For AI search content gaps, the workflow is different: Topify’s Prompt Discovery identifies the specific natural-language prompts where AI platforms are recommending competitors but not your brand. That’s a content gap in the AI layer, and it won’t show up in Ahrefs or Semrush at all.
Q: What are the best keyword research tools for e-commerce brands specifically?
A: E-commerce keyword research has two distinct layers in 2026. For traditional product and category page optimization, Semrush tends to perform well because of its deep PPC data and Shopping ad integration, which helps e-commerce teams align SEO and paid spend. Ahrefs is strong for competitor product page analysis. The layer most e-commerce teams are missing is AI shopping queries: when a user asks ChatGPT or Perplexity “what’s the best [product type] under $100,” traditional keyword tools have no data on how often that prompt fires or which brands get cited. Topify covers that gap with AI Volume Analytics, which is increasingly relevant as product discovery shifts toward conversational AI interfaces.
Read More